Problem
ChatGPT is currently dominating all media airways. As an IT professional, you might wonder what ChatGPT is and how it and other generative pretrained transformers (GPT) work.
Large Language Models (LLM) can run millions and billions of parameters. As you can guess, the technology and resources used for these models are massive. This has also meant that most people, including developers, do not have direct access to the technology, and source codes are kept private by companies like OpenAI and Google. Although secrecy limits knowledge for outsiders, many people believe this is necessary to control the powers of artificial intelligence (AI).
Solution
Sharing knowledge is key to sustaining an equally balanced society overall. Many people hear about AI and immediately put it in the “things I will never understand” folder of their brain. This tip aims to give an understandable take on AI by explaining what LLMs are and how they fuel AI.
ChatGPT and other language generative pre-trained transformers (GPT) do not understand human conversation. Instead, it is powered by a large language model (LLM). GPTs are a type of LLM and a prominent framework for generative AI.
This article aims to show how LLMs work under the hood and explain the mechanisms that govern the processes, from the prompt you input to the output you receive as a response. Additionally, it will cover this technology’s pros, cons, and reality concerning its factual accuracy, legal matters, ethics, etc.
Pre-Training Datasets
LLM is a language model consisting of a neural network with many parameters (typically billions), trained on large unlabeled text datasets using self-supervised or hybrid-supervised learning.
LLMs are pre-trained on large textual datasets with trillions of sentences sourced from online sources such as Wikipedia, books, GitHub, and more.
Scaling Laws
An LLM can generally be defined by at least four variables: compute power, size of the model, size of the training dataset, and parameters that can be up to millions or even billions in number.
In 2020, Open AI announced their LLM scaling laws called the Kaplan scaling laws during the development of ChatGPT-3. These scaling laws stated that 300 billion tokens could be used to train an LLM of size 175 billion parameters, meaning you would need around 1.7 text tokens per parameter.
In 2022, DeepMind found new scaling laws in their Chinchilla paper. The new scaling laws stated that 1.4 trillion tokens should be used to train an LLM of size 70 billion parameters, meaning you would need about 20 text tokens per parameter.
Architecture
Tokenization
Tokens are pieces of words. The word is converted to tokens before a text is passed to be processed. One word can have different tokens depending on how they are structured or placed on the text.
OpenAI and Azure OpenAI uses a subworld tokenization method called "Byte-Pair Encoding (BPE)" for its GPT-based models. BPE is a method that merges the most frequently occurring pairs of characters or bytes into a single token, until a certain number of tokens is reached.
You can use OpenAI's tokenizer to see how tokens are counted using the BPE method.
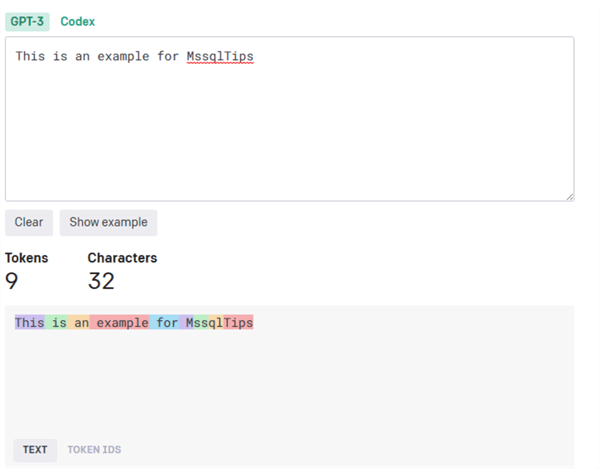
As you can see, frequently used words like “this” and “is” generally count for one token, including the space, while words like “MssqlTips” must be broken into four tokens. Tokenizer is used to map between texts and integers.
To view the associated token integers/ids, click on the “Token IDs” toggle.
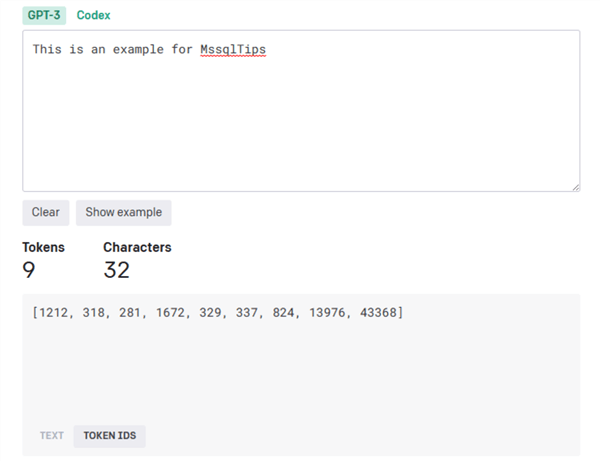
The outputs will also be a list of integers {0,1, 2, …, V-1} where V is the vocabulary size.
Transformers
Transformers are a deep learning architecture that uses the attention mechanism. The attention mechanism is a technique used to copy our human cognitive attention in machines. The attention mechanism allows the model to assign weights of importance to different tokens based on their relevance to the current token being processed.
The transformer model has been adapted by deep learning frameworks like TensorFlow and PyTorch. Here is what the general architecture of Transformers looks like:
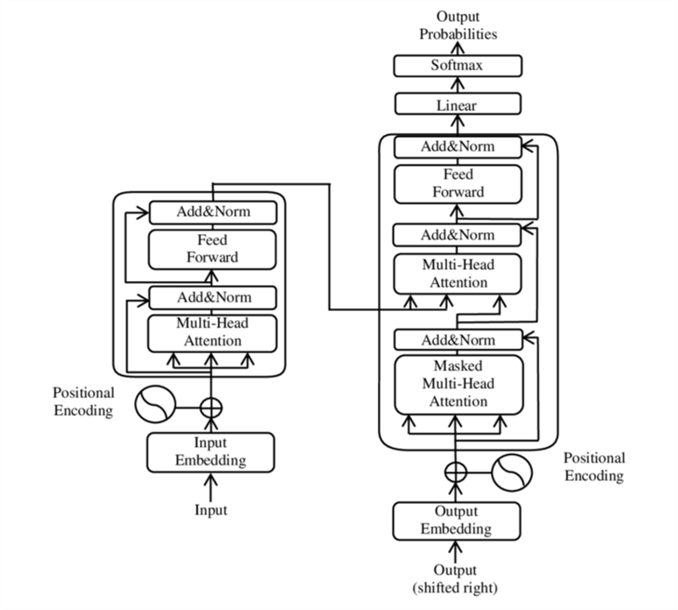
All the tokens can be accessed and assessed at once, then tweaked based on the overall context of the input until they are linear and put through SoftMax.
Training
Pre-Training
LLM can go through different pre-training methods. The popular ones now include:
- Auto-aggressive: Relies on predicting the next word/token. If a phrase like “I like to drive” is passed, the output could be “my car.” This is the type GPT uses, as shown in the ChatGPT example in the previous section. Instead of testing all combinations of possible output tokens to find the best output sequence, we can find an approximate solution with beam search.
- Masked: MLM (masked language modeling) consists of giving BERT a sentence and optimizing the weights inside BERT to output the same sentence on the other side. So, we input a sentence and ask that BERT outputs the same sentence. However, before we give BERT that input sentence, a few tokens are masked/hidden, as shown below:

Training Cost
LLMs are computationally expensive to train. A 2020 study estimated the cost of training a 1.5 billion parameter model (2 orders of magnitude smaller than the state of the art at the time) at $1.6 million. Advances in software and hardware have brought the cost substantially down. To run a small-scale generative AI, you can use OpenAI’s older language models, such as DistilGPT, to avoid unnecessary costs.
For Transformer-based LLM, it costs 6 FLOPs per parameter to train on one token. Note that the training cost is much higher than the inference cost, which costs 1 to 2 FLOPs per parameter to infer on one token. AIimpact says the lowest estimated GFLOPS prices are $0.03-$3/GFLOPS for GPUs and TPUs.
Downstream Tasks
Fine-tuning
Fine-tuning is the practice of modifying an existing pre-trained language model by training it (in a supervised fashion) on a specific task. An example of this is sentiment analysis, which is a form of transfer learning.
Prompting
Prompting is sending a text to the GPT expecting an output. The GPT sees the text you sent (prompt) as a problem and returns the output as a solution. The solution is called a completion. Prompting focuses on the output the GPT gives after pre-training.
GPTs generally use different methods of handling prompting to give an output. There is zero-shot prompting, or when you send a prompt that is not part of the training data to the model, and the model generates a wanted result. This promising technique makes LLMs useful for many tasks.
If you find yourself searching for something you are unsure about, GPTs can use the few shots prompting to automatically fill in the rest of the text from the example you give. Let’s work on an example using ChatGPT:
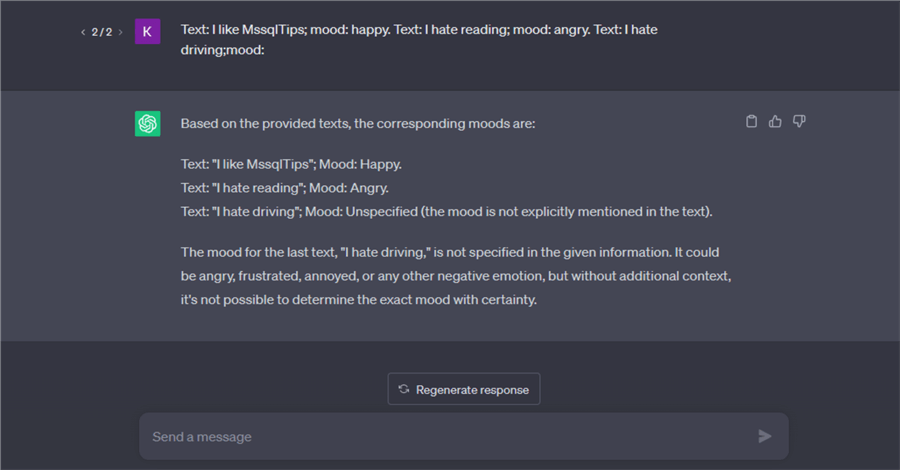
ChatGPT did extremely well on this task. Stating that “I hate driving” is a negative mood but running the same question on Google’s Bart gives out a very different output:
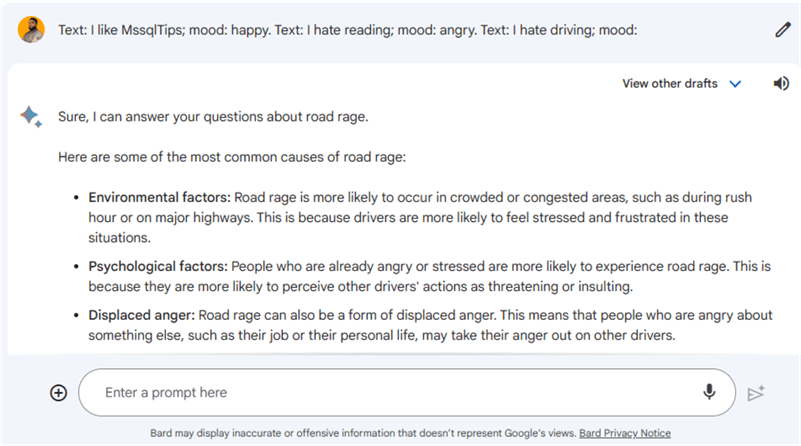
The difference in the outputs showcases how different GPTs handle the prompting, how this is a significant part for the users, and that an entire field of engineering is being built around this topic.
Evaluation
The most used measure of a language model's performance is its perplexity on a given text corpus. Perplexity is a measure of how well a model can predict the contents of a dataset; the higher the likelihood the model assigns to the dataset, the lower the perplexity.
Pros
From an early stage, LLMs have shown to be helpful for the following reasons:
- Advanced Analysis: LLMs have the immersive ability to conduct advanced analysis. This can be helpful in fields where advanced analysis is needed, like how Masked Autoencoder (MAE) has recently been shown to be effective in pre-training Vision Transformers (ViT) for natural image analysis, as stated by this study.
- Productivity: LLMs can increase productivity for most desk work, compared to using Google, which sometimes forces you to go through many links to get an answer. LLMs are good at responding with wholesome and complete answers.
- Flexibility and Control: LLMs can be trained on specific tasks. This can help create focused applications and make it easier to control content users access. For example, an LLM can be trained to produce children’s content only effectively.
Cons
- Logit-bias: LLMs can be preset to give bias by tweaking the probability of certain words or tokens. This bias can be set from –100 to 100, with –100 meaning the token is completely banned and 100 increasing a token’s probability on the output greatly. The fact that this is not out in the open when you engage with an LLM is worrisome.
- Hallucinations: Generative pre-trained transformers can generate new content. This is great news, but unfortunately, even the developers cannot tell precisely how the transformers generate content. This phenomenon is called hallucinations. This can also make the LLM produce false information with, for lack of a better word, confidence.
- Copyright: Since LLMs use a vast, wide range of information, some of this content is not approved for commercial use by the original creators. This causes uncertainty when it comes to copyright issues.
- Updates: The information the LLMs are trained on is generally historical, so some information may be outdated.
Ethics
There is a significant pushback on major research advancements on AI in general. People like Max Tenmark have put forth an open letter to put advanced AI research on pause for the next six months. This letter has already been signed by prominent figures in the tech industry, including the likes of Elon Musk. This is part of the efforts to slow the race of all major players in the industry and give space and time for an open and controlled approach to the technology.
There are certain things we have decided on as a human species to halt for the benefit of everyone. For example, some countries have nuclear capabilities, but seeing how the use of such technologies can threaten our existence or at least the quality of living on a global scale, there is this humanity force or, as it is called in South Africa, “Ubuntu,” which seems to present on every human on earth.
Destruction can also result in massive numbers of people losing their jobs. Not the repetitive tasks type of jobs, but jobs that fill people with a purpose to live and are fulfilling, like judges, teachers, artists, or even developers. The big issue at hand is how we can ensure that the development of AI and LLM systems can continue while guiding.
Legal
When I asked ChatGPT if someone could sue it, this is what it said:

So, any legal issues involving ChatGPT are directed to OpenAI’s legal terms and policies. I doubt the number of people who read through the terms and conditions before using ChatGPT is high.
Overall, the legal issues with GPTs are far from being standardized. GPTs have caused a huge wave of uncertainty in the legal sector. Ironically, there isn’t enough data on real-life cases against GPTs. Recently, there has been a lawsuit against ChatGPT for defamation. This is one of the first lawsuits against a GPT.
Conclusion
Congratulations on coming this far. As these new technologies are set to convenience our lives, we must remember that we created them. Humans are amazing, very capable, and creative. We are still ultimately responsible for double-checking and criticizing any content from these LLMs. As more and more companies and individuals adapt to using the new LLM technologies, as a tech professional, it is your responsibility to keep up to date with the development of these technologies and see how you can incorporate them into your career before you are forced to.
Next Steps
- Learn How can AI make IT more efficient.
- Learn how to apply standard T-SQL coding techniques for AI applications.
- Understanding the Responsibilities of a Successful Data and AI Leader.
- Realizing Business Value through an AI-driven Strategy and Culture.

Levi Masonde is a developer passionate about analyzing large datasets and creating useful information from these data. He is proficient in Python, ReactJS, and Power Platform applications. He is responsible for creating applications and managing databases as well as a lifetime student of programming and enjoys learning new technologies and how to utilize and share what he learns.
- MSSQLTips Awards:
Trendsetter (25+ tips) – 2025 | Author of the Year Contender – 2023 | Rookie of the Year Contender – 2022


