Problem
Microsoft Fabric supports all kinds of different workloads since it’s one data platform for all users. Won’t this be confusing when everyone works in the same space? For example, a Power BI user has totally different needs than a data engineer. How is this going to work?
Solution
Microsoft Fabric is the new all-in-one data platform offering. It’s a Software-as-a-Service platform (SaaS), and you might describe it as a blend of Power BI, Azure Machine Learning, and Azure Synapse Analytics. You can find an introduction to Fabric in the tip called What is Microsoft Fabric? The compute power behind Fabric is either P-SKUs (similar to Power BI Premium) or Azure F-SKUs. The latter can be turned off to save on costs. More information about these capacities can be found in the tip: What are Capacities in Microsoft Fabric?
Since Fabric supports many kinds of workloads, a user can create many different artifacts, such as Power BI datasets, data lakehouses, reports, tables stored in the delta format, pipelines, and so on. Personas were introduced so new Fabric users are not overwhelmed and can clearly distinguish the different roles. With these personas, you get a tailored user experience when working with Fabric. These personas can be found in the bottom left corner (if you cannot see these, it is possible Fabric is not yet enabled in your tenant, or you don’t have permissions to create Fabric objects):

In the screenshot above, the “data engineering persona” is selected. Each persona corresponds with a type of role and workload. If you want to create pipelines, for example, you choose the “Data Factory” persona.
When you first use Fabric by browsing to app.powerbi.com, the Power BI persona is selected by default. This avoids confusion for Power BI users because the user interface is the same as it always has been.
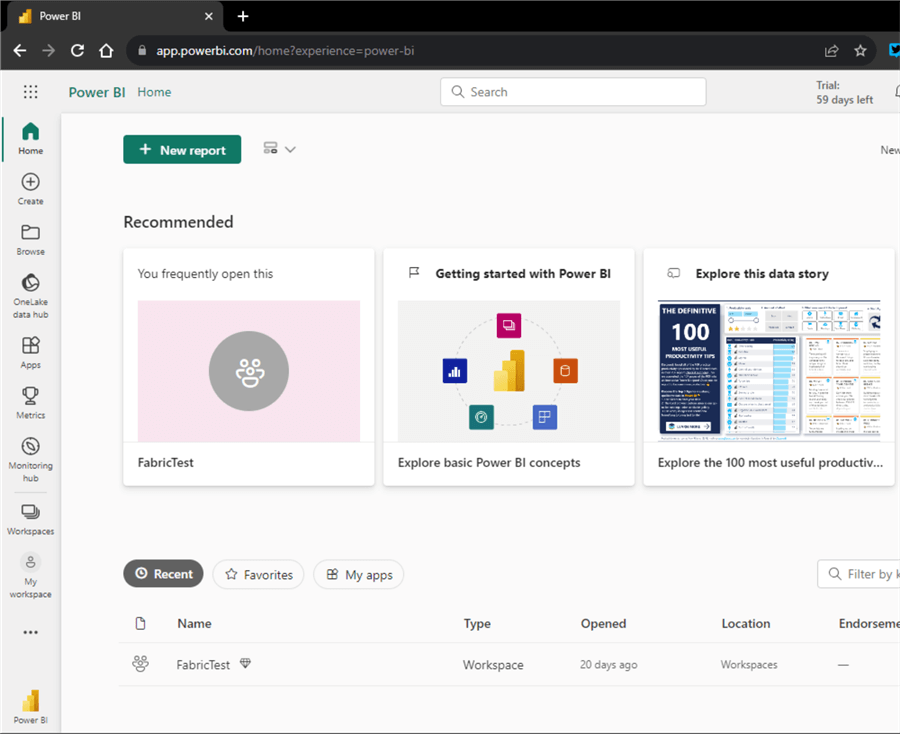
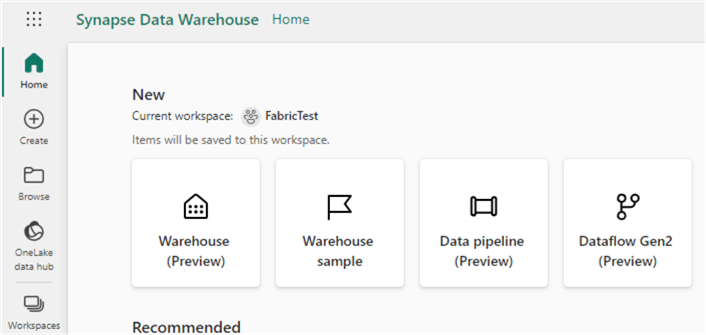
The only “link” to Fabric displayed in this user interface is the OneLake data hub in the left sidebar. If you’re a Power BI user and don’t want to use Fabric right now, no problem; everything is just business as usual. If you want to create other Fabric objects, you may want to use the other personas. When you select another persona, you will get a tailored view (more or fewer icons in the left sidebar), and there will be shortcuts to create artifacts based on the selected persona. For example, when you select the data warehouse persona, the following view will be shown:
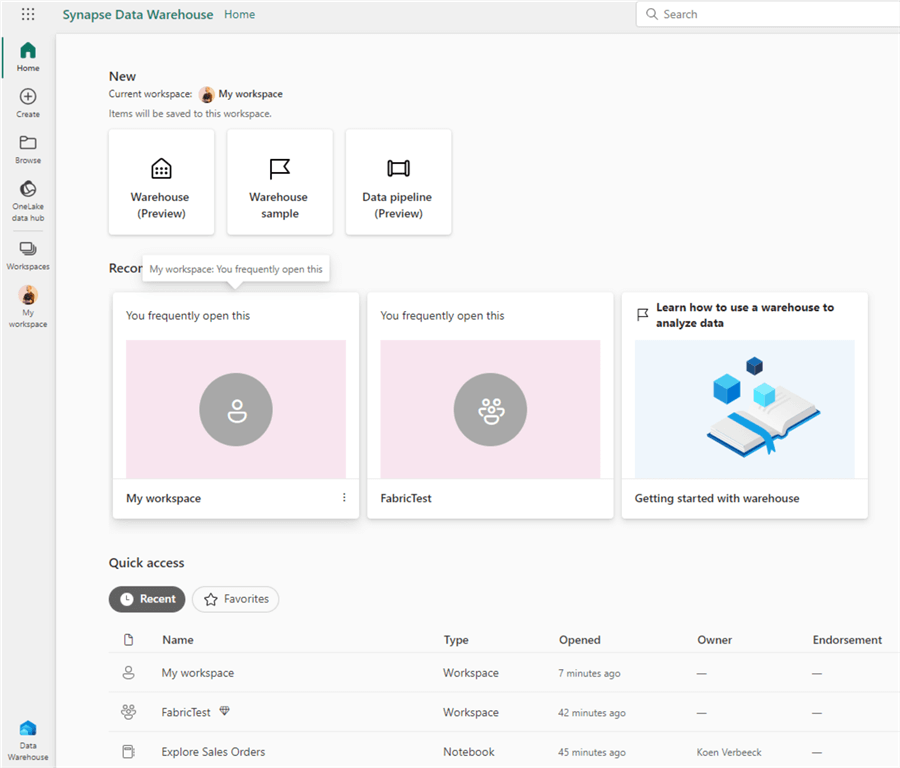
The left sidebar has considerably fewer icons than the Power BI view. At the top, you get shortcuts to create a warehouse or a data pipeline.
The Different Personas in Microsoft Fabric
Currently, there are several personas available.
Power BI
As mentioned, this is the default persona when starting with Microsoft Fabric. You can use this persona to create/view data sets, reports, dashboards, or any other activities available in the Power BI service.
Data Factory
This persona is used when you want to create pipelines to move and transform data. You can create data pipelines (similar to pipelines in Azure Data Factory) or a dataflow Gen2. A dataflow is similar to the Power BI dataflow as it offers the familiar Power Query editor. But the Gen2 dataflow can write to several possible destinations, such as a Fabric Lakehouse, a Fabric warehouse, Azure Data Explorer, or an Azure SQL Database.
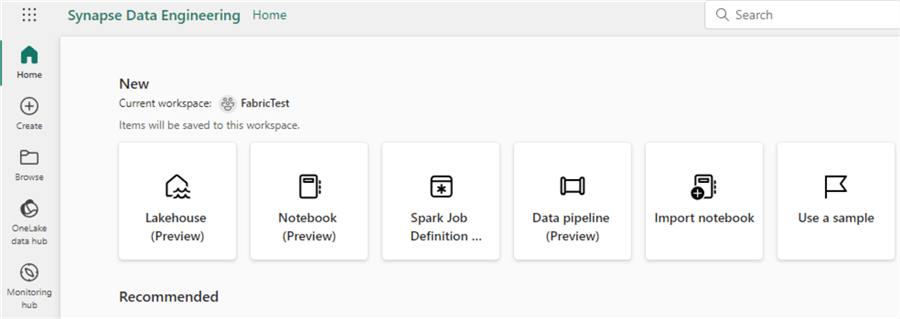
Data Engineering
You can use this persona to create data lakehouses using the Spark technology. Data can be transformed using notebooks, or you can query data using the SQL endpoint of the lakehouse. Notebooks can be scheduled using Spark job definitions.
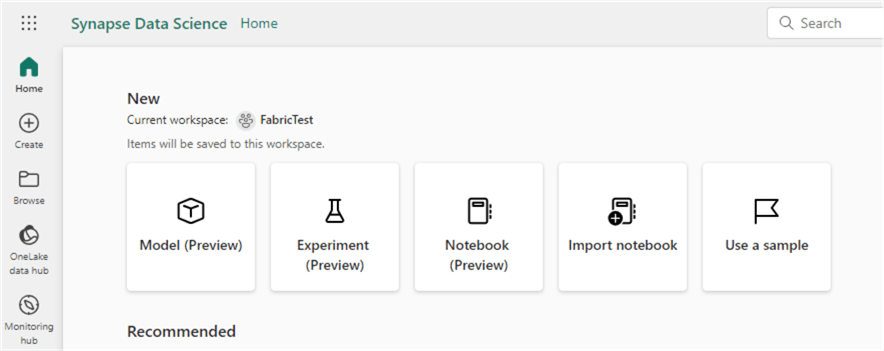
Data Science
With the data science persona, models and experiments can be created like in Azure Machine Learning. But it’s also possible to develop advanced machine-learning models using notebooks.
Data Warehouse
When you want to create a more “classic” data warehouse using SQL, this is the persona for you. However, behind the covers, a relational SQL database is not used because the data is stored in the delta format (in Parquet files). This means that data saved in a data warehouse can be read by a Fabric lakehouse and vice versa. Storage is completely separated from the compute engine, and there’s no distribution of data like in dedicated SQL pools. But, of course, on top, we have the familiar SQL language to query and model the data. The screenshot below shows that the data warehouse is labeled “Synapse Data Warehouse.” However, the Fabric data warehouse differs from the Azure Synapse Analytics data warehouse. It’s like Serverless SQL Pools but more flexible in how data is modeled and stored.
Real-time Analytics
This workload is used when working with IoT, telemetry, log, or other streaming data. This offering is similar to Azure Data Explorer (ADX) or Kusto pools in Synapse Analytics. Data can be queried using the KQL language, also used in Azure Log Analytics. It’s particularly powerful when dealing with time-series data.

Keep in mind personas are just a feature of the Fabric interface. It’s still possible to create objects of another persona while you have selected a specific persona. For example, you can still create a KQL database when you’re using the data warehouse persona. While you’re in a workspace, you can select the New icon. This will display objects you can create, and not only those of the current selected persona are shown:
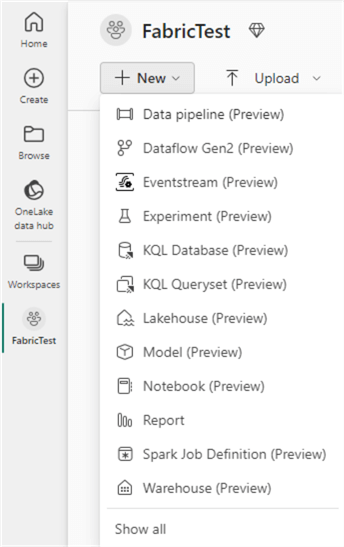
If you click on Show all, you’ll be taken to a landing page where you can see all the Fabric objects that can be created (at the time of writing):

Next Steps
- What is Microsoft Fabric?
- What are Capacities in Microsoft Fabric?
- To learn more about Fabric, check out this learning path.
- Stay tuned for more tips about Microsoft Fabric in the future!

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


