Problem
We have a couple of tables in a Microsoft Fabric Lakehouse, and we’ve noticed that after running the ELT processes for a few weeks, most tables seem to have a lot of Parquet files. The sum of all those file sizes is bigger than the actual table size. Are there ways to clean up some of those files?
Solution
In Part 1 of this tip, we explored table properties or session configurations that can influence the number of files created when a table is loaded, the file sizes of the Parquet files, or the read performance of the table. In this Part 2, we will explain how the OPTIMIZE and VACUUM commands can assist in maintaining the tables in the Lakehouse. To follow along, you will need to have a Fabric-enabled workspace and create a notebook in that workspace.
Restructure Tables with the OPTIMIZE Command
The OPTIMIZE command tries to consolidate multiple smaller Parquet files into fewer, larger files. Reading lots of small files leads to more overhead and reduced performance, while larger files have better data distribution and compression.
Let’s illustrate with an example. The following Spark SQL statement creates a simple table with two columns:
%%sql
CREATE TABLE test_optimize(ID INT, message STRING) USING DELTA;Optimize Write Setting
Before we insert data, we need to make sure optimize write is turned off; otherwise, the Spark engine might auto-compact the data, and the OPTIMIZE command won’t have any effect anymore since the table will already be optimized. With the following statement, we can turn this feature off (don’t forget to turn it back on after testing):
%%sql
SET `spark.microsoft.delta.optimizeWrite.enabled` = false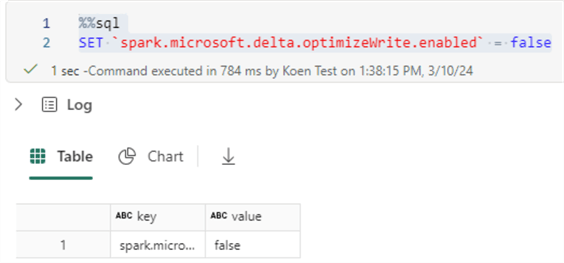
The following script will insert 10 rows in this table:
%%sql
INSERT INTO test_optimize(ID, message)
VALUES (1,'Hello World 1');
INSERT INTO test_optimize(ID, message)
VALUES (2,'Hello World 2');
INSERT INTO test_optimize(ID, message)
VALUES (3,'Hello World 3');
INSERT INTO test_optimize(ID, message)
VALUES (4,'Hello World 4');
INSERT INTO test_optimize(ID, message)
VALUES (5,'Hello World 5');
INSERT INTO test_optimize(ID, message)
VALUES (6,'Hello World 6');
INSERT INTO test_optimize(ID, message)
VALUES (7,'Hello World 7');
INSERT INTO test_optimize(ID, message)
VALUES (8,'Hello World 8');
INSERT INTO test_optimize(ID, message)
VALUES (9,'Hello World 9');
INSERT INTO test_optimize(ID, message)
VALUES (10,'Hello World 10');This takes about a minute to run on an F2 capacity. Don’t use Spark/Fabric for OLTP workloads, folks.
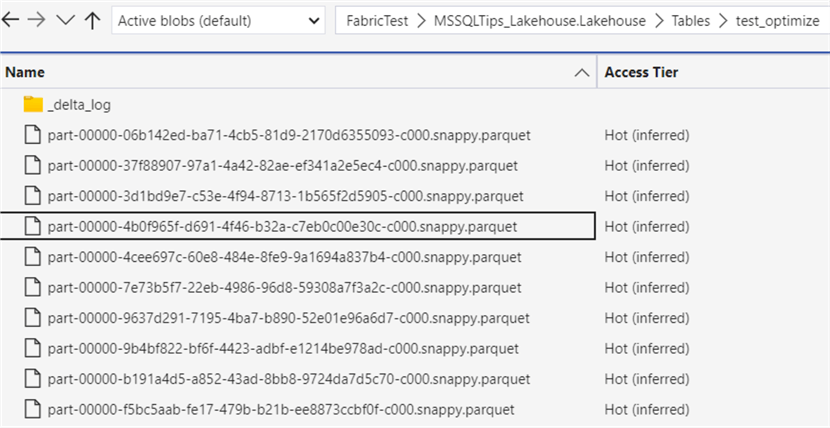
Since every row is inserted in a separate statement (which has its corresponding separate transaction), we get 10 Parquet files in the OneLake file storage:
Options for OPTIMIZE Command
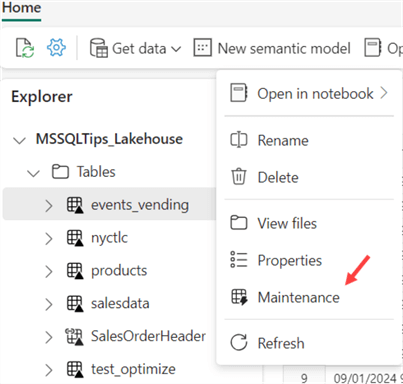
There are two options to run the OPTIMIZE command: either through the user interface or by code. For the first option, we need to go to the actual lakehouse (not the explorer on the left when editing a notebook). Right-click on the table and select Maintenance.
This will open a side pane on the right, with the choice to run an OPTIMIZE command (optionally with V-ORDER enabled, see previous section) and/or the VACUUM command (see next section).

When you click Run now, the maintenance process will run in the background.

Notifications
The OPTIMIZE command can take some time to run and is potentially quite heavy on resources. It took more than a minute to run on an F2 capacity for 10 rows. When the command is finished, you’ll be notified through the notifications window:
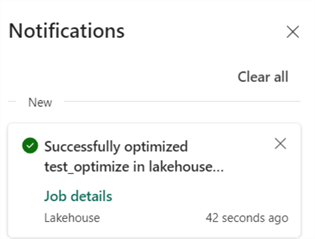
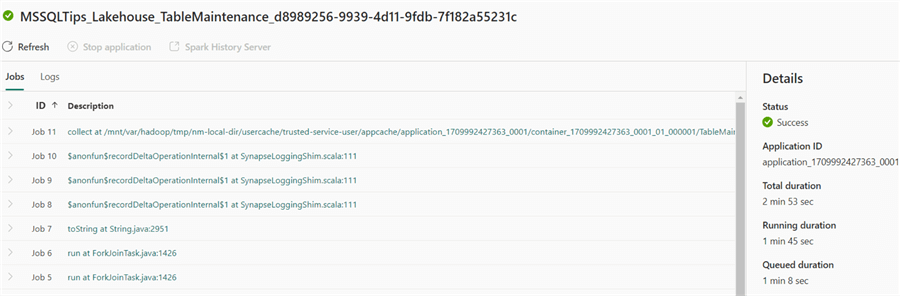
Clicking on Job details will provide more info on the maintenance task. Here, we can see the total job duration was 2 minutes 53 seconds, but 1 minute and 8 seconds were already spent on queuing.
Parquet Files
When we look at the actual Parquet files in OneLake, we can see a file has been added:
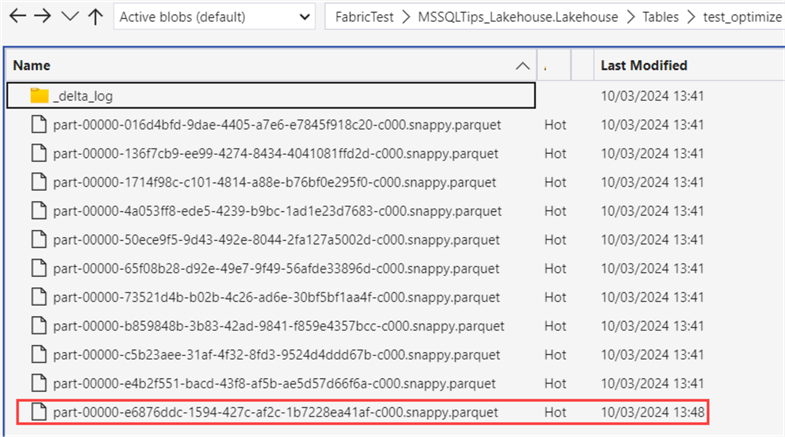
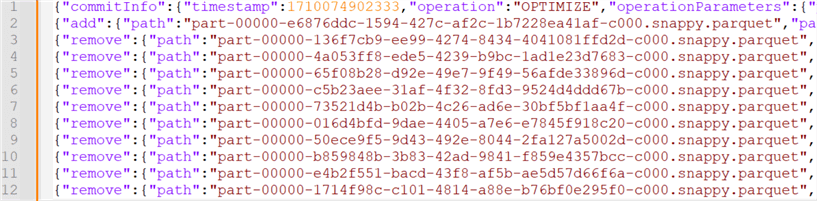
When data files are compacted, the files themselves are not removed. The delta layer needs to keep a transaction log, resulting in the old files being kept around. This enables features like time travel, where you can query the data of a table for a specific point in time. If we inspect the delta log, we find that a JSON file was added at the time of the data compaction:

Interested in why there are checkpoint files in the delta log? Learn more about the checkpointing process in Fabric in the tip, Automatic Table Maintenance in the Microsoft Fabric Warehouse Explained – Part 2.
The contents of the newly added JSON file reveal that all 10 Parquet files were removed and that one single Parquet file has been added to the table:
You can preview a Parquet file in Azure Storage Explorer by right-clicking the file and selecting Preview:
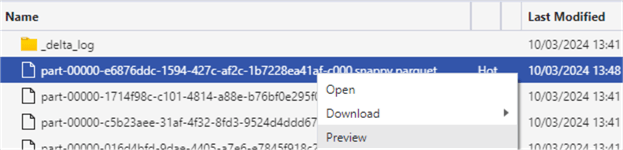
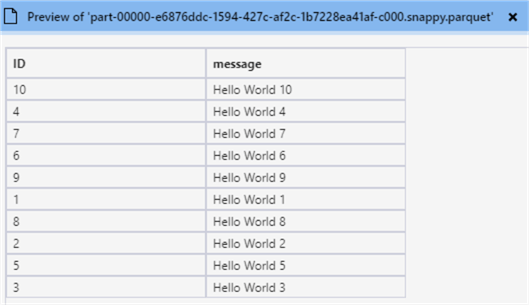
Opening that specific Parquet file shows that, indeed, all data is now in one single file:
If you want to schedule the maintenance or include it as part of a notebook, you can use the OPTIMIZE command (instead of running it manually through the user interface):
%%sql
OPTIMIZE mylakehouse.mytable;For the PySpark fans:
from delta.tables import DeltaTable
delta_table = DeltaTable.forPath(spark, "Tables/mytable")
delta_table.optimize().executeCompaction()The OPTIMIZE command is idempotent, meaning nothing will happen if you execute it a second time. If you have large tables, you can add a predicate to the OPTIMIZE command to optimize only a part of the table since this is a resource-heavy command. However, the predicate needs to be applied to a partitioning column. A statement like this won’t work, for example:
%%sql
OPTIMIZE MSSQLTips_Lakehouse.nyctlc
WHERE YEAR(lpepPickupDatetime)>=2020;
If you want to try out the OPTIMIZE command with a predicate, you can load the sample data from the NY Taxi data set to a partitioned table in the lakehouse (see Automatic Table Maintenance in the Microsoft Fabric Warehouse Explained – Part 1, on how to load sample data). All you have to do is enable partitioning when configuring the data destination and selecting a column from the list:
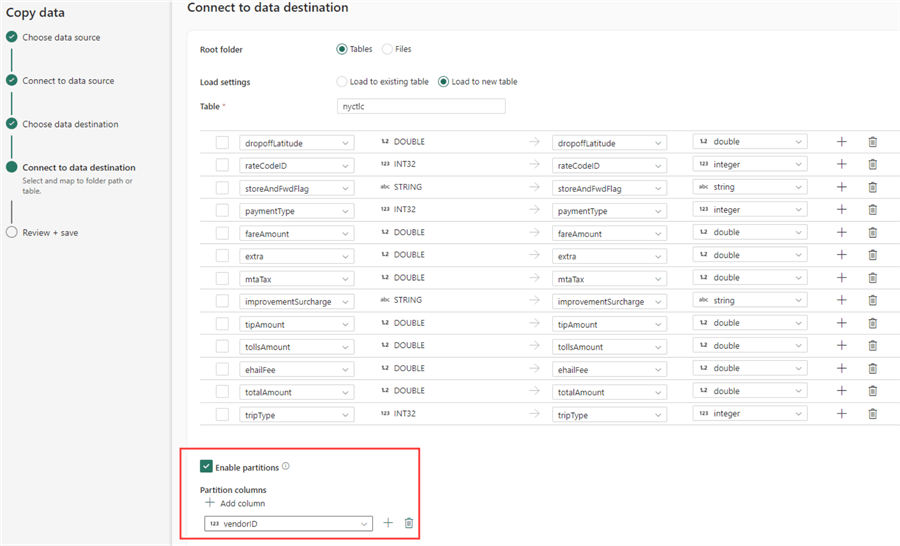
In OneLake, we can see the data is loaded to different folders:
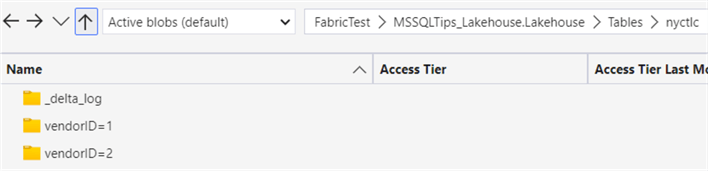
Now, we can run the OPTIMIZE command with a predicate:
%%sql
OPTIMIZE MSSQLTips_Lakehouse.nyctlc
WHERE vendorId = 1;After running the command, a metrics column with JSON data is returned. It will show you what has happened during the optimization, and you can easily detect how many files were added and how many files were removed:
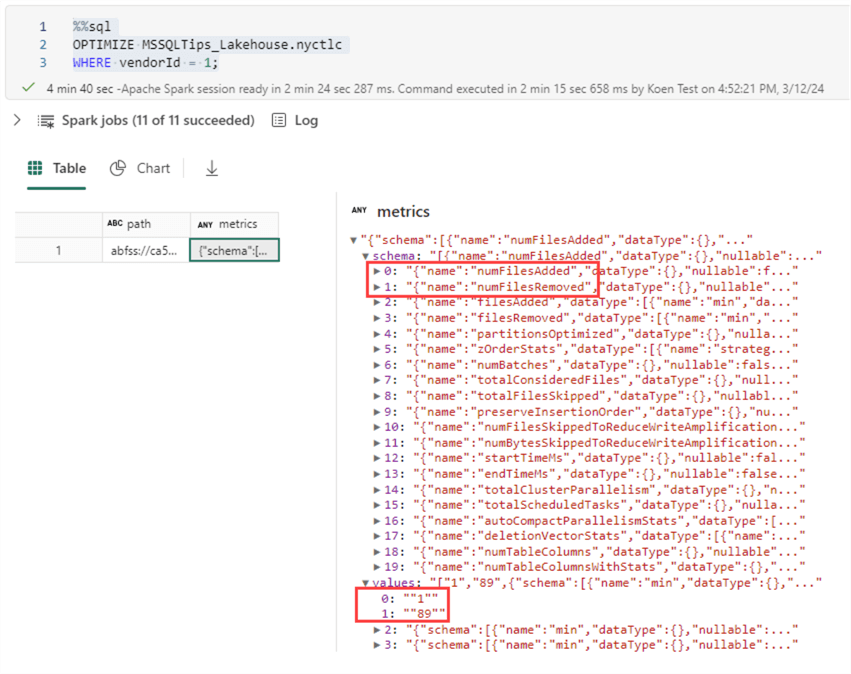
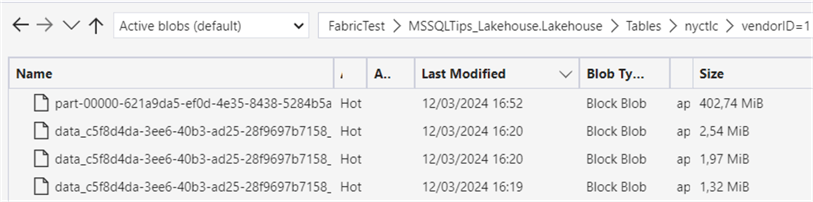
In OneLake, we can see one big file has been added that will replace the other small files:
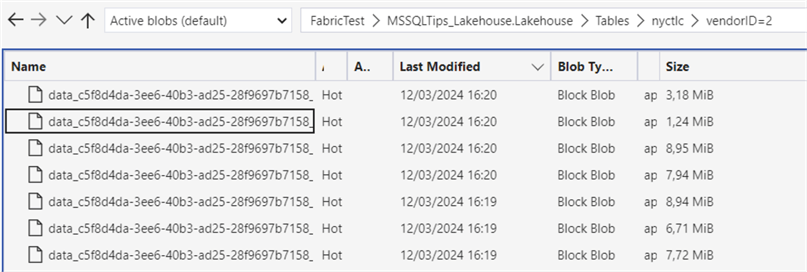
In the folder for vendorId = 2, nothing has changed; all files are still small.
With the OPTIMIZE command, you can also control extra features like V-ORDER (see part 1) or Z-ORDER.
OPTIMIZE mytable; ZORDER BY columnA,column VORDER;More info can be found in the documentation.
Remove Unnecessary Parquet Files with the VACUUM Command
You can imagine that a table can get quite a few updates over its lifetime. With each transaction, one or more Parquet files can be added to the table, and old files from previous transactions are kept around. After some time, the list of files can grow beyond control and incur extra storage costs. Remember our example from the OPTIMIZE command? We loaded data into a table and then optimized the table, resulting in a single Parquet file containing all the data. However, all the old files are still there, meaning the total storage of the table has essentially doubled.
With the VACUUM command, you can remove files that are no longer needed and clean up the storage of your table. Keep in mind that VACUUM can break time travel (up to a certain extent) since you can no longer reference versions of the table that have been deleted. Delta decides which Parquet files to delete based on the retention threshold. The default retention threshold is set to 7 days.
Like OPTIMIZE, we can run the VACUUM command through the user interface. However, the 7-day retention threshold cannot be exceeded.
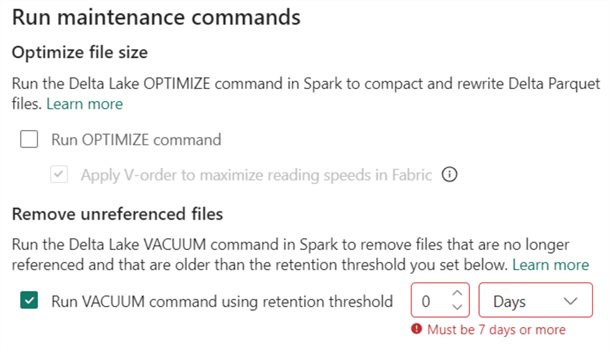
In my case, running this job wouldn’t have any impact since none of the files are older than 7 days when this article was written. However, we can work around this retention threshold using notebooks. With the RETAIN parameter for VACUUM, we can specify how many hours of data retention we want.
%%sql
VACUUM test_optimize RETAIN 1 HOURSHowever, if we run this statement, an error is returned because a requirement has failed:
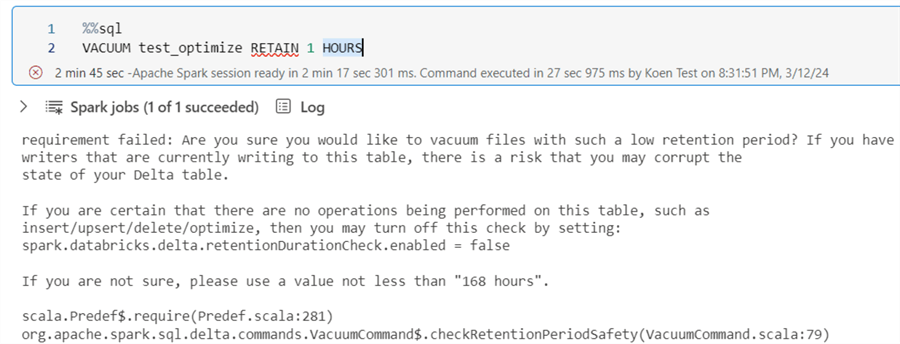
To get below the 7-day threshold, we will need to explicitly tell Spark that this is allowed. We can do this by changing the setting spark.databricks.delta.retentionDurationCheck.enabled to false (yes, that’s right, the setting mentions Databricks, not Microsoft).
%%sql
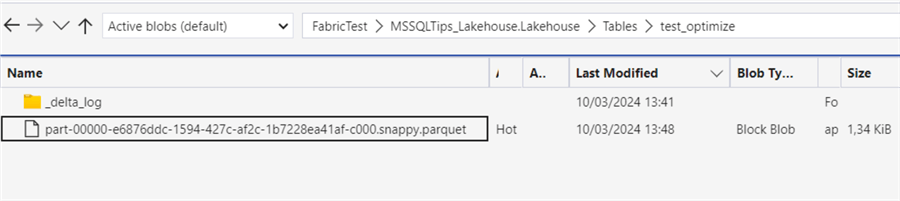
SET `spark.databricks.delta.retentionDurationCheck.enabled` = falseOnce we set it to false, we can run the VACUUM statement again to remove the unreferenced files. The statement ran for about 1 minute on my F2 capacity, and once completed, we can verify in OneLake that the 10 initial files are indeed removed:
In the transaction log, two transactions are added: one for the start of VACUUM and one for the end. Their contents are displayed in the following figure:

Another option is to change the retention threshold of the table itself. We can do this with an ALTER TABLE statement using SET TBLPROPERTIES:
%%sql
ALTER TABLE nyctlc SET TBLPROPERTIES (delta.deletedFileRetentionDuration = 'interval 1 hours');Now, we can run VACUUM without a parameter:
%%sql
VACUUM nyctlc;In the partition for vendorId = 1, we can verify there’s only one Parquet file left:

For demonstration purposes, we have changed the threshold of the tables to a setting below the default of 7 days. On production systems, this is not recommended as you’ll lose time travel on the table, but also because the table can get corrupted if there are writers with long-running transactions on the table (which can lead to uncommitted files being deleted). It’s also a possibility that readers reading time travel data can get unexpected results.
Next Steps
- If you haven’t already, check out part 1 of this tip.
- Learn more about OPTIMIZE and the small file problem: Delta Lake Small File Compaction with OPTIMIZE.
- More Microsoft Fabric tips can be found in this overview.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


