Problem
We are using the Lakehouse in Microsoft Fabric to create tables that will be used later in Power BI. We’ve noticed that sometimes after we’ve run a data pipeline in our notebooks, the number of Parquet files of the delta tables grows out of control, or that performance degrades. Is there table maintenance that we can do?
Solution
Fabric is Microsoft’s new centralized data platform. Currently, there are three types of “databases” (compute services) in Fabric: the lakehouse, the warehouse, and the KQL database. The KQL database uses a proprietary storage format. In contrast, the lakehouse and warehouse use Parquet files with the delta format to store the data in the OneLake storage layer.
The warehouse uses a pure T-SQL approach to managing data; table maintenance is done automatically. You can learn more about this in the following tips: Automatic Table Maintenance in the Microsoft Fabric Warehouse Explained – Part 1 and Part 2. On the other hand, the lakehouse works with notebooks or Spark jobs to manage data (although there is a read-only SQL endpoint). It is up to the developer to manage the maintenance of the tables in a lakehouse.
In this tip, we’ll discuss the various options for ensuring performance doesn’t degrade for your lakehouse tables. Keep in mind that table maintenance applies only to delta tables. It’s possible to create tables in a lakehouse using other formats, such as CSV, but these are not supported for maintenance.
Table Maintenance in the Lakehouse
To manually load sample data into your lakehouse, follow the steps in the tip: What are Lakehouses in Microsoft Fabric? Or, you can load sample data (to a lakehouse instead of a warehouse) from Microsoft using a pipeline, as explained in the tip Automatic Table Maintenance in the Microsoft Fabric Warehouse Explained – Part 1.
Don’t have Fabric yet? You can create a cheap F2 capacity in Azure—which you can turn off to save money—or you can create a workspace in Fabric (https://app.powerbi.com/) that uses a trial capacity (however, this trial capacity won’t be around forever!).
Check the Table Properties
Some table properties are essential for good performance of delta tables and Spark in Microsoft Fabric:
V-Order. An important performance optimization for Parquet files under the Fabric compute engine is V-Order. This is a write-time optimization technique that is learned from years of experience with the Vertipaq engine (used in Power Pivot, Analysis Services Tabular, and Power BI, which are also columnstore databases like Parquet). It applies special sorting, encoding, and compression to achieve about 50% more compression at the cost of some write overhead. Important to note is that V-Order is compatible with the open Parquet format, so any engine that can read Parquet files can read Parquet files with V-Order.
V-Order is enabled by default. It’s also possible to have Parquet files with V-Order and Z-Order at the same time (with Z-Order, you can explicitly specify which columns you want to sort the data on). You can learn more about V-Order from the documentation.
Optimize Write. This table property reduces the number of Parquet files written when a delta table is created and increases the individual file size. This comes with an extra processing cost, but it improves read performance as fewer files must be read and boosts the speeds of the OPTIMIZE and VACUUM commands (more on these in part 2 of this tip). The documentation advises to use this feature only on partitioned tables. It’s enabled by default for (partitioned) tables.
Merge Optimization. A final helpful table property is merge optimization. This property is useful when using the MERGE statement to modify tables. The open-source distribution of delta isn’t fully optimized for handling unmodified rows. With this feature – in preview at the time of writing – an optimization called Low Shuffle Merge is done to exclude unmodified rows from an expensive shuffling operation. Like the other table properties, it is enabled by default, and you can learn more about it here.
You can check if a table property setting is enabled for your configuration by using the SET command:
%%sql SET `spark.microsoft.delta.optimizeWrite.enabled`
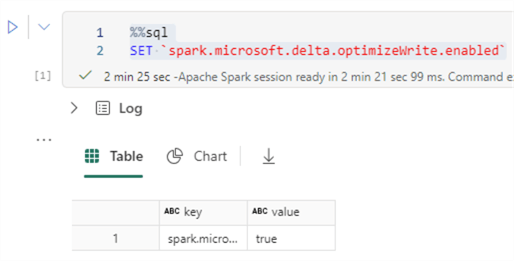
Changing the configuration can also be done by using the SET command:
%%sql SET spark.sql.parquet.vorder.enabled=TRUE
If you want to enable or disable a certain property for a specific table alone, you can use the TBLPROPERTIES:
%%sql
CREATE TABLE test (id INT, value STRING) USING parquet TBLPROPERTIES("delta.parquet.vorder.enabled" = "true");
For an existing table, you can use ALTER TABLE:
%%sql
ALTER TABLE test SET TBLPROPERTIES("delta.parquet.vorder.enabled" = "false");
-- alternative syntax
ALTER TABLE test UNSET TBLPROPERTIES("delta.parquet.vorder.enabled");
Sometimes, it’s not clear if a table is V-Ordered or not. For example, if we run the SHOW TBLPROPERTIES statement, the property is not always included if it was not set explicitly on the table. This can happen if the table has V-Order because of a session configuration.
%%sql SHOW TBLPROPERTIES myTable;
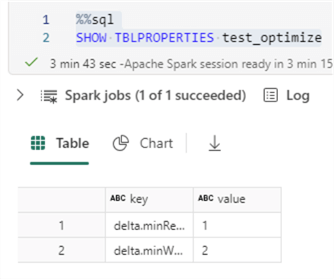
As you can see in the screenshot, only two properties are returned, and they have nothing to do with V-Order. Dennes Torres’ article, Microsoft Fabric: Checking and Fixing Tables V-Order Optimization, explains how you can retrieve the current V-Order configuration for each table in the lakehouse using a PySpark script.
Another interesting property is the max file size for optimize write:
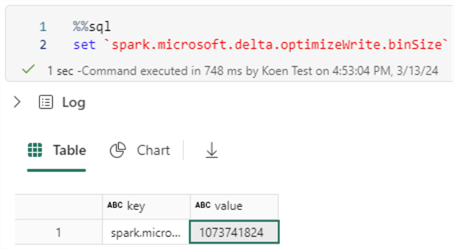
%%sql set `spark.microsoft.delta.optimizeWrite.binSize`
When we retrieve the session configuration, we get the value 1073741824, which is one gibibyte (GiB).
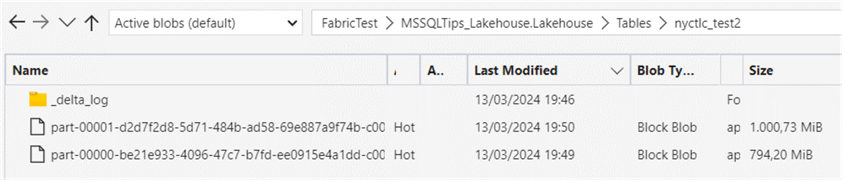
However, when we load sample data to a non-partitioned table with optimize write enabled (using a pipeline as explained in Automatic Table Maintenance in the Microsoft Fabric Warehouse Explained – Part 1), we get file sizes of around 50-60MB. Perhaps there are pipeline settings that influence this result?

When copying the data to another non-partitioned table with optimize write explicitly enabled in the table properties, we get the expected 1 GiB file size:
Next Steps
- Stay tuned for Part 2 of this tip, where we’ll learn more about the OPTIMIZE and VACUUM commands.
- Databricks Performance: Fixing the Small File Problem with Delta Lake is an interesting article about the small file problem in a delta lake.
- You can find an overview of all Fabric tips here.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


