Problem
We’ve been building data warehouses for a long time now, first on SQL Server but lately in Azure Synapse Analytics. We noticed Microsoft has released a new data platform service called Fabric. Can we use Fabric to build our new data warehouse?
Solution
Microsoft Fabric is Microsoft’s new end-to-end unified analytics platform, which integrates several existing technologies. Several types of compute services are available that allow you to transform, enrich, or analyze data. We explored the lakehouse compute offering in the tips What are Lakehouses in Microsoft Fabric? and How to use Notebooks in a Microsoft Fabric Lakehouse? This service uses Spark to run either Notebooks or SQL statements. But Microsoft Fabric also offers the data warehouse compute service, where you can build data warehouses as you’ve always built them, using a familiar SQL interface. However, there are a couple of differences with the “regular” relational database offerings from Microsoft (SQL Server, Azure SQL DB, Azure Synapse Analytics Dedicated SQL Pools):
- The data is saved as Parquet files in the delta table format in the OneLake storage layer. That’s right, just like in the lakehouse. Even better, the warehouse service can read tables from the lakehouse and vice versa. However, those tables are read-only for another service. You cannot, for example, create a table within a lakehouse and then update it with the warehouse service.
- Even though the storage layer uses Parquet files, the warehouse service acts like a full-blown relational database. You have ACID compliance, cross-database querying, autonomous workload management, and transactional isolation. Warehouses support the T-SQL syntax, but not every T-SQL feature is available in Fabric at the moment. For example, Warehouse doesn’t support TRUNCATE TABLE or the IDENTITY constraint (typically used to generate surrogate keys in the dimensions). For a complete list of the current limitations, check out the documentation article, T-SQL surface area in Microsoft Fabric. Hopefully, many of these limitations will be resolved in future updates.
- Azure Synapse Analytics Dedicated SQL Pools don’t exist anymore in Fabric. This service has been rebuilt for Fabric, and some of its concepts are no longer relevant. For example, you no longer need to define a clustering algorithm for your tables. Fabric has been created to be as low-code, Software-as-a-Service (SaaS) as possible, so many of the technicalities needed for Dedicated SQL Pools are no longer required in Fabric.
If you really would like to draw a comparison between Azure Synapse Analytics and Microsoft Fabric, you could argue that the Serverless SQL Pools are like the SQL Endpoint of the Lakehouse in Fabric, while Dedicated SQL Pools are like the Warehouse service. As stated before, there are important differences between all those services, but this comparison might shed some light on how you might want to tackle a migration or a new project.

How to Create Your First Warehouse in Fabric
To follow along, a free trial for Fabric is available. Make sure you have a Fabric-enabled workspace in Power BI/Fabric. To learn more, check out the tip, What are Capacities in Microsoft Fabric?
In the portal, go to the Data Warehouse persona.

Create a new Warehouse. You will be asked to specify a name upon creation.
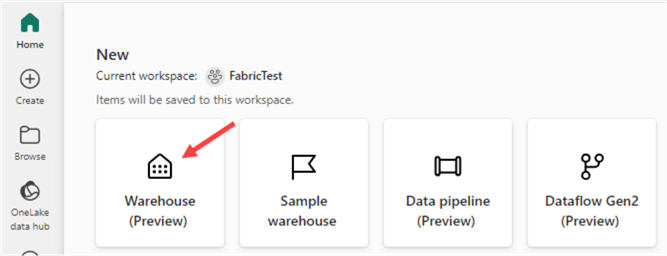
Shortly after, the explorer will load and show options to get data into the warehouse:
We will use a Dataflow Gen2 to load sample data to the warehouse for this demonstration. This is similar to how Power Query works, but now we can specify a destination. We will import data from a sample database in Azure SQL DB. To follow along, more information about how to install this database can be found in the tip, How to Install the AdventureWorks Sample Database in Azure SQL Database.
First, we need to specify the connection credentials to connect to our database.

Then, choose which tables to import from the list:

Let’s choose the SalesLT.Customer and the SalesLT.SalesOrderHeader tables. A Power Query data flow will be created with two queries. Each query imports a single table.
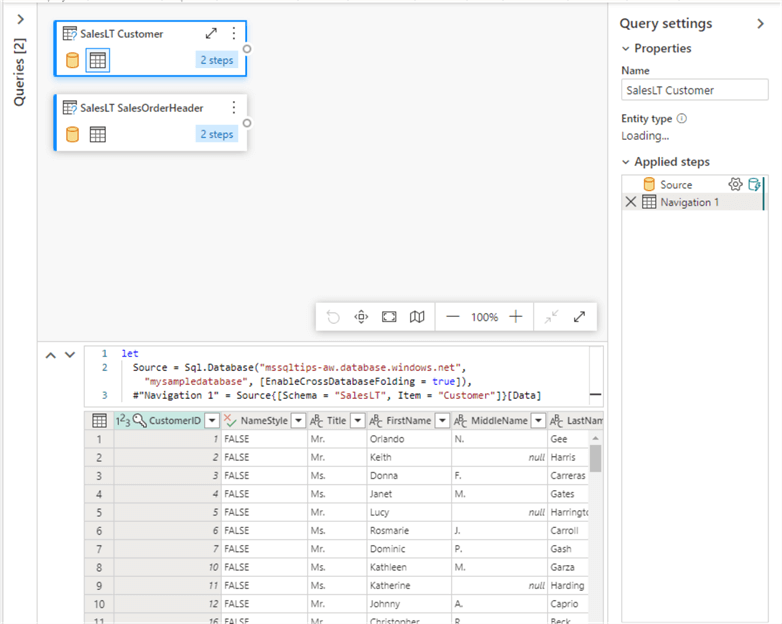
In each query, we’re only keeping a subset of the columns. This can be done with the Choose Column transformation.
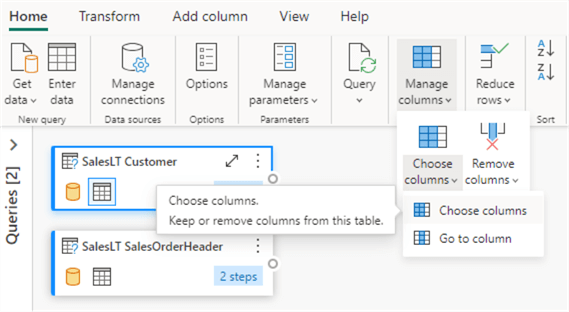
For the customer table, choose the following columns:
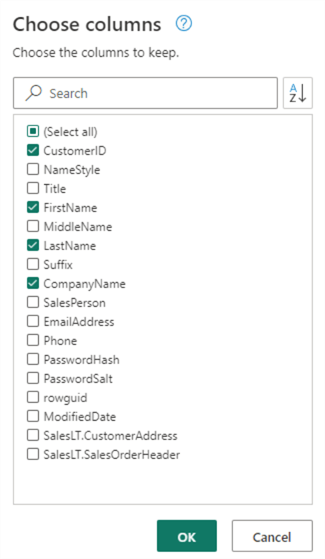
For the SalesOrderHeader table, choose the following columns:
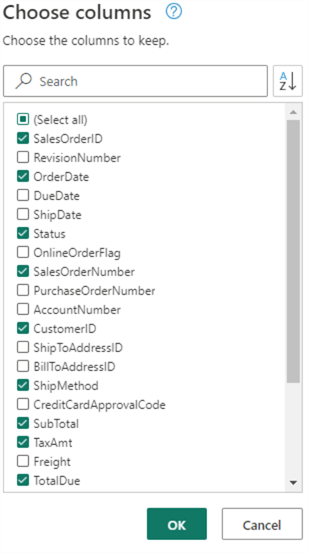
In the Visual Editor, a step has been added for each query:
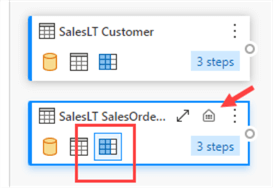
Also, notice the little data warehouse icon, which means the query will write the data to a table in the data warehouse. In other words, the destination is already set, and you cannot choose it anymore from the menu as it will be greyed out:

It is possible to edit the destination connection by clicking the data warehouse icon:

First, choose a connection (we can leave this to default):
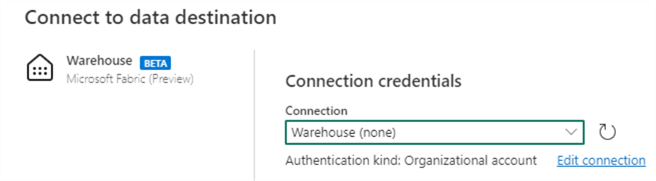
Then, pick the specific data warehouse we want to load the data to:
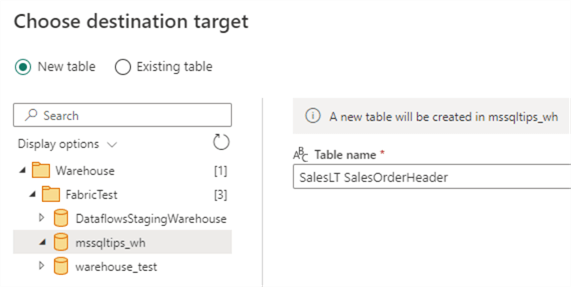
Here, we can also change the name of the destination table and if we want to load it to an existing table or a new one.
On the next screen, choose the loading method: append the data or replace existing data.
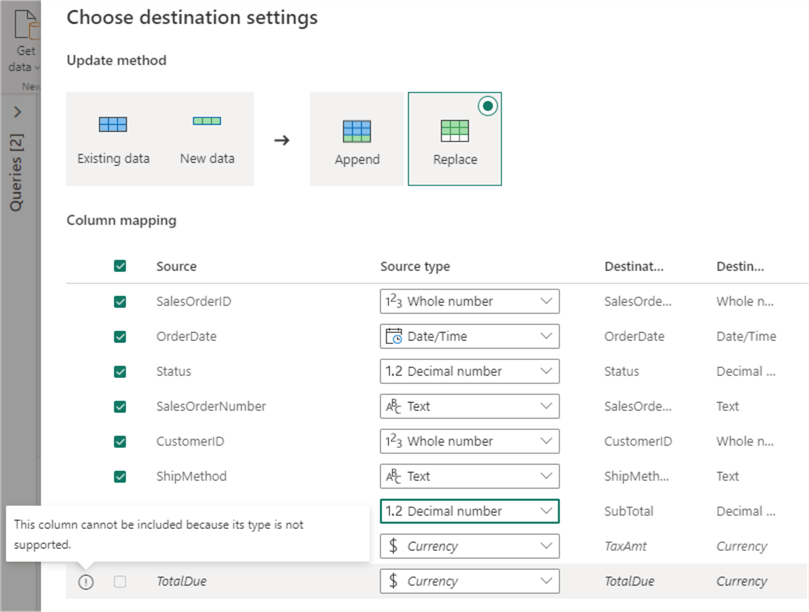
We also need to configure the column mapping. As indicated in the screenshot, there might be issues with data type conversion. In this case, the destination doesn’t support the currency data type, so we need to adjust it to a decimal number. When the settings are saved, we can see an additional data type conversion step is added to the query:
When the flow is configured, we can publish it using the button in the bottom right corner.

In the workspace, we can see that the publishing and refreshing of the data is in progress.

When we go back to the data warehouse, we can see the two tables have been added (it’s possible you need to refresh the table list first):

If you don’t see the data preview of a table, make sure the Data tab is selected in the bottom left corner. When we view the properties of a table, we can see it’s not a typical SQL Server table but rather a table in the Delta format.
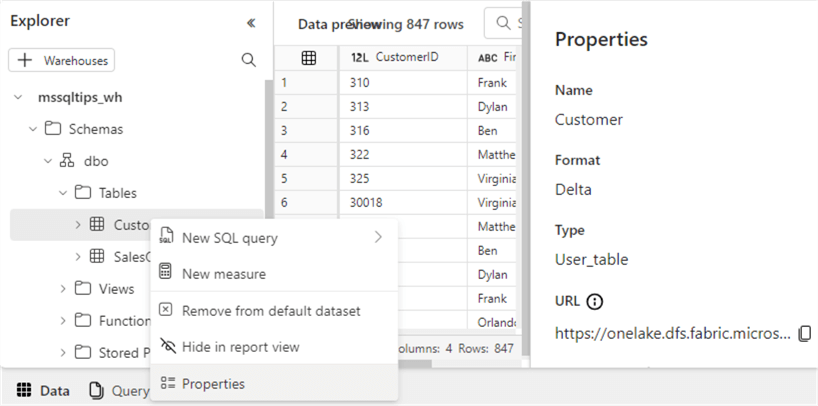
Of course, we can execute SQL queries against the tables like in a relational database:
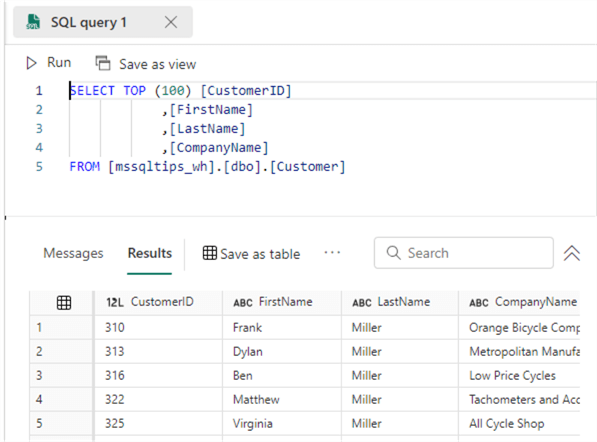
When typing, we also get IntelliSense and autocomplete.

We can also run DML statements such as the UPDATE statement:

In the Model view, we can see the tables are automatically added. Here, we can build a Power BI data set similar to Power BI Desktop. We need to add a relationship between the customer and the sales order header:
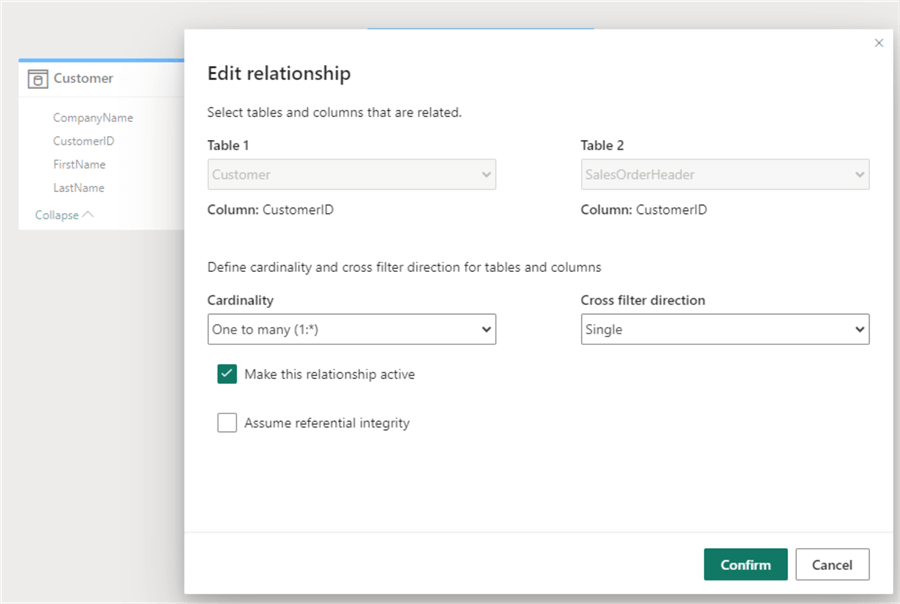
Make sure to choose the correct cardinality. When the model is finished, you can click New Report to create a new Power BI report:
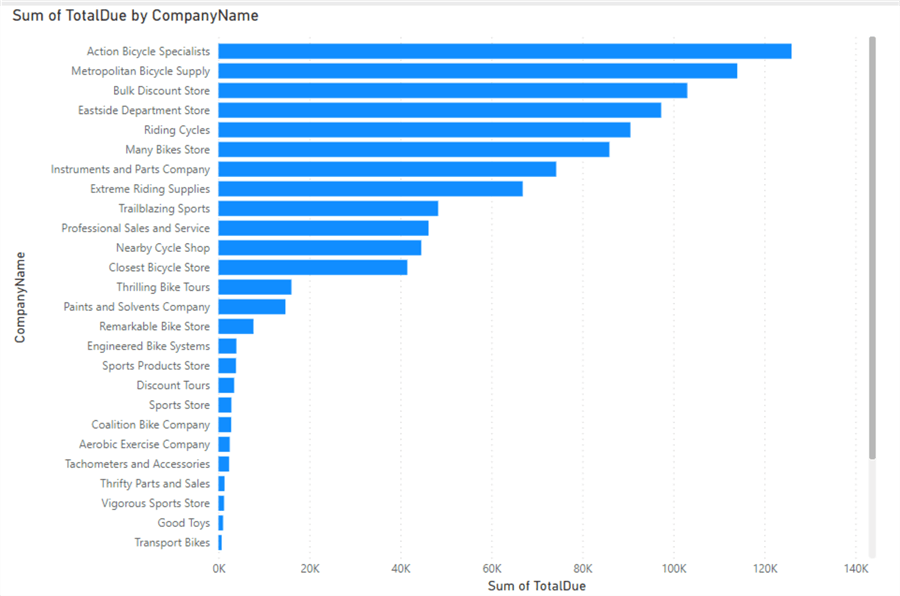
It’s possible that you need to set the default aggregation of the TotalDue column from None to Sum to make this chart work.
Conclusion
In this tip, we introduced the Warehouse service in Microsoft Fabric. It allows you to easily import data into tables (which are Parquet files in Delta format stored in the OneLake data lake), write SQL queries on those tables, and model directly into a Power BI dataset. We only scratched the surface here. In real-life use cases, more modeling would be required to create a data warehouse with a star schema. Keep in mind that, for the moment, surrogate keys using identity columns are not supported. An alternative might be to use hash keys.
Next Steps
- To learn more about Fabric, check out this overview.
- The list of current limitations of T-SQL in the Fabric Warehouse.
- The official documentation about data warehousing in Microsoft Fabric.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025



Hi,
I certainly wouldn’t normalize too much in the warehouse. As usual, you want to avoid too many joins.
So definitely denormalize, maybe into one big table if performance is really suffering. Keep in mind though that having everything in one single table will have issues of its own, such as more complicated DAX in Power BI.
Hi Koen!
Tables in a data warehouse are typically denormalized. What about Microsoft Fabric warehouses?
Thanks!