Problem
In a previous tip on Install SQL Server 2008 on a Windows Server 2008 Cluster Part 1, we have seen how to install and configure a SQL Server 2008 on a Windows Server 2008 Failover Cluster. We now have a new requirement to deploy a SQL Server 2012 instance on a multi-subnet cluster that spans different geographical locations. How do I install and configure a SQL Server 2012 on a multi-subnet cluster?
Solution
Setting up a SQL Server multi-subnet cluster has become a much talked about topic ever since Windows Server 2008 came out. This is because Windows Server 2008 failover clusters support nodes that are in different subnets. However, SQL Server 2008 R2 still does not support a multi-subnet cluster. You have to implement a stretched virtual local area network (VLAN) in order to span SQL Server failover clusters across different geographical locations. One major challenge here is the network configuration. Most of us SQL Server DBAs do not have control over implementing network topologies as part of the implementation of a SQL Server failover cluster. In most cases, the network topology has already been implemented and managed by the network engineers. Because of its complexity, implementing and managing a dedicated VLAN just for database servers would be yet another reason for network engineers and DBAs to not get along well.
SQL Server 2012 is the first version of SQL Server that natively supports multi-subnet clusters, thus, eliminating the need for a stretched VLAN. This allows SQL Server DBAs to implement multi-subnet clusters within the same data center for high availability but also across data centers for disaster recovery purposes. As SQL Server depends so much on the Windows Failover Cluster infrastructure, it is important to get it working properly prior to installing SQL Server 2012. The goal of this series of tips is to prepare the SQL Server DBA in planning and implementing a multi-subnet SQL Server 2012 failover cluster instance.
NOTE: The installation and configuration process outlined below needs to be done on all of the nodes in the SQL Server 2012 Failover Cluster unless otherwise specified.
Design Your Network Architecture
Proper network architecture design is key to successfully implementing a multi-subnet SQL Server 2012 failover cluster instance. You need to enlist the help of your network engineers to make sure that your design complies with your corporate standards and done appropriately (this is also the perfect time to build good rapport with your network engineers.) Below is the network diagram that I will use to implement my multi-subnet SQL Server 2012 failover cluster.

In the diagram above, I have two domain controllers – DC1 and DC2 – in the same Active Directory domain. It is required that all servers acting as nodes in a failover cluster reside in the same Active Directory domain, whether they are in the same subnet or not. In my environment, the domain controllers are in different network subnets, each on a dedicated Active Directory site and being replicated on a regular basis. Cluster nodes SQLCLUSTER1 and SQLCLUSTER2 have three network adapters – one for production traffic, one for heartbeat communication and one for the iSCSI storage. I am using a product called StarWind iSCSI SAN for my clustered storage as it provides storage-level replication or what they call data mirroring. Technically, there is no shared storage in a multi-subnet cluster because each node will have its own storage subsystem. However, the storage subsystem used by one node is an exact replica of the storage subsystem being used by the other nodes. Talk to your storage vendors regarding support for storage replication for use in a multi-subnet failover cluster. In my environment, storage system SAN1 is being replicated over to SAN2 via a TCP/IP connection. A breakdown of the servers, storage systems and IP addresses is shown in the table below.
| Hostname | IP Address | Purpose |
| DC1 | 172.16.0.100 | Domain Controller/DNS Server |
| DC2 | 192.168.0.100 | Domain Controller/DNS Server |
| SQLCLUSTER1 | 172.16.0.111 | Cluster Node 1 – public traffic |
| 197.160.0.111 | Heartbeat communication | |
| 10.0.0.111 | iSCSI communication to SAN1 | |
| SQLCLUSTER2 | 192.168.0.111 | Cluster Node 2 – public traffic |
| 197.160.1.111 | Heartbeat communication | |
| 10.0.1.111 | iSCSI communication to SAN2 | |
| SAN1 | 10.0.0.100 | iSCSI communication to SQLCLUSTER1/Replication traffic to SAN2 |
| SAN2 | 10.0.1.100 | iSCSI communication to SQLCLUSTER2/Replication traffic to SAN1 |
Carve Out Your Disks
Similar to the previous tip, you need to provision your clustered storage depending on your requirement. Since this involves configuration of replicated storage, enlist the assistance of your storage vendors and engineers to configure this properly. If you are only installing the database engine, you do not need to have the MS DTC clustered resource configured, thus, saving you a clustered disk allocation. At a minimum, make sure you have at least 3 clustered volumes for SQL Server’s use – one for the system databases, one for the data files and one for the log files. You might be wondering why I didn’t specify a quorum disk for this configuration unlike in the previous tip. I will talk about it in detail when we get to the section on Configuring the Cluster Quorum Settings.
Present your disks to the cluster nodes
Note that I didn’t say “shared disks.” That is because, technically, the storage subsystems are not shared by the cluster nodes as I’ve previously mentioned. This can be confirmed as part of the clustered disk configuration. The process of connecting the servers to the iSCSI storage is the same as in the previous tip with few things to consider.
- In the Discovery tab of the iSCSI Initiator Properties page, the IP address of the target portal will be different on each cluster node. In the screenshot below, the IP address of the target portal for SQLCLUSTER1 is 10.0.0.100 while the IP address of the target portal for SQLCLUSTER2 is 10.0.1.100, confirming that the cluster nodes indeed do not share the same storage subsystems.

- Multi-path I/O needs to be enabled on all of the cluster nodes. This is to allow the use of iSCSI drives with MPIO for redundancy and fault tolerance. To enable multi-path I/O, it has to be added using the Add Features Wizard.
- Open the Server Manager console and select Features.
- Click the Add Features link. This will run the Add Features Wizard

- In the Select Features dialog box, select the Multipath I/O checkbox and click Next (and while you’re at it, you can include the .NET Framework 3.5.1 Features and the Failover Clustering feature since these will be used by the SQL Server 2012 failover cluster installation).

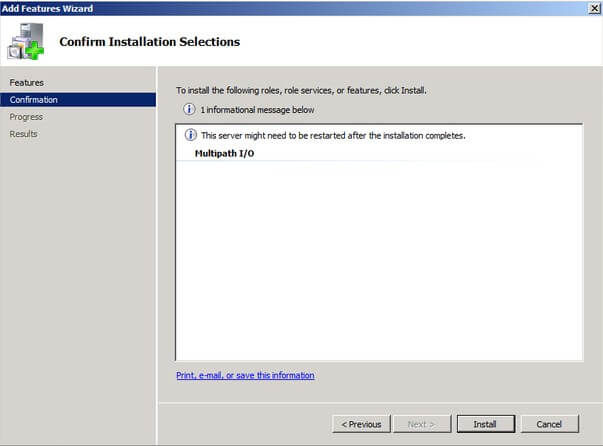
- In the Confirm Installation Selections dialog box, click Install to confirm the selection and proceed to do the installation of the Multipath I/O feature.
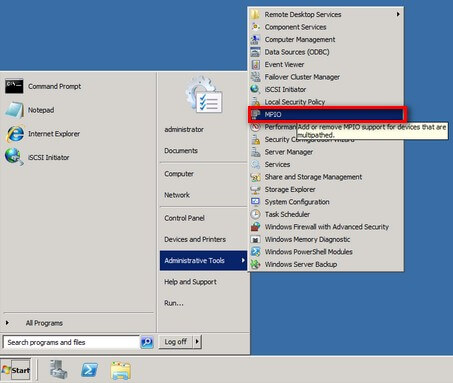
- Once the installation is complete, open the Administrative Tools and select MPIO.
- In the MPIO Properties page, select the Discover Multi-Paths tab and click the check box for Add support for iSCSI devices. Click the Add button. This will prompt you to reboot the server.

Once the cluster nodes have been rebooted, we can now proceed to configure the disks.
Initialize And Format The Disks
I wanted to go thru the disk initialization process even though it is something that most Windows administrators already know. This is because it is a great way to validate whether or not the storage replication process works as per your vendor specification. Disk configuration changes made on one of the cluster nodes should be replicated over to the other nodes within your cluster.
Any new disks added on a Windows Server 2008 system has to first be brought online and initialized before any partitions can be created on it. This can be done via the Disk Management console from within Server Manager.
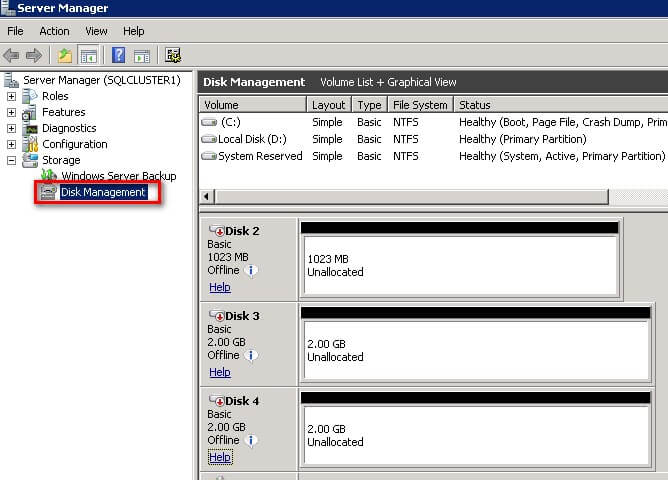
- From within Server Manager, expand the Storage section and select Disk Management.
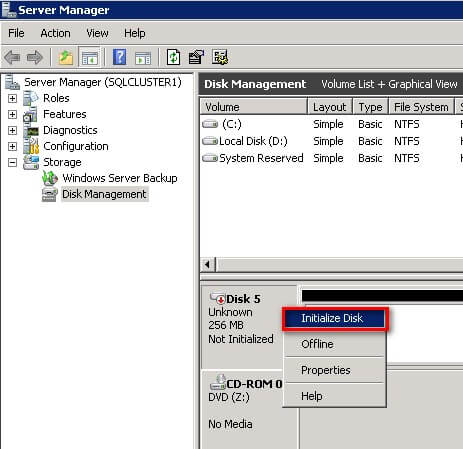
- Right-click any of the disks that you want to configure and select Online. Once the disk is brought online, it is now marked as Not Initialized.

- To initialize, right-click on the disk and select Initialize Disk. The Initialize Disk dialog box will appear.
- In the Initialize Disk dialog box, make sure that the correct disk is selected for initialization and then choose whether to initialize the disk using the MBR or GPT partition styles. The most common partition style for disks used in SQL Server instances is MBR, which is selected by default. Click OK to select the MBR partition style.

- To create a disk partition, right-click on the unallocated space and select New Simple Volume.

- In the Welcome to the New Simple Volume Wizard dialog box, click Next.

- In the Specify Volume Size dialog box, enter the volume size and click Next.
- In the Assign Drive Letter or Path dialog box, specify the drive letter you would like to use and click Next.

- In the Format Partition dialog box,
- Make sure that the file system selected is NTFS.
- To follow Microsoft best practices on allocation unit size, select 64K.
- In the Volume label: text box, enter the appropriate name. In my example, I used M_Cluster_Drive. Take note of this volume label because we will use this to verify the configuration on the other cluster node.
Click Next

- In the Completing the New Simple Volume Wizard dialog box, review the settings you have made and click Finish.
Repeat these steps on all of the disks that you want to configure as part of your cluster.
Verify The Storage Replication Process
As I’ve mentioned in the previous section, the only reason why I walked thru the process of bringing the disk online to formatting a partition is because we wanted to verify if the storage replication process works as per your vendor specification. In order to verify this process, simply bring all of the disks on the other cluster nodes online. If the storage replication works, you will see that the volume name we have assigned has been propagated on all of the cluster nodes. In my example, I have named my clustered disks M_Cluster_Drive, L_Cluster_Drive and S_Cluster_Drive on SQLCLUSTER1. After bringing the disks online, the same volume properties have appeared on SQLCLUSTER2. The drive letters were not the same, though, but we will be removing them since we will define the drive letters from within the Windows Failover Cluster.

There are other ways to verify the storage replication process as this is totally dependent on the features of your storage platform. This is just a simple way to verify if it indeed works as expected. Work with your storage vendors and engineers to make sure that this verification step has been done and that all potential issues have been addressed prior to moving to the next step. It will be more difficult to troubleshoot and address issues down the road as more components are added to the stack.
Next Steps
- Review the previous tips on Install SQL Server 2008 on a Windows Server 2008 Cluster Part 1, Part 2, Part 3 and Part 4.
- Download and install an Evaluation copy of Windows Server 2008 R2 for this tip.
- Start working on building your test environment in preparation for setting up a SQL Server 2012 multi-subnet cluster on Windows Server 2008 R2. This is a great opportunity to learn more about networking concepts and fundamentals as a SQL Server DBA.

Edwin M. Sarmiento is the Managing Director of 15C, a consulting and training company that specializes on designing, implementing and supporting SQL Server infrastructures. He is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures running on the Microsoft server technology stack ranging from Active Directory to SharePoint and anything in between. He is very passionate about technology but has interests in music, professional and organizational development, and leadership and management matters when not working with databases. Edwin lives up to his primary mission statement: “To help people and organizations grow and develop their full potential.”
- MSSQLTips Awards: Champion Award (100+ tips) – 2017 | Author of the Year Contender – 2020, 2017
