By: Derek Colley | Comments (16) | Related: > Disaster Recovery
Problem
Corrupt SQL Server databases are the worst nightmare of any SQL Server professional. In any environment, from small business to enterprise, the compromise of integrity and availability of the data can constitute a business emergency. This is especially the case in those organizations reliant on an OLTP data model, for a high-volume website. SQL Server database corruption and disruption of the transaction processing system can cause business repercussions such as large financial losses, a drop in reputation or customer retention, or contractual SLA problems with the service provider, if not managed in-house. This tip will demonstrate the diagnosis process, discuss one method of correcting page-level corruption without using the REPAIR options with the DBCC CHECKDB command and outline how to get the SQL Server back online.
Solution
Diagnosis - SQL Server Corruption
Normally any business will have contingency plans to deal with SQL Server database corruption scenarios, and any good database professional will have immediately thought of a number of strategies to deal with these. Items such as disaster recovery plans, replication, Database Mirroring\AlwaysOn, Clustering, etc. However, sometimes these options are not appropriate. Imagine you have a 20GB database populated with records of your customers and records of each transaction linked back to your customers. You have two .mdf data files. You are using the full recovery model, full backups are taken daily at 21:00 with transaction log backups taken every 15 minutes. You don't use mirroring, replication or clustering, instead of relying on a robust backup model to protect your data. At 20:00, a message like this occurs:
Msg 824, Level 24, State 2, Line 1 SQL Server detected a logical consistency-based I/O error: unable to decrypt page
due to missing DEK. It occurred during a read of page (3:0) in database ID 10 at
offset 0000000000000000 in file 'c:\del\corruption_secondary.mdf'. Additional
messages in the SQL Server error log or system event log may provide more detail.
This is a severe error condition that threatens database integrity and must be
corrected immediately. Complete a full database consistency check (DBCC CHECKDB).
This error can be caused by many factors; for more information, see SQL Server
Books Online.
It is clear that the SQL Server database integrity has been compromised. As this sample error reports, there's a problem in the 'corruption_secondary.mdf' file (my second data file in this test database) at page 3:0, offset 000..000 (right at the beginning). So what do you do? The first instinct is to think, 'Restore! Restore! Restore!' But in this scenario, this will involve the following steps as a minimum:
- Set database in single-user mode
- Tail log backup of all transactions since last transaction log backup
- Full restore of backup from today - 1
- Restore of 4 transaction logs per hour multiplied by 23 hours = 92 individual logs
- Restore of tail log up to the point of corruption (point in time recovery)
- DBCC check of the database
- Set database online
But wait - there's two things to consider. One, what's your recovery time objective (RTO)? Is it, let's say, four hours? Are you sure you can perform 93 individual backups in four hours, over 20GB of data? What if you're using SATA drives - IOPS constraints will make this a close-run race. What about configuration of the script to do this? What happens if one of those logs is also corrupt? And what happens if the corruption pre-dates the error message (i.e. the error message wasn't a direct response to a very recent event, like disk failure) but instead has festered inside your database? What if (horror of horrors)... the full backups include this corrupted data?
DBCC CHECKDB
Fortunately, there's a few ways to identify corruption in the database. The first, and the most well-known, is DBCC CHECKDB. This utility will perform systematic data integrity checks throughout the datafiles and identify areas of concern. As documented in other excellent articles, this comes with three main options for recovery: REPAIR_ALLOW_DATA_LOSS, REPAIR_FAST and REPAIR_REBUILD. These options are not ideal, especially REPAIR_ALLOW_DATA_LOSS, although it is perfectly possible to restore without data loss using these tools. This article is not going to demonstrate the use of CHECKDB, rather it will demonstrate a different method. Here's the warning about CHECKDB repairs from Books Online:
"Use the REPAIR options only as a last resort. To repair errors, we recommend restoring from a backup. Repair operations do not consider any of the constraints that may exist on or between tables. If the specified table is involved in one or more constraints, we recommend running DBCC CHECKCONSTRAINTS after a repair operation. If you must use REPAIR, run DBCC CHECKDB without a repair option to find the repair level to use. If you use the REPAIR_ALLOW_DATA_LOSS level, we recommend that you back up the database before you run DBCC CHECKDB with this option." -- http://msdn.microsoft.com/en-gb/library/ms176064.aspx
There are other ways of dealing with corruption, including the direct edit of database files in a suitable hex or text editor, and this is the method I'm going to use to demonstrate that it's possible to repair a corrupt data file with direct 'open-heart' surgery. However, you will need access to one copy of the database, whether that's from your QA/Test/dev stack or a restored copy of an old, clean backup. This will be the source of your clean data. You will not need to restore transaction logs or take any other action, providing you're reasonably sure that the corrupted data hasn't been updated since the date of the clean backup.
Preparation
Firstly, you'll need some tools. Here are my favorites:
- Notepad++ (open-source from http://notepad-plus-plus.org/)
- Hex Editor Neo (freeware, from http://www.hhdsoftware.com/free-hex-editor)
- SQL Server Management Studio
- Text comparison tool (e.g. online: http://www.textdiff.com is okay)
And before I get started, here's some assumptions and notes:
- I am using SQL Server 2008 Standard Edition.
- I have full access to the SQL Server data files, which are (in this demonstration) located in c:\del on my file system.
- I have sysadmin access to the SQL Server instance.
- I have access to a full backup which is known to be free of corruption.
- I am using, for this article, a test database populated with two tables, approximately 1.1m data rows, named 'CORRUPTION'. One table is called dbo.Customers and the other is dbo.Transactions. There is an FK relationship between them. The build script to follow along with this tip is available below:
-- PART ONE -- first, create the test database SET NOCOUNT ON CREATE DATABASE CORRUPTION ON PRIMARY ( NAME = 'corruption_primary', FILENAME = 'c:\del\corruption_primary.mdf', FILEGROWTH=10%, SIZE = 100MB, MAXSIZE = 1000MB ), ( NAME = 'corruption_secondary', FILENAME = 'c:\del\corruption_secondary.mdf', FILEGROWTH=10%, SIZE = 100MB, MAXSIZE = 1000MB ) LOG ON ( NAME = 'corruption_log', FILENAME = 'c:\del\corruption_log.ldf', SIZE = 50MB ) GO -- PART TWO -- create some sample data USE CORRUPTION CREATE TABLE dbo.customers ( custid INT IDENTITY(1,1) PRIMARY KEY NOT NULL, fname VARCHAR(100) NOT NULL, sname VARCHAR(100) NOT NULL, isactive BIT NOT NULL DEFAULT 1 ) CREATE TABLE dbo.transactions ( txno INT IDENTITY(1,1) PRIMARY KEY NOT NULL, custid INT FOREIGN KEY REFERENCES dbo.customers(custid), txvalue MONEY NOT NULL, validated BIT NOT NULL ) -- http://www.mssqltips.com/tipImages2/2871_firstnames.csv - source of first names (6480) -- http://www.mssqltips.com/tipImages2/2871_surnames.csv - source of surnames names (6480) CREATE TABLE #firstnames ( firstname VARCHAR(50) ) CREATE TABLE #surnames ( surname VARCHAR(50) ) BULK INSERT #firstnames FROM 'c:\del\2871_firstnames.csv' WITH ( MAXERRORS = 1, KEEPIDENTITY ) BULK INSERT #surnames FROM 'c:\del\2871_surnames.csv' WITH ( MAXERRORS = 1 ) ALTER TABLE #firstnames ADD uqid INT IDENTITY PRIMARY KEY NOT NULL ALTER TABLE #surnames ADD uqid INT IDENTITY PRIMARY KEY NOT NULL -- addition of a PK after the fact lets us avoid using format files -- add 10k new customers DECLARE @randFN INT DECLARE @randSN INT DECLARE @counter INT SET @counter = 1 WHILE @counter <= 10000 BEGIN SET @randFN = ROUND((RAND() * 6479) + 1,0) SET @randSN = ROUND((RAND() * 99) + 1,0) INSERT INTO dbo.customers (fname, sname) SELECT f.firstname, s.surname FROM #firstnames f, #surnames s WHERE f.uqid = @randFN AND s.uqid = @randSN SET @counter = @counter + 1 END -- add 1m new transactions DECLARE @randID INT DECLARE @randValue MONEY DECLARE @randValid FLOAT DECLARE @counter1 INT DECLARE @msg VARCHAR(500) SET @counter1 = 0 WHILE @counter1 <= 1000000 BEGIN SET @randID = ROUND((RAND() * 9999) + 1,0) SET @randValue = ROUND(RAND() * 1000,2) SET @randValid = RAND() IF @randValid = 0.995 SET @randValid = 0 ELSE SET @randValid = 1 INSERT INTO dbo.transactions (custid, txvalue, validated) SELECT @randID, CAST(@randValue AS MONEY), CAST(@randValid AS BIT) IF @counter1 % 10000 = 0 BEGIN SET @msg = CAST(@counter1 AS VARCHAR(8)) + ' rows inserted, ' + CAST(1000000 - @counter1 AS VARCHAR(8)) + ' rows to go...' RAISERROR(@msg,10,1) END SET @counter1 = @counter1 + 1 END DROP TABLE #firstnames DROP TABLE #surnames -- check the messages tab while this executes for status updates. May take a short while (RBAR) - 00:02:44 on my system. -- SELECT TOP 100 * FROM dbo.transactions -- to check the record count
Examining a Corrupt SQL Server Data File
First, let's have a look at a healthy data file in the hex editor. If you're following along, fire up Hex Editor Neo and load one of the datafiles created by my build script (see above). Note you will need to set this database OFFLINE to view the file as SQL Server will maintain a handle on it otherwise. You'll see something like this:
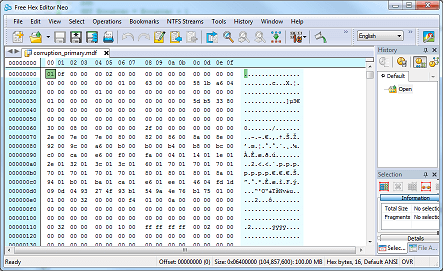
The layout is simple to understand. Each byte is represented in base 16 (hexadecimal) and arranged on the left in sixteen columns. The offset (distance from the start of the file) is on the far left, highlighted in cyan. On the right, the character representation of each byte is shown (ASCII, not Unicode). Scrolling up and down, we can see some of the data in this file. The screenshot below shows some first names and surnames in the dbo.Customers table:
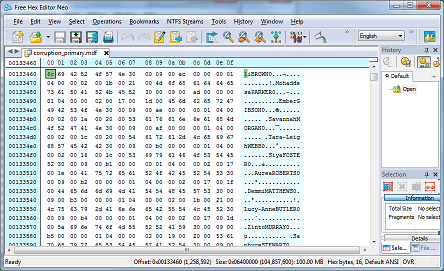
(incidentally, this is an excellent way of hacking SQL Server for non-Windows usernames/passwords, for white-hat purposes of course).
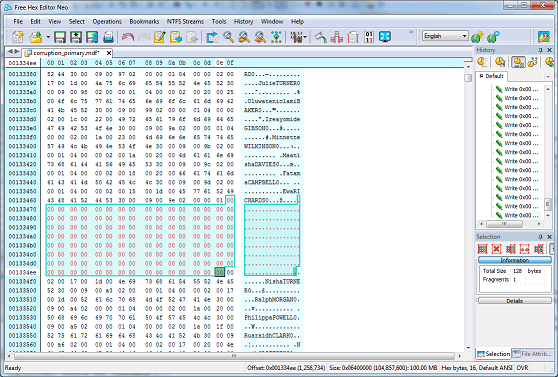
The next screenshot shows me deliberately corrupting some data, by zeroing-out a portion of the data. This is quite close to what would happen during corruption by a third party (such as disk failure) if, for example, marked by the O/S as unusable. Let's corrupt the dbo.Customers table starting at offset 0013346f and continuing until offset 001334ef (about 128 bytes) by replacing with hex 00 (binary 0x00):
Now let's try and get this database online:
ALTER DATABASE [CORRUPTION] SET ONLINE; Result: Command(s) completed successfully.
That's good. But the corruption in this case only extends for 128 bytes and evidently only hits data pages (see http://msdn.microsoft.com/en-gb/library/ms190969(v=sql.105).aspx for a full rundown of page types in SQL Server). If I had corrupted GAM or SGAM pages, or IAM (for indexes), or indeed BCM/DCM pages, I would likely have received a message similar to the type shown at the beginning of this article. So this shows there are two key types of corruption which I will term detected corruption, and undetected corruption. The deliberate corruption just witnessed is undetected, and is arguably even more dangerous than detected corruption, since the database can continue to jog along fine until this data is accessed. This allows corruption to fester within the database and make recovery situations even more complex.
A Deeper Look at the SQL Server Corruption
Let's run DBCC CHECKDB to see if we can uncover the corruption using SQL Server Management Studio:
... DBCC results for 'customers'. Msg 8928, Level 16, State 1, Line 1 Object ID 2105058535, index ID 1, partition ID 72057594038779904, alloc unit ID 72057594039697408 (type In-row data): Page (1:153) could not be processed. See other errors for details. Msg 8939, Level 16, State 98, Line 1 Table error: Object ID 2105058535, index ID 1, partition ID 72057594038779904, alloc unit ID 72057594039697408 (type In-row data), page (1:153). Test (IS_OFF (BUF_IOERR, pBUF-bstat)) failed. Values are 63047689 and -4. ... repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (CORRUPTION). DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Argh! Note the key phrase here: "repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (CORRUPTION)"
However unhelpful this statement is, the detailed results produced by DBCC CHECKDB do give us some information on where the corruption lies. We can also find this information using DBCC PAGE and DBCC IND (Background information on these commands here - http://www.sqlskills.com/blogs/paul/inside-the-storage-engine-using-dbcc-page-and-dbcc-ind-to-find-out-if-page-splits-ever-roll-back/, here - http://blogs.msdn.com/b/sqlserverstorageengine/archive/2006/12/13/more-undocumented-fun_3a00_-dbcc-ind_2c00_-dbcc-page_2c00_-and-off_2d00_row-columns.aspx) and here - http://www.mssqltips.com/sqlservertip/1578/using-dbcc-page-to-examine-sql-server-table-and-index-data/.
DBCC CHECKDB gave us the page affected, so let's use DBCC PAGE to examine the page's hex contents (1:153). You will need to switch on trace flag 3604 first.
DBCC TRACEON(3604) DBCC PAGE(CORRUPTION,1,153,2)
Here's some of the output (too long to show in full):
PAGE: (1:153) BUFFER: BUF @0x000000010EFF5400 bpage = 0x000000010EE68000 bhash = 0x0000000000000000 bpageno = (1:153) bdbid = 10 breferences = 0 bUse1 = 64 bstat = 0x2c00809 blog = 0x79ca2159 bnext = 0x0000000000000000 PAGE HEADER: Page @0x000000010EE68000 m_pageId = (1:153) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x200 m_objId (AllocUnitId.idObj) = 27 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057594039697408 Metadata: PartitionId = 72057594038779904 Metadata: IndexId = 1 Metadata: ObjectId = 2105058535 m_prevPage = (0:0) m_nextPage = (1:156) pminlen = 9 m_slotCnt = 252 m_freeCnt = 1 m_freeData = 7687 m_reservedCnt = 0 m_lsn = (19:464:16) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 1132858382 Allocation Status GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED DATA: ... 000000000ECAB460: 6c694252 4f574e30 000900ac 00000000 †liBROWN0. .¬.... 000000000ECAB470: 00000000 00000000 00000000 00000000 †................ 000000000ECAB480: 00000000 00000000 00000000 00000000 †................ 000000000ECAB490: 00000000 00000000 00000000 00000000 †................ 000000000ECAB4A0: 00000000 00000000 00000000 00000000 †................ 000000000ECAB4B0: 00000000 00000000 00000000 00000000 †................ 000000000ECAB4C0: 00000000 00000000 00000000 00000000 †................ 000000000ECAB4D0: 00000000 00000000 00000000 00000000 †................ 000000000ECAB4E0: 00000000 00000000 00000000 00000000 †................ 000000000ECAB4F0: 00000000 00000000 00000000 00000000 †................ 000000000ECAB500: 00000000 00000000 00000000 00000000 †................ 000000000EC ...
You can see that this is where I deliberately corrupted the file. But you'll notice the page location differs from our original absolute (file) offset figure of 0x013346f (1258607) - instead, it's 0x10EE68000. This gives us a problem - it's difficult to locate the corrupted data.
Locating SQL Server Database Corruption
Happily, there's a simple way to both confirm the page number and find the physical offset of the I/O corruption - force a logical consistency error. We know from this line in the DBCC CHECKDB output the name of the table or index affected:
"DBCC results for 'customers'..."
So let's force a logical consistency error by attempting to read this table. This will provide us with a physical offset address from the start of the affected file:
SELECT * FROM dbo.Customers
We then receive the following error:
Msg 824, Level 24, State 2, Line 2 SQL Server detected a logical consistency-based I/O error: incorrect checksum
(expected: 0x43860c0e; actual: 0x958afc9c). It occurred during a read of page (1:153)
in database ID 10 at offset 0x00000000132000 in file 'c:\del\corruption_primary.mdf'.
Additional messages in the SQL Server error log or system event log may provide more
detail. This is a severe error condition that threatens database integrity and must
be corrected immediately. Complete a full database consistency check (DBCC CHECKDB).
This error can be caused by many factors; for more information, see SQL Server Books
Online.
We can confirm this address is reasonably accurate by confirming the page number is 153 (as per the DBCC PAGE output and DBCC CHECKDB output), and therefore confirm the physical location of the corruption as follows:
- Offset(h) / 2000(h) = Page Id (h) (divide the offset given by 8192 in hexadecimal (2000))
- 0x00132000 / 2000 = 99(h)
- 99(h) = 153 (convert back to decimal to get the page number)
Now, 132000(h) differs from 13346f(h) which is where we KNOW we started to corrupt the data. Let's take a look at the hex editor at physical offset 132000 to try and explain the difference:
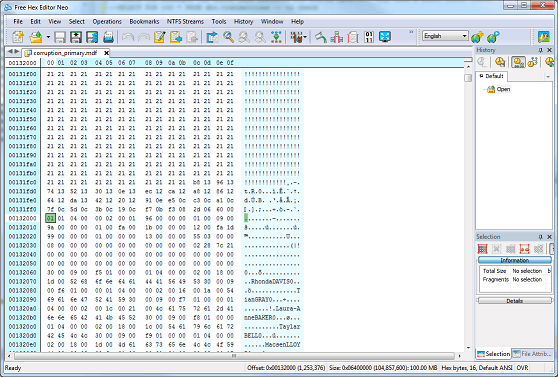
You will note that offset 132000(h) corresponds to the START of the corrupted page. We will not be able to determine exactly WHERE in the page the corruption occurs, simply because corruption is detected using checksums. The checksum will calculate whether or not the page is valid - not pinpoint where exactly the corruption begins. We know a page is 8,192 bytes in SQL Server - that's the default page size, and we now know that this converts to 2000(h). So simply slice a page (offset start 132000(h) to 134000(h)) from the corrupted database file into your text comparison tool. I'm going to take the hex representation of the data, for simplicity:
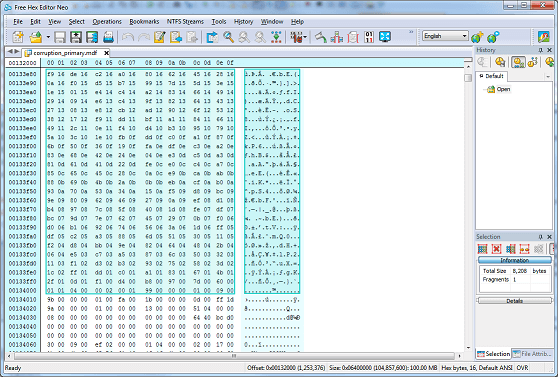
However, what we have done is narrowed the range where the corruption lies.
Fixing the SQL Server Corruption Problem
We can now use a data comparison tool (pick one that suits you) to compare the page from a valid copy of the database to the corrupted page. You will then get a side-by-side comparison of exactly what has changed, and what bytes within that range need changing. I'm going to use an online service, http://www.textdiff.com, to do this. The text highlighted in red, below, shows the changed values:

The easiest way of getting a valid version of the affected page is to restore an older copy of the database as a new, separate, database, then set it offline and open it in your hex editor. Providing you have a *reasonable expectation* that the data in that page is unlikely to have changed (naturally) in the interval between the date of the backup and the date of the corruption (you can calculate the probability for this depending on your circumstances) then you will be able to copy and paste the entire data page (don't copy and paste just the block that's changed, since the 'old' checksum will invalidate it) from the hex editor window with the valid copy to the hex editor window with the corrupted copy.
Once you have done this, save and close the corrupted file, then SET ONLINE in SQL Server Management Studio. Now run DBCC CHECKDB. You should find no anomalies with the data.
Miscellany
CAVEATS:
- If corruption is widespread, i.e. in more than one location or over a large area, other types of pages may be affected which will cause SQL Server to be unable to open the file. You may wish to restore instead, or do a larger copy/paste operation by directly comparing an old backup with the corrupted copy and replacing larger swathes of the data file.
- Direct editing of the file is a method that is intolerant of faults. Checksums are calculated on a page-by-page basis and should you fail to copy/paste correctly, I/O errors will still occur or you may be unable to open the database.
- This is not a 'quick-fix' solution - you will need to take time beforehand practicing this kind of operation for it to be successful.
Another interesting tidbit of information relating to this is a method of calculating the allocation unit ID. The allocation unit ID simply refers to the ID of the allocation unit, which is a logical container of data than spans multiple pages. There are three types - you can read more about them here - http://sqlserverdownanddirty.blogspot.co.uk/2011/04/what-are-allocation-units.html. Allocation unit views such as sys.allocation_units are helpful for finding out, for example, how many pages in a particular allocation unit are used (giving you an idea of, in this context, how much data is affected). By checking data_space_id in the aforementioned view, you can see which filegroup the corrupted data is located in. However what's not commonly known is that you can get the allocation unit ID from the object ID by using some simple mathematics. Note this doesn't apply if the object is a LOB (m_objid will be 255):
m_objid * 65536 + (2^56) = Allocation Unit ID
Using the DBCC PAGE information from earlier:
- m_objId = 27
- 27 * 65536 = 1769472
- 1769472 + (2^56) = 72057594039697408
- Metadata: AllocUnitId = 72057594039697408 (confirmed)
Also, bear in mind that if you're attempting to find out whether the corruption affects an index (in this case, the clustered index of dbo.customers) you may find this difficult to establish, especially if you have had to start the database in EMERGENCY mode. Fortunately, we can find out whether or not the corruption affects an index or not by using some system views.
So we know the allocation unit ID using the above method - let's find the hobt_id (which is identical to the container_id if type = IN_ROW_DATA) and we can then query sys.partitions to give us the index number, if not on the clustered index for the affected object.
SELECT * FROM sys.allocation_units
WHERE allocation_unit_id = 72057594039697408
Results:
allocation_unit_id type type_desc container_id data_space_id total_pages used_pages data_pages 72057594039697408 1 IN_ROW_DATA 72057594038779904 1 25 21 19
OK, so we know that if type = 1 or 3 ('in-row data') then container_id = sys.partitions.hobt_id (otherwise sys.partitions.partition_id for LOB data). Using this information:
SELECT * FROM sys.partitions WHERE hobt_id = 72057594038779904
Results:
partition_id object_id index_id partition_number hobt_id rows filestream_filegroup_id data_compression data_compression_desc 72057594038779904 1131151075 1 1 72057594038779904 2506 0 0 NONE
This is useful information - it tells us the number of potential affected rows, plus the index_id on the object, which we can find out more information about by querying sys.objects, sys.tables and sys.indexes, JOINing on this ID where necessary.
Next Steps
- I hope this article has given you an insight into recovery of SQL Server databases using non-standard tooling. Feel free to comment and I'll respond as soon as possible. If this topic interests you, please follow the links scattered throughout this piece for further information, particularly for the DBCC commands PAGE, IND and CHECKDB. Many thanks for reading.
- Further MSSQLTips.com reading:
- Table-level Recovery - http://www.mssqltips.com/sqlservertip/2814/table-level-recovery-for-selected-sql-server-tables/
- Using the Emergency State for a Corrupt SQL Server Database - http://www.mssqltips.com/sqlservertip/2333/using-the-emergency-state-for-a-corrupt-sql-server-database/
- SQL Server Disaster Recovery Planning and Testing - http://www.mssqltips.com/sqlservertip/1258/sql-server-disaster-recovery-planning-and-testing/






About the author
 Dr. Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.
Dr. Derek Colley is a UK-based DBA and BI Developer with more than a decade of experience working with SQL Server, Oracle and MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
