Problem
You are seeing evidence of an excessive number of query compilations or recompilations in SQL Server. This may be manifesting itself as high CPU load, or longer transaction execution times. You need to identify which queries are causing this behavior and identify potential solutions to reduce the strain on resources, and make query plan selection more efficient.
Solution
In this article, I will cover a couple of approaches to this problem. These are by no means the only approaches, and careful reading of Books Online and some of the articles by leading Microsoft MVPs will yield many more approaches to query optimization. The first approach I will cover is using SQL Server DMVs to identify plans in the plan cache that may be underused or adhoc/one-time-only, and patterns; the second approach is a little more innovative, using PowerShell to identify stored procedures that force recompilation with every execution.
Background
The SQL Server plan cache is the receptacle in which the plan from the output of the query optimizer will be placed. In SQL Server 2005 and new versions, the Dynamic Management View named sys.dm_exec_cached_plans exists to allow the DBA to interrogate the plan cache and pull relevant statistics from it to illuminate the patterns in which plans are cached – these patterns are a reflection of the shape of the data being pumped through SQL Server, and will depend on various factors; whether parameterized stored procedures are used; whether ORM-modeled queries (such as nHibernate) are prevalent; whether the database engine handles a predictable set of queries from a set application (or an adhoc set of queries from a wide application base); whether forced parameterization of queries at runtime is being used. Prior to SQL Server 2005, the system view sys.syscacheobjects gives similar information (and is still present, but deprecated, in more current versions of SQL Server).
The plan cache is not, in fact, the only receptacle for objects such as plans – the caching infrastructure comprises of a number of logical stores called cache stores. An interesting DMV which will illustrate the different types of cache store can be queried as follows, and (in SQL Server 2012) returns 41 rows:
SELECT cache_address, name, [type] FROM sys.dm_os_memory_cache_counters WHERE [type] LIKE 'CACHE%'
The output shows many types, from the straightforward ‘SQL Plans’, ‘Extended Stored Procedures’ through to some esoteric caches for Service Broker. For the purposes of this article, the ‘plan cache’ refers to those cache(s) that store compiled SQL plans, although an interesting and detailed description of the way queries are held in caches (using hash tables and buckets) can be found in ‘Professional SQL Server 2008 Internals and Troubleshooting’, published by Wrox, ISBN 978-0-470-48428-9, Ch.5, pg 155-159.
It suffices to say that when a query is considered for execution by the database engine, the engine first checks if the plan is in cache and if not, will recompile the plan for execution. This both increases the load on CPU and memory (since both will be used during this process) and increases the query transaction time.
Demonstration of Effects
This is a brief demonstration of the effect that finding a cached plan, and recompiling the query, can have on query execution time and CPU load. Run the following code to set up our environment (substitute ‘SANDBOX’ for your test database name):
USE SANDBOX GO CREATE TABLE dbo.LargeTable ( uqid INT NOT NULL, someVal1 VARCHAR(10), someVal2 VARCHAR(10), someVal3 VARCHAR(10), CONSTRAINT pk_nci_uqid_LargeTable PRIMARY KEY NONCLUSTERED (uqid) ) GO DECLARE @counter INT = 0 WHILE @counter <= 100000 BEGIN INSERT INTO dbo.LargeTable ( uqid, someVal1, someVal2, someVal3 ) SELECT @counter, 'Red', 'Green', 'Orange' SET @counter = @counter + 1 END UPDATE STATISTICS dbo.LargeTable WITH FULLSCAN GO SET NOCOUNT ON SET STATISTICS IO ON SET STATISTICS TIME ON -- turn on Client Statistics, and Actual Execution Plan
This script will create a table called ‘LargeTable’ with 100,000 rows, with a non-clustered primary key on ‘uqid’, an integer, effectively leaving the table a heap. The reason this is non-clustered is to slow down the speed at which a SELECT query on a given ‘uqid’ value returns, to better illustrate the point, i.e. the differences between plan cache retrieval and query plan recompilation. Note the SomeValX columns do not form part of the index. In reality a clustered index would probably be in place.
Now consider the following SELECT query:
SELECT SomeVal2 FROM dbo.LargeTable WHERE uqid = 75000
The query returns an interesting execution plan, where the non-clustered index is used for the key seek but a row ID (RID) lookup on the heap is used for the ‘SomeVal2’ retrieval (since it doesn’t form part of the primary key). This is besides the point – but interesting nonetheless:

The client stats reveal the execution time for the query, measured in milliseconds:
Time Statistics Client processing time 25 Total execution time 47 Wait time on server replies 22
So the server took 22ms to process the query. Let’s look in the plan cache to verify it’s been entered, for use next time around.
SELECT p.usecounts, size_in_bytes, cacheobjtype, objtype, t.[text] FROM sys.dm_exec_cached_plans p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) t WHERE t.[text] LIKE '%LargeTable%'
You should see 3 rows returned – the query immediately above, the basic SELECT query as an adhoc plan, and the basic SELECT query as a prepared plan using simple parameterization. Note you may not see all three rows, depending on SQL Server version and whether or not you optimize for adhoc workloads (check sp_configure advanced options). If you see all three, they will look like this:

Now we know the plans are in cache, let’s rerun the query using the same ‘uqid’ lookup, 75000. You will note that the ‘usecount’ column for this query increments by 1, as the adhoc plan is used. Now, although the optimizer was clever enough to place a parameterized plan into cache, if you rerun the query using a different value for ‘uqid’ (e.g. 50000), you will note that a *second* adhoc plan is put into cache, and the parameterized plan is ignored completely! In the following sections, we will look at the options to enable forced parameterization of queries, and the ‘optimize for adhoc workloads’, which can affect this behavior and reduce the churn on the plan cache. Incidentally, when we re-run the SELECT for the second time using the same ‘uqid’ parameter, the wait time on server replies reduces to just 3ms.
Profiling the Plan Cache
For this section, I’ll use the ‘AdventureWorks2012’ database available from Microsoft TechNet, and use Jonathan Kehayia’s script to generate workload (available here -> http://www.sqlskills.com/blogs/jonathan/the-adventureworks2008r2-books-online-random-workload-generator/ in order that the plan cache might have content for demonstration use. You do not need to do this if testing these queries on a live-like system – please do not use on production without testing on your own test beds first.
This is a method I used recently to profile one of our production servers’ plan cache. Simply put, it measures the proportion of plans in cache that are adhoc vs. the proportion that are prepared (or indeed other categories). A similar version can group by usecount, identifying those parameterized (or otherwise) queries that are hit often and those that are not. This is handy for profiling the shape of the queries coming into the database and will inform your discussions with your developers about reusing queries (and give you valuable ammunition in the war of ORM vs. relational):
DECLARE @sumOfCacheEntries FLOAT = ( SELECT COUNT(*) FROM sys.dm_exec_cached_plans ) SELECT objtype, ROUND((CAST(COUNT(*) AS FLOAT) / @sumOfCacheEntries) * 100,2) [pc_In_Cache] FROM sys.dm_exec_cached_plans p GROUP BY objtype ORDER BY 2
Here’s the output (from AdventureWorks2012):

Look closely at the percentage of ‘adhoc’ plans in the cache. These represent plans that are typically used once only (although not always) and are filling the cache (around 32% in my case) where more relevant query plans could be occupying the space. Here’s another version that will identify the percentage of all compiled plans in the cache with a single usecount, against those with a usecount > 1, for the subset of the plan cache where the cacheobjtype is a compiled plan (the query above is for all types, but you can amend it to suit if you need to). It’s not optimal, it’s a bit down-and-dirty but it does the job – use a CTE if you want this to be more efficient:
DECLARE @singleUse FLOAT, @multiUse FLOAT, @total FLOAT
SET @singleUse = ( SELECT COUNT(*)
FROM sys.dm_exec_cached_plans
WHERE cacheobjtype = 'Compiled Plan'
AND usecounts = 1)
SET @multiUse = ( SELECT COUNT(*)
FROM sys.dm_exec_cached_plans
WHERE cacheobjtype = 'Compiled Plan'
AND usecounts > 1)
SET @total = @singleUse + @multiUse
SELECT 'Single Usecount', ROUND((@singleUse / @total) * 100,2) [pc_single_usecount]
UNION ALL
SELECT 'Multiple Usecount', ROUND((@multiUse / @total) * 100,2)
Here’s the output (from AdventureWorks2012):

Note that a massive 71.62% of the plans in my example have just a single usecount! This shows how, in my case, the plans with a single usecount are being badly misused.
So, what to do about it? Happily, we can CROSS APPLY with sys.dm_exec_sql_text to fetch the SQL text being executed within the query. We can then track down the offending application or user, and refactor (or re-educate) them about writing re-usable code. Let’s see how:
SELECT TOP 10 t.[text] FROM sys.dm_exec_cached_plans p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) t WHERE usecounts = 1 AND cacheobjtype = 'Compiled Plan' AND objtype = 'Adhoc' AND t.[text] NOT LIKE '%SELECT%TOP%10%t%text%'
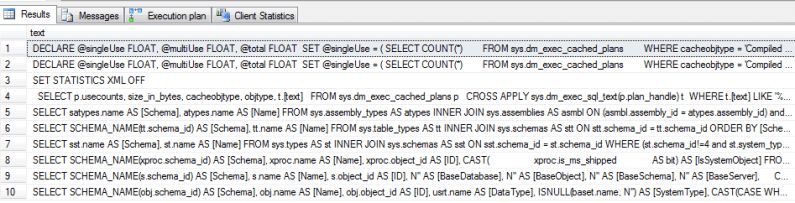
You can see here some of the queries I’ve ran as part of this article appearing here, since they were only used once. But as a result of the load I put through earlier there’s some other queries. Let’s take the query in row 7:
SELECT sst.name AS [Schema], st.name AS [Name] FROM sys.types AS st INNER JOIN sys.schemas AS sst ON sst.schema_id = st.schema_id WHERE (st.schema_id!=4 and st.system_type_id!=240 and st.user_type_id != st.system_type_id and st.is_table_type != 1) ORDER BY [Schema] ASC,[Name] ASC
You can immediately see why this is an adhoc query – the parameters are fixed (see line 8) and these hardcoded figures were not parameterized by the query optimizer. So this gives us a couple of options.
Use Parameterized Stored Procedures
One way in which this particular query would be served is by couching it in a stored procedure and passing in the hard values as parameters to the stored procedure. The query plan would then be stored as parameterized, and this would mean fewer duplicates in the plan cache, freeing up space, reducing CPU and improving query execution time. This is a conversation that you can have with your developers and a little time invested on your part, with a demonstration of the two methods side-by-side to illustrate the impact of each approach, may yield co-operation.
Important! Note that parameterized stored procedures (and indeed parameterized queries) may be subject to the ‘parameter sniffing’ phenomenon, where the query optimizer will use statistics to work out the best execution plan of a parameterized stored procedure / query based on a previous plan, although the parameters may be wildly different. This affects row cardinality estimates in the query execution plan and can lead to undesirable effects – consider, for instance, the selection of an INNER LOOP JOIN for the join of a small subset of a table to a very large one (reasonable), applied to the same query when the subset is no longer small – a LOOP join will dramatically increase the number of reads required, where perhaps an INNER MERGE JOIN might have been more appropriate!
Setting Optimize For Ad Hoc Workloads Option
We can use the sp_configure option ‘optimize for ad hoc workloads’ by following the steps below. Note that this option may result in performance degradation should you have predictable workloads – you can tell if you have predictable workloads by analyzing the spread of adhoc queries as demonstrated above, and testing performance in your test environment with this option on or off. It may be that hardcoded values are mostly presented rather than dynamic parameters, in which case this option may not be for you, and forced parameterization might be better. To set ‘optimize for ad hoc workloads’, do the following:
EXEC sp_configure 'show advanced options', 1 RECONFIGURE WITH OVERRIDE GO EXEC sp_configure 'optimize for ad hoc workloads', 1 RECONFIGURE WITH OVERRIDE GO
This option has an interesting effect – the first time the query is compiled, a stub is placed in the plan cache rather than the full plan. The second time it is compiled, the full plan is put in the plan cache and any subsequent executions will refer to the cache. This has the beneficial effect of ensuring only frequently-used queries enter the cache proper, and ad-hoc queries are all but disregarded.
Forced Parameterization
You can also force parameterization on queries. This is a database-level option, so will be applied to all queries – this is because the plan cache is database-scoped. There is a great deal of information on forced parameterization on TechNet here -> http://technet.microsoft.com/en-us/library/ms175037(v=sql.105).aspx which is invaluable when understanding the subject, and beyond the scope of this article to go into in great depth. Here, however, is a simple example of using it. It will ensure that all literal values will be parameterized rather than literally entered into the plan. Parameterization is applied at SQL statement-level and different rules will apply depending on the type of statement – exceptions are listed in the link above.
The simple statement below will force parameterization, but note it will also flush the plan cache – undesirable in a busy period on an OLTP database!
ALTER DATABASE [] SET PARAMETERIZATION FORCED;
It’s worth noting again about parameter sniffing and how this can adversely affect your database performance when using forced parameterization – please research this before using and use with caution!
Using PowerShell to Find Forced Recompiles
This is a more in-depth and domain-specific example. In my shop, we use Quest Spotlight for SQL Server Enterprise, a good tool with many powerful features. Arguably, the feature which has most value is the home page for each registered server, which displays various stats for the server. This is helpful in getting a quick view into where potential problems may lie. As I said at the start of this article, CPU and query execution times are most affected by too-frequent recompiles, which can be caused by a shortage of plan cache space (caused in part by too many ad-hoc plans!), by over-use of ad-hoc plans due to no forced parameterization or no parameterization of stored procedures, or indeed by the deliberate use of WITH RECOMPILE in the header of a stored procedure.
If you don’t have Spotlight, use Perfmon and get the SQL Compilations/sec and Batch Requests/sec counters. Divide the former by the latter to get the ratio of compilations/batch requests. I will not suggest an optimal number here, but if this is a high ratio then it is likely compilations are affecting the performance of your database, especially if coupled with high CPU and/or long query execution times.
The method below uses some aspects of PowerShell to go through all stored procedures in a database, and parse them for the WITH RECOMPILE addition in the header. These stored procedures are then output to a file, so you can identify each one, assess whether there is a good reason for recompilation rather than referencing the plan cache (sometimes there is, i.e. when parameter sniffing is skewing the cardinality in your execution plans and choosing bad plans), and decide whether to remove this option from the stored procedure.
For the demonstration below, I have used the AdventureWorks2012 database. Since this database doesn’t come with any stored procedures with the WITH RECOMPILE option, I have amended the [dbo].[uspGetManagerEmployees] procedure with this option for demonstration purposes.
Since PowerShell is a subject that can fill many books, I will not explain the syntax behind every line, but I will explain what each line is doing. My thanks here go to Sean McCown (http://www.midnightdba.com) for the crash-course introduction to PowerShell I went through a little while ago, and on whose approach this script is based.
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.Management.Smo") | out-null
$ScriptingOptions = New-Object "Microsoft.SqlServer.Management.Smo.ScriptingOptions"
$ScriptingOptions.DdlHeaderOnly = 1
echo $null | out-file "C:\del\test.txt"
cd SQLSERVER:\SQL\localhost\DEFAULT\Databases\AdventureWorks2012\StoredProcedures
$StoredProcedures = Get-ChildItem
foreach ( $sp in $StoredProcedures ) {
$sp = [string]$sp.script($ScriptingOptions) | where { $_.contains("RECOMPILE") } | out-file "C:\del\test.txt" -Append
}
Line 1:
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.Management.Smo") | out-nullLoad SQL Server SMOs from the assembly into the current session, output message to null.
Line 2:
$ScriptingOptions = New-Object "Microsoft.SqlServer.Management.Smo.ScriptingOptions"
Set variable $ScriptingOptions to contain a new instance of the ScriptingOptions class. This instance is then passed into script() on line 7 and we can set the properties accordingly. I have chosen to list the headers only, which will give us the names of the stored procedures we can target for optimization. You can find the full list of properties here -> http://msdn.microsoft.com/en-us/library/microsoft.sqlserver.management.smo.scriptingoptions_properties.aspx
Line 3:
$ScriptingOptions.DdlHeaderOnly = 1
This sets the scripting option to script out only the header of the stored procedure. We can use SQL Server Management Studio at a later date to amend the stored procedure to use the plan cache where possible, if appropriate.
Line 4:
echo $null | out-file "C:\del\test.txt"
Create a new, blank file.
Line 5:
cd SQLSERVER:\SQL\localhost\DEFAULT\Databases\AdventureWorks2012\StoredProcedures
Navigate to the correct directory to access the stored procedures.
Line 6:
$StoredProcedures = Get-ChildItem
Create a new variable called $StoredProcedures which contains the collection of objects returned from the Get-ChildItem cmdlet (equivalent to dir, where each ‘line’ is an object – in this case, each stored procedure is an object).
Lines 7-10:
foreach ( $sp in $StoredProcedures ) { $sp = [string]$sp.script($ScriptingOptions) | where { $_.contains("RECOMPILE") } | out-file "C:\del\test.txt" -Append }For each stored procedure (each item in collection $StoredProcedures), create a new variable called $sp and assign to it the string representation of the output of the script() method on the stored procedure, subject to the $ScriptingOptions defined. Furthermore, filter out only those strings that contain the substring ‘RECOMPILE’, and append those to our chosen output file.
Here is the output:
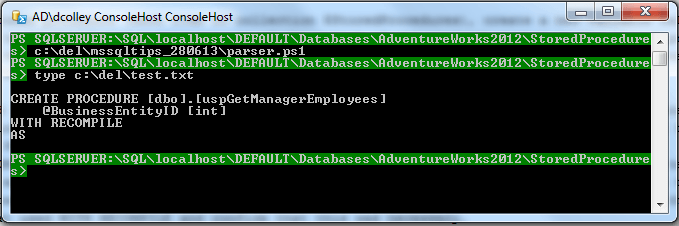
This method works well to identify stored procedures, but not necessarily to identify statements or query batches using the OPTION(RECOMPILE) query hint. For this, I would modify my PowerShell script to parse over a SQL Profiler trace file or server-side trace to filter out only those statements using OPTION(RECOMPILE), or alternatively use ordinary WHERE clauses in T-SQL syntax to filter on a table containing my trace. However, this approach is useful and I used this recently to verify that the recompile rate on one of my production databases was appropriate. I was able to identify the three queries that used WITH RECOMPILE and confirm that this was necessary.
Next Steps
I hope this article was useful and gave you an insight into a couple of ways that you can diagnose plan cache problems. Please use the links below for further information. Comments are welcome and I’ll respond as soon as I can. Thanks for reading!
- Books Online Random Workload Generator – http://www.sqlskills.com/blogs/jonathan/the-adventureworks2008r2-books-online-random-workload-generator/
- Forced Parameterization in SQL Server – http://technet.microsoft.com/en-us/library/ms175037(v=sql.105).aspx
- PowerShell videos – http://www.midnightdba.com
- ScriptingOptions Properties – http://msdn.microsoft.com/en-us/library/microsoft.sqlserver.management.smo.scriptingoptions_properties.aspx
- Analyzing the SQL Server Plan Cache – https://www.mssqltips.com/sqlservertip/1661/analyzing-the-sql-server-plan-cache/
- Analyzing SQL Server Plan Cache Performance Using DMVs – https://www.mssqltips.com/sqlservertip/2196/analyzing-sql-server-plan-cache-performance-using-dmvs/

Dr. Derek Colley is the lead technical consultant for Optimal Computing, a boutique data consultancy based in the UK NW helping clients troubleshoot, configure, plan and deploy their data platforms. He specializes in data integration and database performance optimization, and is a PhD candidate with Staffordshire University, looking into methods of integrating AL query selection algorithms with the cost-based query optimizer. In his spare time, he enjoys building robots, going outdoors, and spending time with his four children.
- MSSQLTips Awards: Trendsetter (25+ tips)


