By: Daniel Farina | Comments (3) | Related: > In Memory OLTP
Problem
Due to the fact that for Memory-Optimized tables statistics are not automatically updated, we must manually update statistics in order to take advantage of new statistics for In-Memory OLTP. But this is not so simple and as you may know, even when statistics are manually updated Natively Compiled Stored Procedures seem to ignore them. In this tip I will explain to you why this happens and how we can address this issue.
Solution
We all know the importance of statistics and the consequences of outdated statistics, but if you don't here is a tip you can read about Issues Caused by Outdated Statistics in SQL Server. You may think that the lack of auto update statistics for Memory-Optimized tables is a Microsoft oversight, but after you read this tip you will understand why it was done this way.
Statistics on Memory-Optimized tables
When you create a Memory-Optimized table, SQL Server creates statistics on index key columns. But these statistics are not only useless, they can be detrimental too as you will see further on.
The key to understand why base statistics can be harmful relies on indexes, specifically HASH indexes. This is a complex discussion which I will cover in another tip, so for now you only need to know that every HASH index is defined with a number of buckets. So to create default statistics SQL Server assumes that the table will have a number of rows equal to the number of buckets on the index, which is not a bad assumption if you created the primary key with the right number of buckets.
How to create or update statistics on Memory-Optimized tables
When using CREATE STATISTICS or UPDATE STATISTICS, you must specify NORECOMPUTE and FULLSCAN options. The NORECOMPUTE option is obvious because Memory-Optimized tables do not automatically update statistics. Memory-Optimized tables don't support sampled statistics, so the FULLSCAN option is mandatory.
Also you can execute sp_updatestats stored procedure to update statistics. For disk based tables this stored procedure updates only the statistics that require updating based on the information in the sys.sysindexes catalog view and can trigger a recompile of stored procedures if required. On Memory-Optimized tables this stored procedure always generates updated statistics, but does not recompile Natively Compiled Stored Procedures.
Statistics and Natively Compiled Stored Procedures
On standard stored procedures, when you update statistics an improved query plan is created and used, but this does not happen on Natively Compiled Stored Procedures.
Standard stored procedures can be recompiled without notice. Even when done on the fly, recompilation prior to execution degrades performance but this is not critical. Recompilation creates a new query plan which then is stored in the plan cache.
Natively Compiled Stored Procedures do not use the plan cache. Remember from my previous tip about Migration to Natively Compiled Stored Procedures that the query plan is made at compile time when the procedure's DLL is created. So to use a new plan on a natively compiled stored procedure you must drop and recreate the natively compiled stored procedure in question.
How to proceed
The following are the steps you should take when deploying Memory-Optimized tables and Natively Compiled Stored Procedures.
- Create tables and indexes
- Load data into the tables
- Update statistics on the tables
- Create Natively Compiled Stored Procedures
If table data changes substantially then you should do the following to properly update statistics and therefore query plans.
- Update statistics on the tables
- Drop and recreate natively compiled stored procedures
Of course, you should avoid performing these steps during peak workload.
Example
I have created the following example, so you can see all of these concepts.
1. Sample database creation
First we need to create a sample database with a Memory-Optimized Filegroup.
CREATE DATABASE TestDB
ON PRIMARY
(NAME = TestDB_file1,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Data\TestDB_1.mdf',
SIZE = 100MB,
FILEGROWTH = 10%),
FILEGROUP TestDB_MemoryOptimized_filegroup CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = TestDB_MemoryOptimized,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Data\TestDB_MemoryOptimized')
LOG ON
( NAME = TestDB_log_file1,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Data\TestDB_1.ldf',
SIZE = 100MB,
FILEGROWTH = 10%)
GO
2. Schema creation for In Memory tables
I decided to create a schema for memory-optimized objects to keep things clean.
USE [TestDB] GO CREATE SCHEMA InMemory GO
3. Memory-Optimized tables creation
Now it's time to create the Memory-Optimized tables. Note the value I have used for BUCKET_COUNT on these tables.
USE TestDB;
GO
IF OBJECT_ID('InMemory.Products','U') IS NOT NULL
BEGIN
DROP TABLE InMemory.Products
END
GO
CREATE TABLE InMemory.Products
(
ProductID INT NOT NULL,
Description NVARCHAR (50) NOT NULL,
UnitCost MONEY NULL,
UnitPrice MONEY NULL,
UnitsInStock INT NULL,
Active BIT NULL,
PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
------------------------------------------------------------------------
IF OBJECT_ID('InMemory.Customers','U') IS NOT NULL
BEGIN
DROP TABLE InMemory.Customers
END
GO
CREATE TABLE InMemory.Customers
(
CustomerID INT NOT NULL,
CustomerName NVARCHAR (50) COLLATE Latin1_General_100_BIN2 NOT NULL,
CustomerAddress NVARCHAR (50) COLLATE Latin1_General_100_BIN2
PRIMARY KEY NONCLUSTERED HASH (CustomerID) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
------------------------------------------------------------------------
IF OBJECT_ID('InMemory.OrderHeader','U') IS NOT NULL
BEGIN
DROP TABLE InMemory.OrderHeader
END
GO
CREATE TABLE InMemory.OrderHeader
(
OrderID INT NOT NULL,
OrderDate DATE NOT NULL,
CustomerID INT NULL,
TotalDue MONEY NOT NULL,
PRIMARY KEY NONCLUSTERED HASH (OrderID) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
------------------------------------------------------------------------
IF OBJECT_ID('InMemory.OrderDetail','U') IS NOT NULL
BEGIN
DROP TABLE InMemory.OrderDetail
END
GO
CREATE TABLE InMemory.OrderDetail
(
OrderID INT NOT NULL,
OrderDetailID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY NONCLUSTERED HASH (OrderID, OrderDetailID) WITH (BUCKET_COUNT = 16384) ,
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO4. Loading of data
I have included the sample data in a zip file which you can download here, so you can use it to perform your own test. Also you can create your own test data if you want.
You can use BCP to load the test data with this batch script:
@ECHO OFF SET /P SERVER=Enter Server Name: SET /P USER=User: SET /P PASS=Password: bcp TestDB.InMemory.Customers in "Customers.dat" -S %SERVER% -U %USER% -P %PASS% -c bcp TestDB.InMemory.orderdetail in "orderdetail.dat" -S %SERVER% -U %USER% -P %PASS% -c bcp TestDB.InMemory.orderheader in "orderheader.dat" -S %SERVER% -U %USER% -P %PASS% -c bcp TestDB.InMemory.products in "products.dat" -S %SERVER% -U %USER% -P %PASS% -c
Here is a chart with the table's name, number of rows to be inserted and the primary keys BUCKET_COUNT.
| Table Name |
Inserted Rows |
BUCKET_COUNT |
|---|---|---|
|
InMemory.Customers |
3000 |
131072 |
|
InMemory.Products |
1000 |
131072 |
|
InMemory.OrderHeader |
10000 |
131072 |
|
InMemory.OrderDetail |
1500000 |
16384 |
5. Query execution with outdated statistics
Due to the fact that we cannot see the execution plan on Natively Compiled Stored Procedures I am using an Ad Hoc query for this test.
Estimated execution plan
This is the query in question:
USE TestDB
GO
SELECT 0
FROM InMemory.OrderDetail OD
INNER JOIN InMemory.OrderHeader OH
ON OD.OrderID = OH.OrderID
INNER JOIN InMemory.Products P
ON OD.ProductID = P.ProductID
INNER JOIN InMemory.Customers C
ON OH.CustomerID = C.CustomerID
WHERE C.CustomerID > 500
The following is the estimated execution plan:
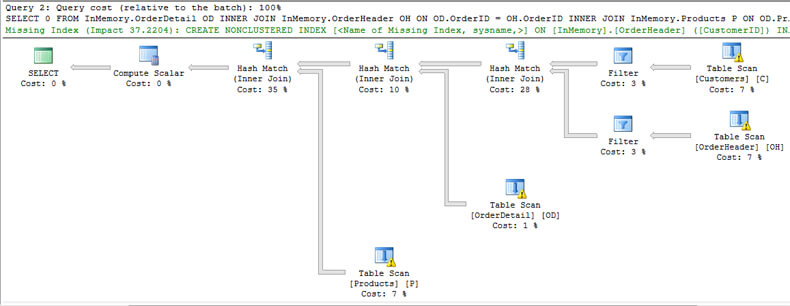
We can see on all tables a yellow warning sign that warns us about outdated statistics.
A note of interest is the suggestion SQL Server makes for the following index.
CREATE NONCLUSTERED INDEX [] ON [InMemory].[OrderHeader] ([CustomerID]) INCLUDE ([OrderID]) GO
If you take a look, SQL Server suggests a covering index. For a disk based table it would be alright, but for memory-optimized tables a covering index is does not make sense because all indexes for memory-optimized tables are covered indexes. Also you can't add an index on a memory-optimized table. You have to drop and recreate it.
Look in the image above at InMemory.Customers table. You might wonder why SQL Server performs a Table Scan instead of an Index Seek to get CustomerID > 500. In a future tip I will explain Hash indexes to give a better understanding.
Actual execution plan
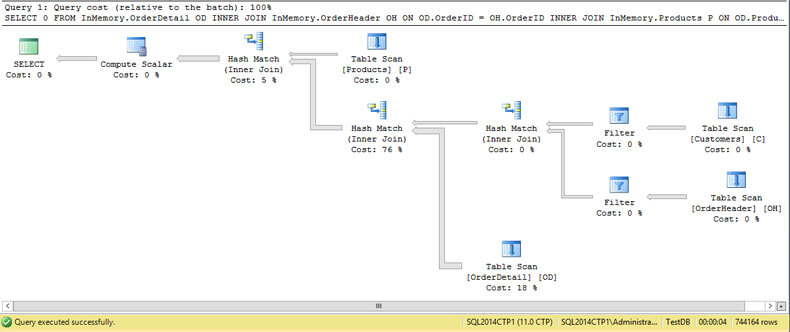
The query took 10 seconds to complete. On the image below we see that the actual and estimated execution plans looks the same with a slight difference.
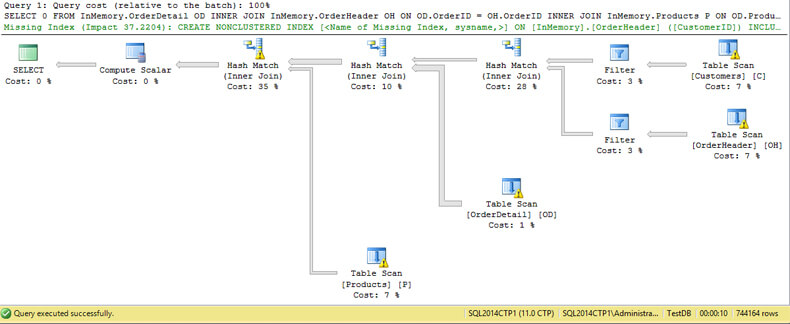
The warning sign on the Hash Match operation warns us that the operator has used TembDB to spill data during execution. This is caused by bad cardinality estimation. If you take a look, the engine estimated 18022 rows where the actual rows are 744164.

If you remember from my previous tips, Hekaton is a lock free and latch free engine. The implication of a query accessing TempDB is the loss of a lock free and latch free environment.
Take a look at the estimated number of rows on all tables. You can see that the estimated number of rows is equal to the value we have used for the BUCKET_COUNT.
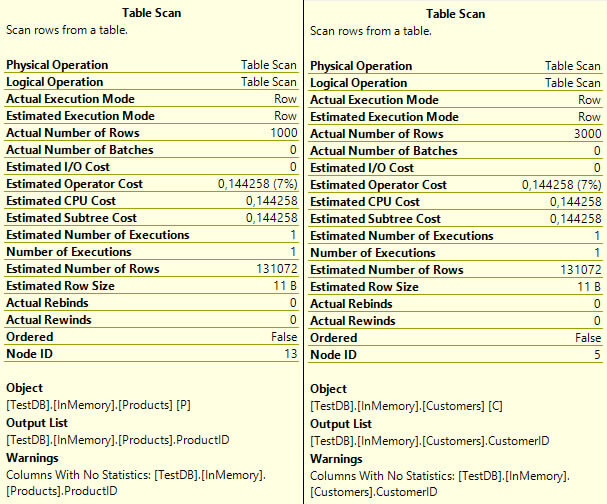
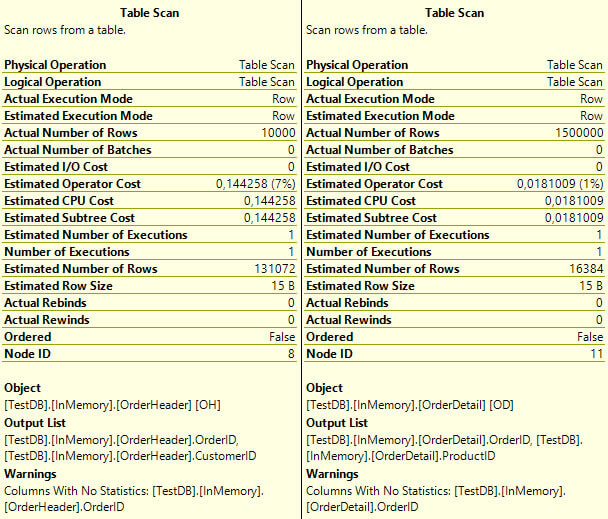
6. Update of statistics
Now we execute the next script to update statistics in our Memory-Optimized tables.
USE TestDB GO UPDATE STATISTICS InMemory.Customers WITH FULLSCAN, NORECOMPUTE; UPDATE STATISTICS InMemory.OrderDetail WITH FULLSCAN, NORECOMPUTE; UPDATE STATISTICS InMemory.OrderHeader WITH FULLSCAN, NORECOMPUTE; UPDATE STATISTICS InMemory.Products WITH FULLSCAN, NORECOMPUTE;
7. Query execution with updated statistics
As you can see, there are no warning signs and the query run time decreased to 4 seconds, less than a half of previous execution.
Conclusion
The fact that Hekaton does not automatically update statistics is coherent with its goal. Hekaton was created with the goal to provide the best execution of workloads without recompilation, which means it is optimized to execute queries in Natively Compiled Stored Procedures. As I previously stated, the query plan is made at compile time when the procedure's DLL is created so the update of statistics is worthless to improve execution for an already created natively compiled stored procedure. That's why you have to manually update statistics, when you as a DBA consider Memory-Optimized tables and then recompile the Natively Compiled Stored Procedures that use them in a maintenance window.
Helper Script
The following code will give you a script to update all statistics on Memory-Optimized Tables and to drop and recreate all Natively Compiled Stored Procedures.
DECLARE @sql NVARCHAR(MAX) = ''
SELECT @sql += N'
UPDATE STATISTICS [' + SCHEMA_NAME(schema_id) + N'].[' + name
+ N'] WITH FULLSCAN, NORECOMPUTE'
FROM sys.tables
WHERE is_memory_optimized = 1
SELECT @sql += +CHAR(13) + CHAR(10) + N'go' + CHAR(13) + CHAR(10)
SELECT-- SCHEMA_NAME(sp.schema_id), sp.name,
@sql += 'DROP PROCEDURE ' + SCHEMA_NAME(sp.schema_id) + '.' + sp.name
+ CHAR(13) + CHAR(10) + 'go' + CHAR(13) + CHAR(10) + sm.definition
+ CHAR(13) + CHAR(10) + 'go' + CHAR(13) + CHAR(10) + REPLICATE('-', 80)
+ CHAR(13) + CHAR(10)
FROM sys.procedures sp
INNER JOIN sys.all_sql_modules sm ON sp.object_id = sm.object_id
WHERE sm.uses_native_compilation = 1
PRINT @sql
Next Steps
- If you still don't have a version of SQL Server 2014, download a trial version here.
- Take a look at my previous tip about migrating to Memory-Optimized Tables: Overcoming storage speed limitations with Memory-Optimized Tables for SQL Server.
- If you don't know what Natively Compiled Stored Procedures are you can read my previous tip Migrate to Natively Compiled SQL Server Stored Procedures for Hekaton.
- Also in this webcast pdf you have an Introduction to SQL Server Statistics.
- This tip will help you to find outdated statistics : How to Find Outdated Statistics in SQL Server 2008.
- Get more information about NORECOMPUTE option of UPDATE STATISTICS in SQL Server.
- Where are execution plans stored? Here you will find the answer: Analyzing the SQL Server Plan Cache.
- Why are execution plans so important? Always have a good plan! What's in your SQL Server Plan Cache?.
- This may be useful: Execute UPDATE STATISTICS for all SQL Server Databases.
- In this tip you will find more resources for maintenance tasks: Performing maintenance tasks in SQL Server.
- If you don't understand execution plans then this tutorial is for you: Graphical Query Plan Tutorial.
- To create your own test data you can take a look at this tip: Populating a SQL Server Test Database with Random Data .
- This tip will help you with your testing: Clearing Cache for SQL Server Performance Testing.
- In this tip you will find Different Options for Importing Data into SQL Server.
- If you have a 24x7 server this should help: Performing SQL Server Maintenance with No Maintenance Window.
- Learn more on how to group objects in schemas with SQL Server Four part naming.
- Check out Maintenance Tips Category for new tips.
- Take a look at Performance Tuning Tips Category.
- Download the scripts and test data here.






About the author
 Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.
Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
