Problem
We have data sets with various algorithms stored and we’d like to construct an automated process that builds additional data sets from these original sets, except without outliers.
Solution
In this tip we look at how can build a process to strip out outlier data from the original data set in an automated manner.
For this solution, we want to follow these guidelines:
- Use a consistent data design. We can completely automate this process (or highly minimize how much we have to do) if we approach our data storage with a consistent and repetitive approach. In our example, we will produce a table that has no outliers based on a table that has outliers, but this process assumes that our ID, average and standard deviation columns follow a consistent naming pattern. (Note: for every exception to the rule, code must be built for the exception to that rule, so keeping things as consistent as possible allows us to write less code.)
- Numerically define our outliers relative to our data set or to what our client expects. If these data are for our client, they make the rules and note that an outlier can be relative in the world of mathematics. Therefore, we want our automated process to accept whatever outlier we want – for instance, with stock data I may choose an outlier that is 4 standard deviations away from the mean, while with income, I may choose an outlier that is 2.75 standard deviations from the mean.
- Determine the final product of our output. Our client needs will determine this; for this example, we will produce a table without outliers from a table with outliers that differs in table name (“_NoOutliers” will be added to the new table) and that has its own incrementing ID instead of reusing the source ID value. There are numerous other approaches, such as storing these data using a relationship approach, where we only store the values of the non-outlier fields with the IDs for an INNER JOIN. We could also return a select statement that subtracts the outliers without creating a table, which is ideal for some environments that may not have the storage space or do not want to allocate any extra storage for additional tables.
Creating the Stored Procedure to Remove Outliers
We will create a stored procedure and pass in four parameters in this example:
- the table name (@t),
- the value (@v, which the average and standard deviation are calculated from),
- our outlier definition (@dev i.e.: 3, meaning 3 standard deviations above or below the mean),
- and the schema name (@sh).
Here is the start of the stored procedure that takes the four parameters:
CREATE PROCEDURE stp_RemoveOutliers @t NVARCHAR(100), @v NVARCHAR(100), @dev DECIMAL(3,1), @sh NVARCHAR(15) AS
Because we’ve assumed that our design is well-built to allow us to automate and reuse the code, from the table parameter, we will automatically “pick up” the ID (@id), average (@avg) and standard deviation (@stdev). We will also have another variable, @to, which will automatically put the schema and table together that we’ll create, such as “[Schema].[Table_NoOutliers]” so that the procedure can check if it already exists.
DECLARE @avg NVARCHAR(250), @stdev NVARCHAR(250), @id NVARCHAR(250), @to NVARCHAR(100) SELECT @id = COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = @t AND COLUMN_NAME LIKE 'ID%' SELECT @avg = COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = @t AND COLUMN_NAME LIKE 'Avg%' SELECT @stdev = COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = @t AND COLUMN_NAME LIKE 'StDev%' SET @to = QUOTENAME(@sh) + '.' + QUOTENAME(@t + '_NoOutliers')
Next, we’ll use dynamic SQL to accept the parameters we’ve passed, as well as the parameters from above that automatically grabbed information from the INFORMATION_SCHEMA.COLUMNS. The first set of T-SQL code below will create a table with outliers removed only if the table doesn’t exist. It will then replace the old incrementing ID on the new table with a new incrementing ID since values may have been removed. Outside of the new ID and outliers removed, it looks exactly like the previous table – we’ll have an entire data set without outliers (we could also adjust the script to only include the IDs and values so we could do an INNER JOIN back to the main table). The second set of T-SQL code below will simply return which data are not outliers.
If you want to create a new table use this set of code:
DECLARE @s NVARCHAR(MAX)
SET @s = N'IF OBJECT_ID(@to) IS NULL
BEGIN
;WITH OutOutlier AS(
SELECT ' + @id + ' NewestID
, ' + QUOTENAME(@v) + ' OutValue
, (' + @avg + ' + (' + @stdev + ' *' + CAST(@dev AS NVARCHAR(3)) + ')) OAbove
, (' + @avg + ' + (' + @stdev + ' *-' + CAST(@dev AS NVARCHAR(3)) + ')) OBelow
FROM ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t) + '
)
SELECT ROW_NUMBER() OVER (ORDER BY ' + @id + ') NoOutlierID
, t2.*
INTO ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t + '_NoOutliers') + '
FROM OutOutlier t
INNER JOIN ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t) + ' t2 ON t.NewestID = t2.' + @id + '
WHERE t.OutValue BETWEEN OBelow AND OAbove
ALTER TABLE ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t + '_NoOutliers') + ' DROP COLUMN ' + @id + '
END
ELSE
BEGIN
PRINT @to + '' exists.''
END'If you want to just return the data for review / reporting use this set of code:
DECLARE @s NVARCHAR(MAX)
SET @s = N';WITH OutOutlier AS(
SELECT ' + @id + ' NewestID
, ' + QUOTENAME(@v) + ' OutValue
, (' + @avg + ' + (' + @stdev + ' *' + CAST(@dev AS NVARCHAR(3)) + ')) OAbove
, (' + @avg + ' + (' + @stdev + ' *-' + CAST(@dev AS NVARCHAR(3)) + ')) OBelow
FROM ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t) + '
)
SELECT t2.*
FROM OutOutlier t
INNER JOIN ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t) + ' t2 ON t.NewestID = t2.' + @id + '
WHERE t.OutValue BETWEEN OBelow AND OAbove'When deciding how to approach whether to store the entire data set without outliers or use a relational approach, if you intend to keep both sets of data, use the relational approach. In some cases, I will not keep data sets with outliers because they will create inaccuracies, and thus will eliminate the table with outliers.
Finally, we’ll end our procedure by using the procedure sp_executesql and pass in the necessary parameters:
EXEC sp_executesql @s,N'@to NVARCHAR(100)',@to END
Executing the Stored Procedure to Remove Outliers
Now, before we use this procedure, by looking at the below test data set of 13 values, we know that the value of 21 (ID 13) is over 2 standard deviations above the mean, which for the sake of this example we will define as an outlier (note that in the first picture which is a side-by-side comparison).
Here is a script to create a sample dataset:
-- create sample table CREATE TABLE [dbo].[StoValData]( [ID] [int] NULL, [StoVal] [decimal](18, 4) NULL, [AvgStoVal] [decimal](18, 4) NULL, [StDevStoVal] [decimal](18, 4) NULL, [MeanPlusTSt] [decimal](18, 4) NULL, [MeanMinusTSt] [decimal](18, 4) NULL ) ON [PRIMARY] -- insert sample data INSERT INTO [dbo].[StoValData] SELECT 1, 8.0000, NULL, NULL, NULL, NULL UNION ALL SELECT 2, 9.0000, 8.5000, 0.7071, 9.9142, 7.0858 UNION ALL SELECT 3, 8.0000, 8.3333, 0.5774, 9.4881, 7.1785 UNION ALL SELECT 4, 9.0000, 8.5000, 0.5774, 9.6548, 7.3452 UNION ALL SELECT 5, 8.0000, 8.4000, 0.5477, 9.4954, 7.3046 UNION ALL SELECT 6, 9.0000, 8.5000, 0.5477, 9.5954, 7.4046 UNION ALL SELECT 7, 8.0000, 8.4286, 0.5345, 9.4976, 7.3596 UNION ALL SELECT 8, 9.0000, 8.5000, 0.5345, 9.5690, 7.4310 UNION ALL SELECT 9, 8.0000, 8.4444, 0.5270, 9.4984, 7.3904 UNION ALL SELECT 10, 9.0000, 8.5000, 0.5270, 9.5540, 7.4460 UNION ALL SELECT 11, 8.0000, 8.4545, 0.5222, 9.4989, 7.4101 UNION ALL SELECT 12, 9.0000, 8.5000, 0.5222, 9.5444, 7.4556 UNION ALL SELECT 13, 21.0000, 9.4615, 3.5027, 16.4669, 2.4561
Here is the complete procedure to return the data to the screen for review (this is using the second block of code from above):
CREATE PROCEDURE [dbo].[stp_RemoveOutliers]
@t NVARCHAR(100), @v NVARCHAR(100), @dev DECIMAL(3,1), @sh NVARCHAR(15)
AS
DECLARE @avg NVARCHAR(250), @stdev NVARCHAR(250), @id NVARCHAR(250), @to NVARCHAR(100)
SELECT @id = COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = @t AND COLUMN_NAME LIKE 'ID%'
SELECT @avg = COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = @t AND COLUMN_NAME LIKE 'Avg%'
SELECT @stdev = COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = @t AND COLUMN_NAME LIKE 'StDev%'
SET @to = QUOTENAME(@sh) + '.' + QUOTENAME(@t + '_NoOutliers')
DECLARE @s NVARCHAR(MAX)
SET @s = @s + N';WITH OutOutlier AS(
SELECT ' + @id + ' NewestID
, ' + QUOTENAME(@v) + ' OutValue
, (' + @avg + ' + (' + @stdev + ' *' + CAST(@dev AS NVARCHAR(3)) + ')) OAbove
, (' + @avg + ' + (' + @stdev + ' *-' + CAST(@dev AS NVARCHAR(3)) + ')) OBelow
FROM ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t) + '
)
SELECT t2.*
FROM OutOutlier t
INNER JOIN ' + QUOTENAME(@sh) + '.' + QUOTENAME(@t) + ' t2 ON t.NewestID = t2.' + @id + '
WHERE t.OutValue BETWEEN OBelow AND OAbove'
EXEC sp_executesql @s,N'@to NVARCHAR(100)',@to
GO
Let’s execute our procedure using this demo table.
EXECUTE stp_RemoveOutliers 'StoValData','StoVal',2,'dbo'
Here is what our data looks like in the database and also within an Excel spreadsheet.

Here is what the data looks like after running the stored procedure to remove the outliers.
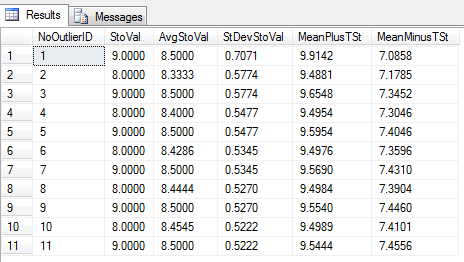
In addition to the outlier row, the row with NULLs was also removed. I’ve found that most requests to remove outliers will be individual, and this procedure simplifies it. I use non-outlier financial data quite frequently to compare with text-mining in social media to predict home purchases, incomes, and GDP growth, so I’ve used the same procedure by looping through tables and executing the procedure (see the below code). The largest test I’ve done – looping through 131 tables – completed in 4 seconds with much older equipment, an impressive job from SQL Server!
Run Stored Procedure Against Multiple Tables
DECLARE @v NVARCHAR(100) = 'Price', @sh NVARCHAR(100) = 'SHCompIND', @b INT = 1, @m INT, @t NVARCHAR(100) DECLARE @loop TABLE(LoopID INT IDENTITY(1,1), TableName NVARCHAR(100)) INSERT INTO @loop SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'SHCompIND' SELECT @m = MAX(LoopID) FROM @loop WHILE @b <= @m BEGIN SELECT @t = TableName FROM @loop WHERE LoopID = @b EXECUTE stp_RemoveOutliers @t,@v,2,@sh SET @b = @b + 1 END
Next Steps
- Test the code using the above values or your own.
- Save approach for any time those data scientists come knocking (we will)!

Tim consults for FinTek Development and teaches the course Automating ETL on Udemy. He’s worked with technology since high school, helping his school win its first TCEA award and continues to work in automation, data architecture, back-end development, and smart contract architecture. Tim enjoys testing new technologies early in the diffusion of innovation curve and was an early adopter of NoSQL and smart contract development. He has a blog at http://www.fintekdev.com/ and helps contribute to local technical and financial events in Texas.


