By: Tim Smith | Comments (4) | Related: More > Import and Export
Problem
ETL and SQL developers often import files with invalid data in those files. This has limited challenges with small file sizes, but as files grow to gigabytes worth of data, this task can be tedious. One of these forms of invalid data are lines with extra delimiters; in some cases, these extra delimiters were added to the file incorrectly, or in other cases, exist because the column value is meant to hold a delimiter.
Solution
When it comes to identifying and handling bad data, how we approach a solution will depend on our environment and the source of data. In this tip, we will use PowerShell and discuss two situations for handling bad data in the form of extra (or too little) delimiters: logging the bad data to a file and extracting only the good data from a file. For this example, we'll use two files, one called "file.txt" which has two lines with an extra delimiters and the other will be the inflationdata CSV file, where I intentionally added a line with too few delimiters.
With our first file - file.txt - note that lines 6 and 8 both have more than 2 commas, which, depending on our insert process might cause it to fail. I write might because BULK INSERT will generally accept files like this even with extra delimiters provided that the column can handle the room because the invalid values will be added to the final column (see the below image of this):
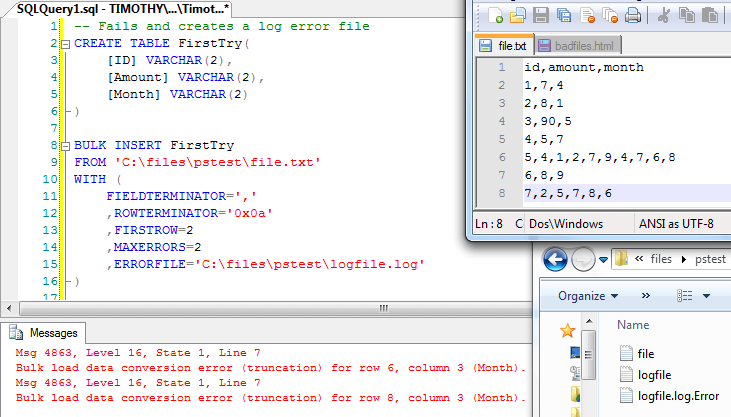
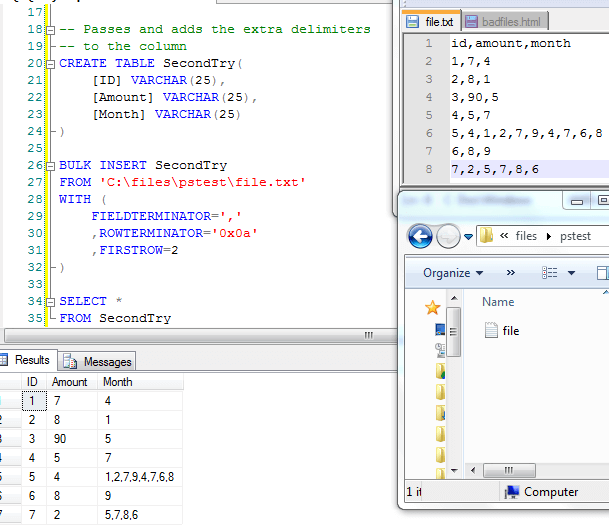
I raise this issue because I don't blame some SQL and ETL developers for thinking, "Okay, now I can just write a T-SQL solution, and bam! I'm done for the day." since the good data has been extracted and now it's a matter of removing (or logging) the bad data. I also write about this because it shows how reliable BULK INSERT is provided it has enough space; where many things fail with errors, it passes - though one should be aware of how it will handle lines with extra delimiters.
That being written, my preferred approach to handling extra-delimited data is to separate the good data from the bad data. This approach becomes useful for several reasons: (1) if we're paying a data vendor for the data, we can track what percent of the data are poorly formatted and use this for negotiation, or (2) send the data back to the vendor and have them correct the data. Why not just make an assumption? I'll explain with a short anecdote: a friend of mine who targets wealthy clients imported data from wealthy neighborhoods, and found that one neighborhood in particular, had a low "wealth average." He called and asked me for advice and I discovered in the file he imported a value of 10,,. My friend assumed the person had a wealth of $10. After speaking with the source, we discovered that the value should have been 10000000; the process had somehow replaced six zeroes with two commas.
Logging invalid data can be very useful and with PowerShell and .NET, it's very easy (and also very fast). We want to begin our function by telling it where our file is ($file), what the delimiter is ($ch) and what number of delimiters each line should have ($validCount). From there, we also want to create an invalid file ($invalid) and a valid file ($valid).
Function SeparateGoodBadLines ($file, $ch, $validCount)
{
## This allows us to just pass in the file path and automatically builds
## the location, extension and name of file
$ext = $file.Substring($file.LastIndexOf("."))
$loc = $file.Substring(0,($file.LastIndexOf("\")+1))
$name = $file.Substring($file.LastIndexOf("\")+1).Replace($ext,"")
## Creates the path for the invalid and valid files; they will retain
## the name of the original file with _valid/_invalid added to it
$valid = $loc + $name + "_valid" + $ext
$invalid = $loc + $name + "_invalid" + $ext
## Creates both the valid and invalid files
New-Item $valid -ItemType file
New-Item $invalid -ItemType file
}If you want your valid and invalid files in their own location, you would edit the second step in the above code. This code allows us to just pass in the file location; note that it gets everything we need from that, such as the file location, extension and name, as well as builds an invalid and valid file from that one parameter. Next, we want to use two of the fastest tools for reading and writing - .NET's StreamReader and StreamWriter:
$read = New-Object System.IO.StreamReader($file)
$wValid = New-Object System.IO.StreamWriter($valid)
$wInvalid = New-Object System.IO.StreamWriter($invalid)The reader ($read) will read the file while the writers ($wValid and $wInvalid) will write the separate files.
## As long as the reader can read
while (($line = $read.ReadLine()) -ne $null)
{
## Gets the number of delimiters per line
$total = $line.Split($ch).Length - 1;
## Does the total match our valid count?
if ($total -eq $validCount)
{
## Yes; write it to our valid file!
$wValid.WriteLine($line)
$wValid.Flush()
}
else
{
## No; log it to the bad file
$wInvalid.WriteLine($line)
$wInvalid.Flush()
}
}
## Clean the reader and writers
$read.Close()
$read.Dispose()
$wValid.Close()
$wValid.Dispose()
$wInvalid.Close()
$wInvalid.Dispose()While the reader reads each line, it determines if the count of characters (in this case, a comma - $ch) matches the valid count parameter we passed ($validCount) and writes the valid lines to the valid file and the invalid lines to the invalid file. Once everything is finished, we close everything and dispose them.
Our final function, therefore, will look like the below code:
Function SeparateGoodBadLines ($file, $ch, $validCount)
{
$ext = $file.Substring($file.LastIndexOf("."))
$loc = $file.Substring(0,($file.LastIndexOf("\")+1))
$name = $file.Substring($file.LastIndexOf("\")+1).Replace($ext,"")
$valid = $loc + $name + "_valid" + $ext
$invalid = $loc + $name + "_invalid" + $ext
New-Item $valid -ItemType file
New-Item $invalid -ItemType file
$read = New-Object System.IO.StreamReader($file)
$wValid = New-Object System.IO.StreamWriter($valid)
$wInvalid = New-Object System.IO.StreamWriter($invalid)
while (($line = $read.ReadLine()) -ne $null)
{
$total = $line.Split($ch).Length - 1;
if ($total -eq $validCount)
{
$wValid.WriteLine($line)
$wValid.Flush()
}
else
{
$wInvalid.WriteLine($line)
$wInvalid.Flush()
}
}
$read.Close()
$read.Dispose()
$wValid.Close()
$wValid.Dispose()
$wInvalid.Close()
$wInvalid.Dispose()
}Now let's call our function:
SeparateGoodBadLines -file "C:\files\pstest\file.txt" -ch "," -validCount 2
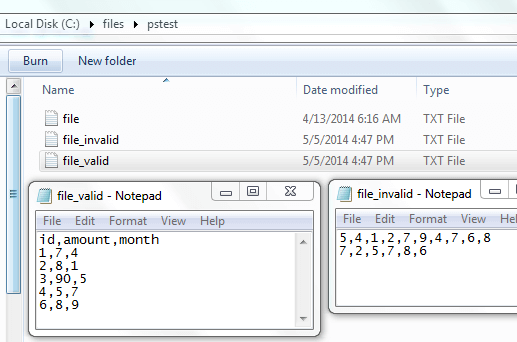
Now, let's grab our 4MB inflation data CSV file and add a bad line of data with only one delimiter, then call our function and see what we have:
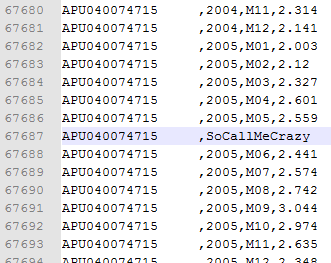
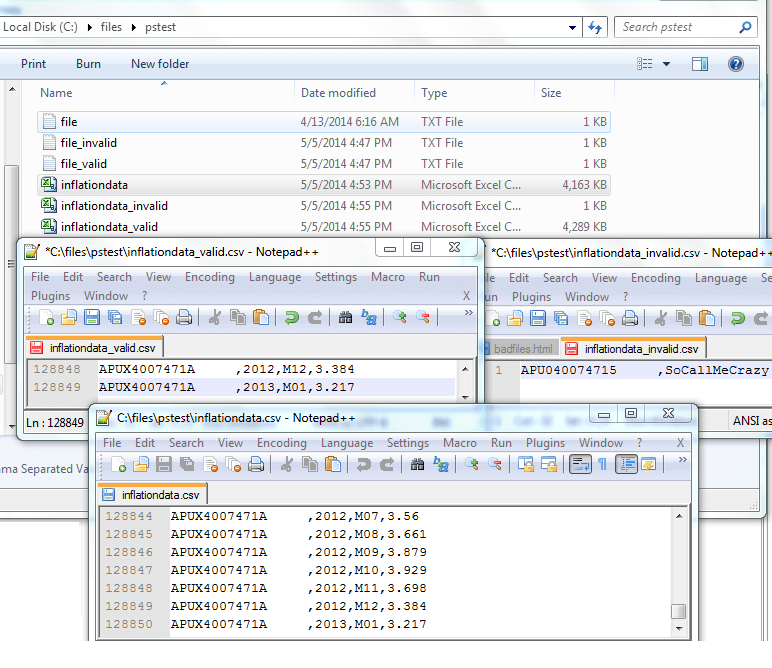
As you can see, it wrote the one bad line to the invalid file and wrote the remaining to the valid file. For those who prefer a C# solution, I have a similar method for the class on this GitHub file called OutputInvalidandValidData.
Quick data validation in the case of delimiters can save major headaches. I've witnessed developers spending full weeks trying to go through large files finding those few lines it breaks and then identifying why it does so. Even if you want to keep the bad lines, it's much faster to log them, know what they are and build a process to handle them. That being written, I'd highly suggest contacting the data vendor (or source) as to why they format doesn't line up because assumptions with data can be very dangerous in some situations.
Next Steps
- Test the above code, or derivatives of the above code, in your environment.
- Use the above code for pre-validating files before import.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
