By: Daniel Farina | Comments | Related: > In Memory OLTP
Problem
As you may know, SQL Server In-Memory OLTP introduced in SQL Server 2014 offers great performance improvements for ETL processes. In this tip we cover techniques you need to know about various behaviors of SQL Server In-Memory OLTP depending on the options you select.
Solution
One of the many situations in which we can get a benefit from SQL Server In-Memory OLTP objects is ETL scenarios. We can load data to an In-Memory table defined as non-durable to use it as a staging table to process data by taking advantage of Natively Compiled Stored Procedures or using standard SQL. We can even use an In-Memory table as a final destination and take advantage of the lock free and latch free concurrency mechanisms of the Hekaton Engine which will allow us to load data into an OLTP production table without affecting other user’s transaction performance.
But when talking about SSIS package performance I hear the same question: which connection adapter is better, ADO NET, OLE DB or ODBC. To add more confusion to this matter, in 2011 the Microsoft’s official blog “SQL Server Blog” posted an article entitled “Microsoft Aligning with ODBC” in which it states that OLEDB will be deprecated in a future release of SQL Server.
The fact is that we can use ADO NET, OLE DB or ODBC sources in Data Flow tasks to retrieve data from Memory-Optimized tables. We can even use a query or Stored Procedure joining both Memory-Optimized and disk based tables as a data source with those adapters. The same goes for destinations in Data Flow tasks, the ADO NET, OLE DB and ODBC can be used to store data into Memory-Optimized Tables as well.
That shouldn’t be a surprise because we already know that Hekaton, the In-Memory OLTP engine of SQL Server 2014 is fully integrated into the standard relational engine of SQL Server, but there are a few things you need to know.
What about Natively-Compiled Stored Procedures?
As I mentioned in previous tips, Natively-Compiled Stored Procedures have some usage restrictions, amongst them is the lack of support for system cursors which may be used by some data sources like ODBC. Further on I will show you an example and a workaround.
The other difficulty we may face is if we are using an ADO.NET source to execute a Natively-Compiled Stored Procedure. That’s because the SqlClient Data Provider, the default for ADO.Net, has some issues with the execution of Natively-Compiled Stored Procedures. Because of this, if you want to use an ADO.Net connection, you should use other .Net provider, like OLEDB or ODBC.
Import SQL Server Data with a Natively Compiled Stored Procedure
For the purpose of this tip I will show how to import data from a Natively-Compiled Stored Procedure.
First we create our sample Database.
USE [master]
GO
CREATE DATABASE [SampleDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'SampleDB_file1',
FILENAME = N'E:\MSSQL\SampleDB_1.mdf',
SIZE = 128MB ,
MAXSIZE = UNLIMITED,
FILEGROWTH = 64MB),
FILEGROUP [SampleDB_MemoryOptimized_filegroup]
CONTAINS MEMORY_OPTIMIZED_DATA DEFAULT
( NAME = N'SampleDB_MemoryOptimized',
FILENAME = N'E:\MSSQL\SampleDB_MemoryOptimized',
MAXSIZE = UNLIMITED)
LOG ON
( NAME = N'SampleDB_log_file1',
FILENAME = N'E:\MSSQL\SampleDB_1.ldf',
SIZE = 64MB,
MAXSIZE = 2048GB,
FILEGROWTH = 32MB)
GO
Now we create a Memory-Optimized table so we can next use it with a Natively-Compiled Stored Procedure and a disk based table that will be used as a destination for the Data Flow Tasks.
USE SampleDB
GO
IF OBJECT_ID('dbo.SampleTable','U') IS NOT NULL
DROP TABLE dbo.SampleTable
GO
CREATE TABLE SampleTable
(
ID INT IDENTITY(1,1)
SomeNumber INT,
SomeChar VARCHAR(500)
CONSTRAINT PK_SampleTable
PRIMARY KEY NONCLUSTERED HASH ( id )
WITH ( BUCKET_COUNT = 262144 )
) WITH (MEMORY_OPTIMIZED =
ON,
DURABILITY = SCHEMA_AND_DATA)
GO
IF OBJECT_ID('dbo.Destination','U') IS NOT NULL
DROP TABLE dbo.Destination
GO
CREATE TABLE Destination
(
RID INT IDENTITY (1,1),
ID INT ,
SomeNumber INT,
SomeChar VARCHAR(500)
CONSTRAINT PK_Destination
PRIMARY KEY CLUSTERED ( RID )
)
GO
The next script will generate some random test data.
USE SampleDB
GO
INSERT INTO dbo.SampleTable
( SomeNumber, SomeChar )
SELECT checksum (NEWID() ),
cast (NEWID() AS VARCHAR(100) )
GO 5000
This is the code for the Natively-Compiled Stored Procedure we will use for the test. It is a very simple code that performs a SELECT to our previously created Memory-Optimized Table and divides the value of SomeNumber column by the number specified in the Procedure’s Parameter.
USE SampleDB
GO
IF OBJECT_ID('dbo.SampleSP','P') IS NOT NULL
DROP PROCEDURE dbo.SampleSP
GO
CREATE PROCEDURE dbo.SampleSP
@Param int
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS BEGIN ATOMIC WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english'
)
IF @Param <> 0
BEGIN
SELECT ID ,
SomeNumber / @Param AS SomeNumber ,
SomeChar
FROM dbo.SampleTable
END
ELSE
BEGIN
;THROW 51000, 'Invalid Parameter', 1;
END
END
GO
Setting up the SSIS project
I created three Data Sources: An OLEDB, ADO.NET and ODBC Sources respectively and added one Data Flow Task for each source. Look at the next image for a clearer view.
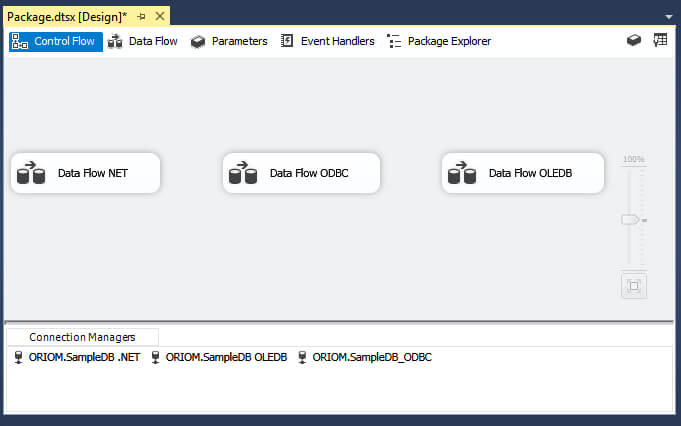
After this we configure the source to execute our previously created Stored Procedure. We have two ways to enter the statement for the Stored Procedure execution, by using the EXEC keyword or without it. If you keep reading you will find that these two ways can change the behavior of some providers. Now I will show you how the different sources behave.
Using OLEDB Source with Natively-Compiled Stored Procedures
On the next image you can see that the query parsed successfully.
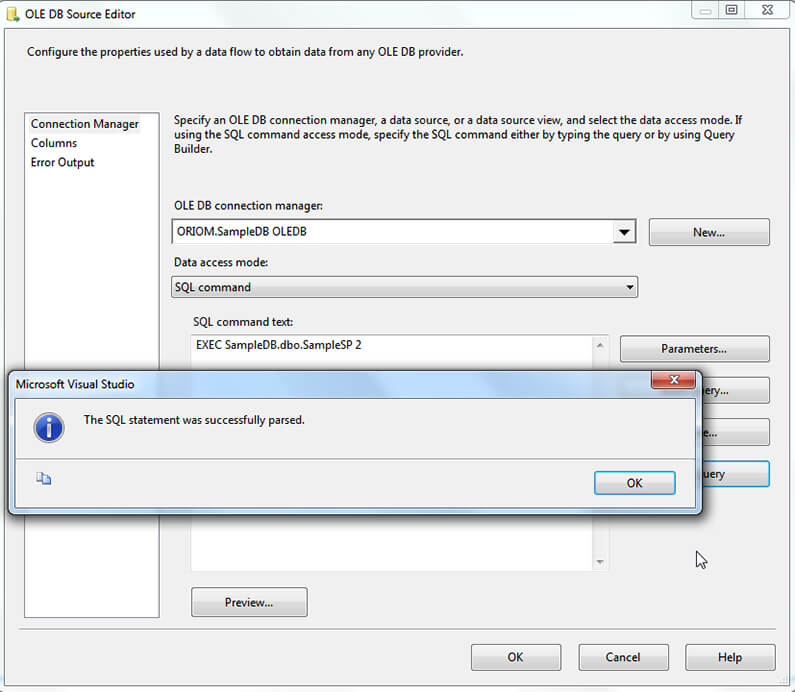
Also you can see below, we can see column metadata information.
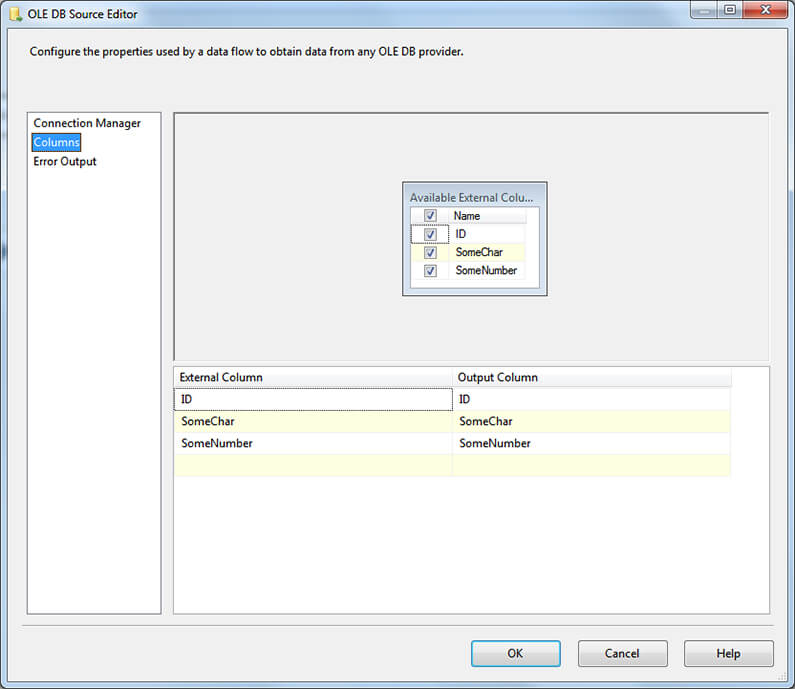
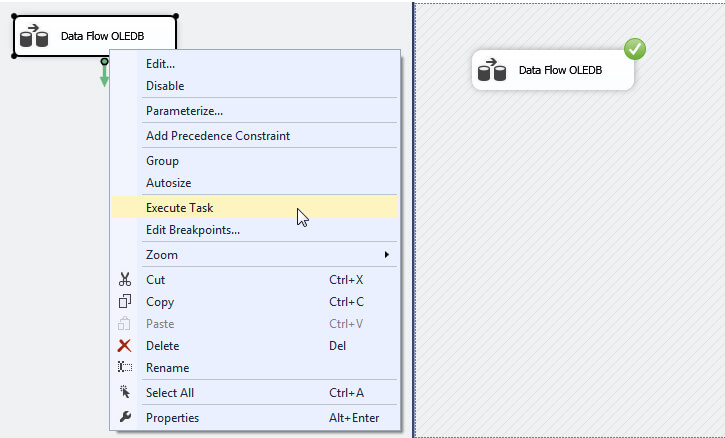
The next step is to setup the flow destination to the disk based table we have created earlier. After that is complete you can right click on the Data Flow Task and select Execute Task on the context menu. The task should execute with no problems.
Using ADO.NET Source in SSIS with Natively-Compiled Stored Procedures
Now for the ADO.NET source, things are a little different. You can see on the next screen capture that ADO.NET is unable to return column information even when it can execute the procedure to return a preview of the data.
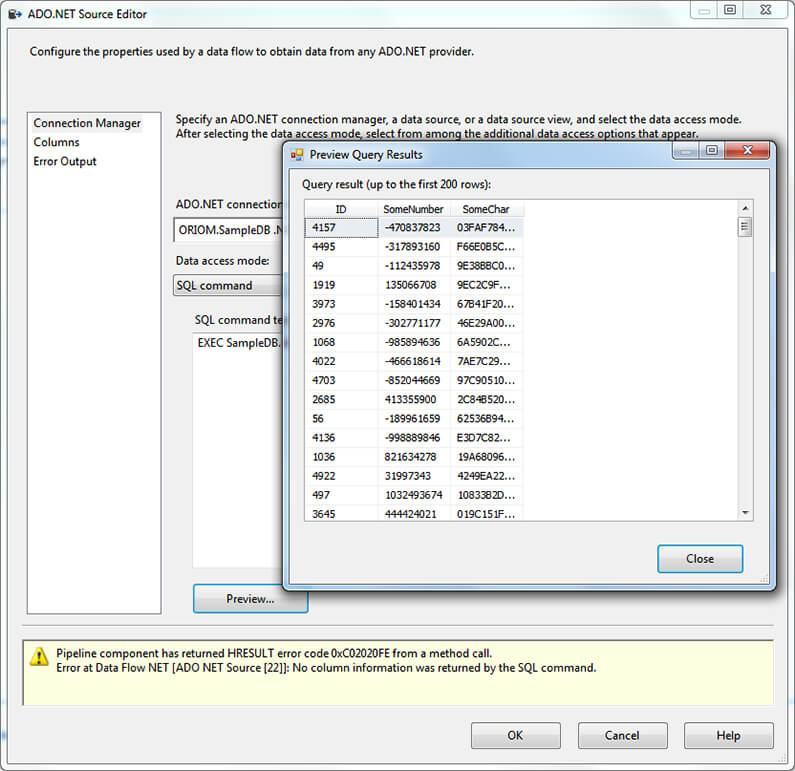
I configured a Profiler session to show why this source doesn’t give column information. You can see that in order to get metadata information this source executes the statement with the SET FMTONLY option enabled which is not supported for Natively-Compiled Stored Procedures and is deprecated in favor of sp_describe_first_result_set.
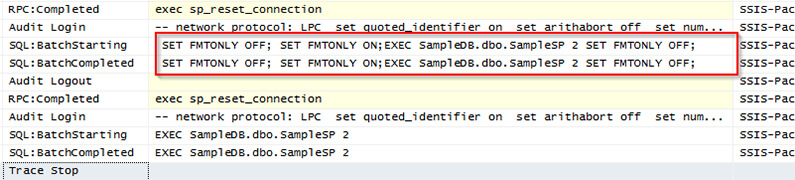
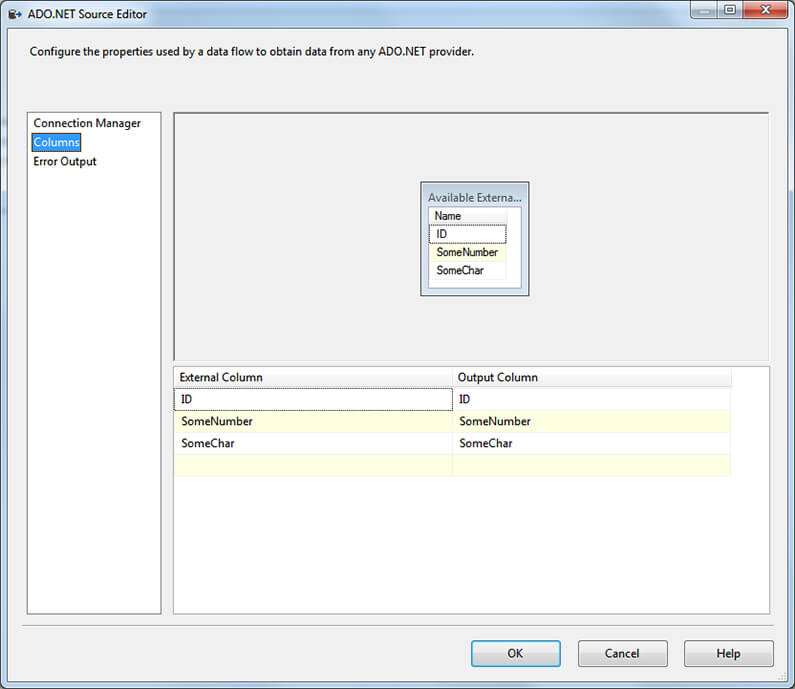
But there is a way to use an ADO.NET source by changing the provider to SQL Server Native Client 11. Older versions of this provider won’t work because these also use the SET FMTONLY option to get query metadata.
Something I must add is that when you use SQLClient Data provider to execute any kind of Stored Procedure and omit the EXEC keyword you will get a message complaining about Incorrect Syntax as shown below.
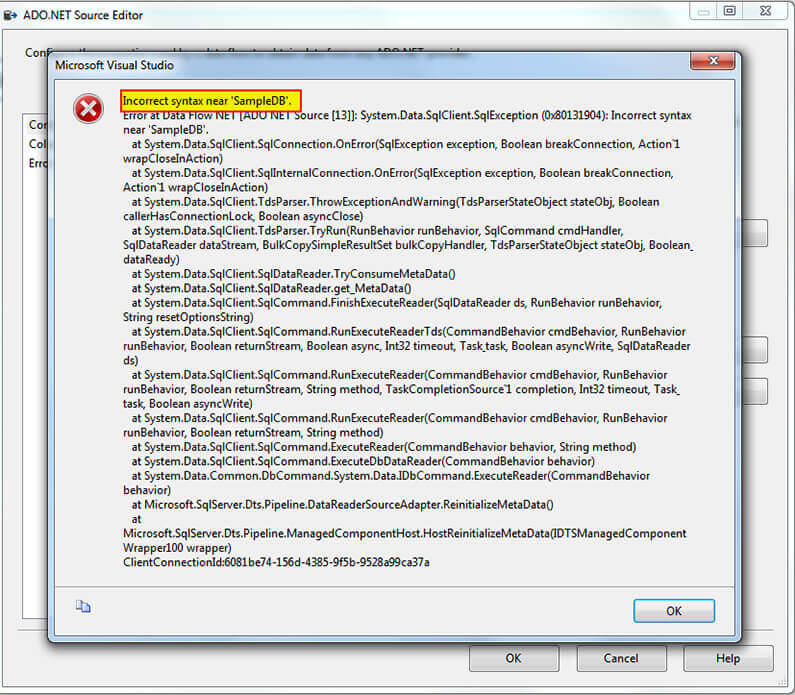
That’s easy to notice if you look at the previous Profiler capture; look at the next code fragment showing how ADO.NET builds both queries.
USE SampleDB GO --Well formed Statement SET FMTONLY OFF; SET FMTONLY ON;EXEC SampleDB.dbo.SampleSP 2 SET FMTONLY OFF; go --Incorrect Statement SET FMTONLY OFF; SET FMTONLY ON;SampleDB.dbo.SampleSP 2 SET FMTONLY OFF; go
The only way to execute a Stored Procedure without the EXEC keyword is if it is the only command in the batch.
Using an ODBC Source in SSIS with Natively-Compiled Stored Procedures
As you can see on the next image the query parses with no problem.
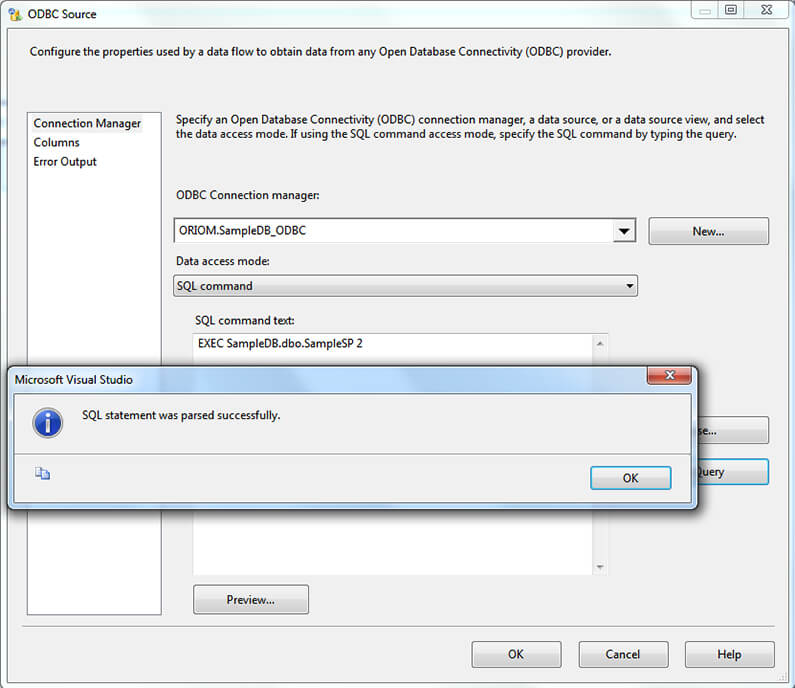
But when executing the Data Flow it fails with error “Cursors are not supported with natively compiled stored procedures”. Let’s see the Profiler capture to get the executed statement so we can see what's going on.
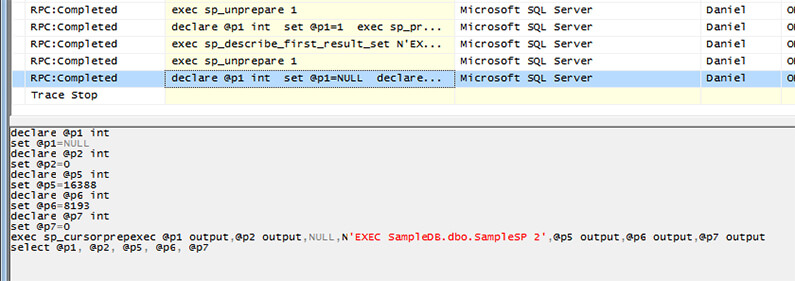
On the previous image you can see that the ODBC source executed the sp_cursorprepexec, to open a cursor which is not supported for Natively-Compiled Stored Procedures.
To get a clearer view of the query, you can execute it to get the same error message that the Data Flow execution gets.
declare @p1 int set @p1=NULL declare @p2 int set @p2=0 declare @p5 int set @p5=16388 declare @p6 int set @p6=8193 declare @p7 int set @p7=0 exec sp_cursorprepexec @p1 output,@p2 output,NULL,N'EXEC SampleDB.dbo.SampleSP 2' ,@p5 output,@p6 output,@p7 output select @p1, @p2, @p5, @p6, @p7
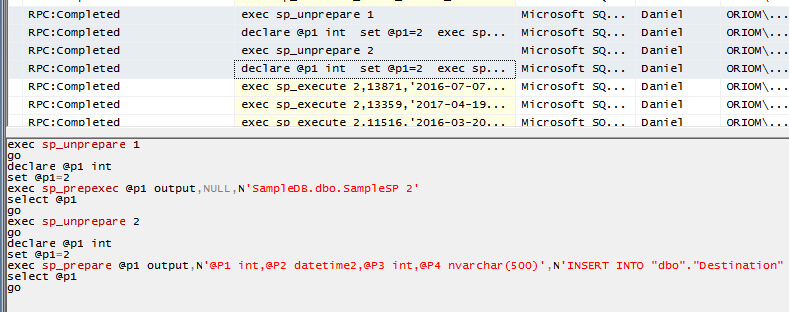
When using the EXEC keyword the ODBC connection manager interprets the SQL command as a Transact-SQL statement rather than a stored procedure and uses a cursor. After modifying the statement to not include the EXEC keyword the Data Flow executes successfully.
Here is a Profiler screen capture showing how the ODBC Source executes our Natively-Compiled Stored Procedure when we don’t use the EXEC keyword. As you can see, there is no cursor operation because instead of executing the Stored Procedure using sp_cursorprepexec the ODBC Source uses sp_prepexec
Next Steps
- You can download a copy of the SSIS project used in this tip here.
- Also you may need to get a copy of Microsoft SQL Server Data Tools - Business Intelligence for Visual Studio 2013.
- If you are new to Natively-Compiled Stored Procedures then my previous tip Migrate to Natively Compiled SQL Server Stored Procedures for Hekaton would be a starting point.
- You can get more information about tuning or troubleshooting Package connections on this tip: SQL Server Integration Services Connection Manager Tips and Tricks.
- In this tip you will see how to configure Resource Governor to handle Workloads: Handling workloads on SQL Server 2008 with Resource Governor.
- Stay tuned for more tips in the Integration Services Data Flow Transformations Tips Category.






About the author
 Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.
Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
