By: Percy Reyes | Comments (11) | Related: > In Memory OLTP
Problem
In-Memory OLTP is a new feature of Microsoft SQL Server 2014 that was born in response to business and hardware trends. But how fast is it? How we can use it to optimize OLTP transactions? Why it is faster than transactions on disk based tables?
Solution
Microsoft SQL Server 2014 In-Memory OLTP offers high performance, it was built to take full advantage of memory and processor cores installed on the database server, it also is oriented to OLTP scenarios and full integrated into SQL Server. Memory optimized tables, stored procedures and indexes are now available for high-throughput OLTP and transactions on memory optimized tables are also introduced with this new great feature. In this tip I will explain a short example to show the performance differences for INSERT transactions on memory optimized tables vs. disk based tables. Note that the tests were conducted on a virtual machine with 4.5GB RAM and 4 cores.
For our example, we will create one In-Memory stored procedure and table versus one disk based Stored Procedure and table. We will start off by creating an In-Memory database that needs at least one the memory optimized Filegroup and include the CONTAINS MEMORY_OPTIMIZED_DATA option to store one or more containers for data files or delta files or both. We can only create one memory optimized Filegroup per database. In our example the memory optimized Filegroup is named "INMEMORYDB_FILEGROUP" and it holds only one container named "INMEMORYDB_CONTAINER".
CREATE DATABASE [INMEMORYDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'INMEMORYDB', FILENAME = N'D:\SQLDATA\INMEMORYDB_Data01.mdf',
SIZE = 1GB, MAXSIZE = UNLIMITED, FILEGROWTH = 2GB), FILEGROUP [INMEMORYDB_FILEGROUP] CONTAINS MEMORY_OPTIMIZED_DATA DEFAULT (NAME = N'INMEMORYDB_CONTAINER', FILENAME = N'D:\INMEMORYDB_CONTAINER', MAXSIZE = UNLIMITED) LOG ON (NAME = N'INMEMORYDB_log', FILENAME = N'E:\SQLLog\INMEMORYDB_Log.ldf',
SIZE = 1GB, MAXSIZE = 2048GB, FILEGROWTH = 1GB)
Now we will create the In-Memory table Product_InMemory and then the On-Disk table Product_OnDisk as follow:
CREATE TABLE [dbo].[Product_InMemory] ([ProductID] [int] IDENTITY(1,1) NOT NULL NONCLUSTERED PRIMARY KEY HASH WITH (BUCKET_COUNT=3000000), [ProductName] [nvarchar](40) NOT NULL, [SupplierID] [int] NOT NULL INDEX [IX_SupplierID] HASH WITH (BUCKET_COUNT=3000000), [CategoryID] [int] NOT NULL INDEX [IX_CategoryID] HASH WITH (BUCKET_COUNT=3000000), [QuantityPerUnit] [nvarchar](20) NULL, [UnitPrice] [money] NULL DEFAULT ((0)), [UnitsInStock] [smallint] NULL DEFAULT ((0)), [UnitsOnOrder] [smallint] NULL DEFAULT ((0)), [ReorderLevel] [smallint] NULL DEFAULT ((0)), [Discontinued] [bit] NOT NULL DEFAULT ((0)) ) WITH (MEMORY_OPTIMIZED=ON) GO CREATE TABLE [dbo].[Product_OnDisk] ([ProductID] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED , [ProductName] [nvarchar](40) NOT NULL, [SupplierID] [int] NOT NULL INDEX [IX_SupplierID] NONCLUSTERED , [CategoryID] [int] NULL INDEX [IX_CategoryID] NONCLUSTERED, [QuantityPerUnit] [nvarchar](20) NULL, [UnitPrice] [money] NULL DEFAULT ((0)), [UnitsInStock] [smallint] NULL DEFAULT ((0)), [UnitsOnOrder] [smallint] NULL DEFAULT ((0)), [ReorderLevel] [smallint] NULL DEFAULT ((0)), [Discontinued] [bit] NOT NULL DEFAULT ((0)) )
As you can see in the script above the table Product_InMemory must be marked as In-Memory using "MEMORY_OPTIMIZED" clause. You can also see we have created three HASH indexes. They are a new type of In-Memory OLTP index used to optimize the performance of queries on memory-optimized tables. To learn more about indexing, check out these two tips Getting started with Indexes on SQL Server Memory Optimized Tables and Understanding SQL Server Memory-Optimized Tables Hash Indexes.
Now we will create the In-Memory OLTP stored procedure usp_ProductInsert_InMemory to insert data into the In-Memory table Product_InMemory. This stored procedure has new syntax including the with NATIVE_COMPILATION clause so the object is marked to be natively compiled then loaded into the memory. It also must be bound to the schema of the objects it references by using SCHEMABINDING clause, and with "EXECUTE AS OWNER" to set the default execution context. Finally, it must set the atomic block that has two options required: the isolation level and the language. In our example we will use "SNAPSHOT" and as language "us_english". You can read more about these options with these two tips - Migrate to Natively Compiled SQL Server Stored Procedures for Hekaton and SQL Server 2014 In Memory OLTP Durability, Natively Compiled Stored Procedures and Transaction Isolation Level.
--In-Memory OLTP Stored Procedure to modify In-Memory Table CREATE PROCEDURE dbo.usp_ProductInsert_InMemory(@InsertCount int ) WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL=SNAPSHOT, LANGUAGE=N'us_english') DECLARE @SupplierID int=1, @CategoryID int=1 DECLARE @Start int=1 WHILE @Start<@InsertCount BEGIN INSERT INTO dbo.Product_InMemory(ProductName, SupplierID, CategoryID, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued ) SELECT 'NewProduct_' + CAST(@Start AS VARCHAR(10)),@SupplierID,@CategoryID, 1,1,1,1,1,1 IF @SupplierID=10 SET @SupplierID=0 IF @CategoryID=8 SET @CategoryID=0 SET @SupplierID=@SupplierID+1 SET @CategoryID=@CategoryID+1 SET @Start=@Start+1 END END
At this time we create the disk based stored procedure named usp_ProductInsert_OnDisk as follows:
-- OnDisk-Based Stored Procedure to modify OnDisk Table CREATE PROCEDURE dbo.usp_ProductInsert_OnDisk(@InsertCount int ) AS BEGIN DECLARE @SupplierID int=1, @CategoryID int=1 DECLARE @Start int=1 WHILE @Start<@InsertCount BEGIN INSERT INTO dbo.Product_OnDisk(ProductName, SupplierID, CategoryID, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued ) SELECT 'NewProduct_' + CAST(@Start AS VARCHAR(10)),@SupplierID,@CategoryID, 1,1,1,1,1,1 IF @SupplierID=10 SET @SupplierID=0 IF @CategoryID=8 SET @CategoryID=0 SET @SupplierID=@SupplierID+1 SET @CategoryID=@CategoryID+1 SET @Start=@Start+1 END END
Now it's time to execute both stored procedures and record the performance metrics. As you can see in the next screenshot the In-Memory stored procedure (usp_ProductInsert_InMemory) took just five seconds to insert 1000000 rows into the In-Memory table Product_InMemory. This is because the objects and processing is in memory, so the process does not needed to write directly to disk so there are no latches, no locking, minimal context switches, any type of contentions, etc. I have used SET STATISTICS IO ON to display activity from disk, but you can see there is no I/O disk activity, only CPU activity. The stored procedure and table are loaded totally in memory and everything works directly in memory.
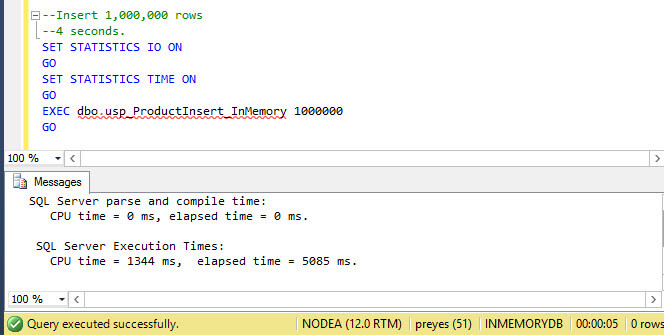
You can see now in the next screenshot that the execution of the table based stored procedure (usp_ProductInsert_OnDisk) took 9 minutes and 13 seconds to insert 1000000 rows into the disk based table Product_OnDisk. Why is it so much slower? It is because each INSERT operation works directly on disk and in this situation the operation has to deal with latches, locking, logging and additional contention issues.
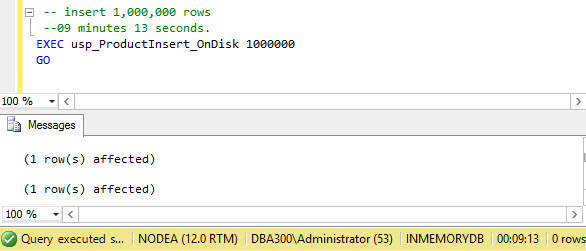
Based on this example, we can see that In-Memory OLTP objects are about 10-30x more efficient than disk based objects.
Next Steps
- Read these additional articles related to In-Memory OLTP
- Compare SQL Server Performance of In-Memory vs Disk Tables
- Comparing Performance of In Memory table vs Regular Disk Table Part 2
- Getting started with the AMR tool for migration to SQL Server In-memory OLTP Tables
- SQL Server 2014 In Memory OLTP Durability, Natively Compiled Stored Procedures and Transaction Isolation Level
- Overview of Applications, Indexes and Limitations for SQL Server 2014 In-Memory OLTP Tables
- Monitor Memory Consumption for SQL Server Memory Optimized Tables






About the author
 Percy Reyes is a SQL Server MVP and Sr. Database Administrator focused on SQL Server Internals with over 10+ years of extensive experience managing critical database servers.
Percy Reyes is a SQL Server MVP and Sr. Database Administrator focused on SQL Server Internals with over 10+ years of extensive experience managing critical database servers.
This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
