Problem
While troubleshooting a performance issue in my SQL Server instance I noticed a high percentage of RESOURCE_SEMAPHORE waits. This wait type indicates contention for memory resources by concurrent queries requesting memory grants due to Hash-Match and/or Sort operations. I need to be able to keep an eye on such resource-hungry queries (and their memory-grant allocations) so as to take steps to optimize performance and concurrency. I would also like to identify queries using parallelism, as these are also memory consuming.
Solution
Starting with SQL Server 2016 CTP 2.0, and back-ported to SQL Server 2012 SP3, it is now possible to identify memory-grant allocations and parallelism operations in the plan cache with the sys.dm_exec_query_stats DMV. Prior to that, one had to resort to cumbersome XQuery manipulations to interrogate the cache-plan XML for specific signatures of these operations, after the fact, or capture them on the fly with the sys.dm_exec_query_memory_grants DMV. As a result, it was difficult to correlate this data with other performance characteristics returned by sys.dm_exec_query_stats, such as query execution counts, IOs and elapsed times. Being able to retrieve all this information from one source now simplifies this analysis.
The Workload
To demonstrate, I am running a workload of 7 SELECT queries on a copy of the AdventureWorks2014 database upgraded to compatibility level 130 (SQL Server 2016). My SQL Server instance is on version SQL Server 2016 CTP3.2. I have set the maximum degree of parallelism (MAXDOP) to 4 at the instance level, on a machine with 8 logical CPUs.
- Query 1 is a SELECT statement on the Production.Product table with a WHERE clause and a SORT; it is executed 50 times.
- Query 2 executes a join of tables Production.Product and Sales.SalesOrderDetail, followed by a SORT on ProductName.
- Queries 3-5 are variations of Query 2, in each of which I explicitly set the MAXDOP to 3, 2 and 1, respectively.
- Queries 6 and 7 are also variations of Query 2, representing cardinality under- and over-estimates, respectively, of rows in table Sales.SalesOrderDetail.
The faulty estimates are achieved by running UPDATE STATISTICS on that table prior to each query and explicitly specifying extremely low or high values of row/page counts. This in effect distorts the cardinally estimates produced by the query optimizer from the proper values in each case. (I got that idea here.) At the end of the batch, I restore the statistics of the table to the true values of row and page counts.
Here is the workload batch:
-----------
--Script 1:
-----------
--https://msdn.microsoft.com/en-us/library/ms187731.aspx
USE [AdventureWorks2014];
GO
--Query 1:
SELECT Name, ProductNumber, ListPrice
FROM Production.Product
WHERE ProductLine = 'R' AND DaysToManufacture < 4
ORDER BY Name ASC;
GO 50
--Query 2:
SELECT p.Name AS ProductName, sod.OrderQty, sod.SalesOrderID
FROM Production.Product AS p
INNER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC;
GO
--Query 3:
SELECT p.Name AS ProductName, sod.OrderQty, sod.SalesOrderID
FROM Production.Product AS p
INNER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC
OPTION (MAXDOP 3);
GO
--Query 4:
SELECT p.Name AS ProductName, sod.OrderQty, sod.SalesOrderID
FROM Production.Product AS p
INNER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC
OPTION (MAXDOP 2);
GO
--Query 5:
SELECT p.Name AS ProductName, sod.OrderQty, sod.SalesOrderID
FROM Production.Product AS p
INNER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC
OPTION (MAXDOP 1);
GO
--Produce cardinality under-estimate by skewing stats way down:
UPDATE STATISTICS Sales.SalesOrderDetail
WITH ROWCOUNT = 100, PAGECOUNT = 10;
GO
--Query 6:
SELECT p.Name AS ProductName, sod.OrderQty, sod.SalesOrderID
FROM Production.Product AS p
INNER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC;
GO
--Produce cardinality over-estimate by skewing stats way up:
UPDATE STATISTICS Sales.SalesOrderDetail
WITH ROWCOUNT = 1000000000, PAGECOUNT = 1000000;
GO
--Query 7:
SELECT p.Name AS ProductName, sod.OrderQty, sod.SalesOrderID
FROM Production.Product AS p
INNER JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC;
GO
--Return stats back to normal:
UPDATE STATISTICS Sales.SalesOrderDetail
WITH ROWCOUNT = 121317, PAGECOUNT = 1323;
GOResults
I first clean out the plan cache and execute the above batch. Once execution is completed, I check the results from sys.dm_exec_query_stats:
-----------
--Script 2:
-----------
SELECT TOP( 10 )
qs.execution_count AS [Execution Count]
,t.[text] AS [Query Text]
,qs.[last_grant_kb]
,qs.[last_ideal_grant_kb]
,qs.[last_used_grant_kb]
,qs.[total_grant_kb]
,qs.[last_dop]
,qs.[last_used_threads]
FROM
sys.dm_exec_query_stats AS qs WITH (NOLOCK)
CROSS APPLY
sys.dm_exec_sql_text(plan_handle) AS t
WHERE
DB_NAME(t.[dbid]) = 'AdventureWorks2014'
AND qs.[total_grant_kb] > 0
ORDER BY
qs.[total_grant_kb] DESC
OPTION (RECOMPILE);Script 2 returns the top 10 queries with memory-grant allocations in the plan cache for database AdventureWorks2014, sorted by total memory grant (total_grant_kb column) per query over its lifetime in the cache. Since all 7 queries in the present workload contain an ORDER BY clause, they are all expected to be in that list.
Here is the output:
Execution Count | Query Text | total_ | last_ | last_ideal_ | last_used_ | last_ | last_used_ |
|---|---|---|---|---|---|---|---|
1 | –Query 7: SELECT p.Name AS ProductName, … | 182992 | 182992 | 130827744 | 13152 | 4 | 8 |
50 | –Query 1: SELECT Name, ProductNumber, … | 51200 | 1024 | 672 | 16 | 1 | 0 |
1 | –Query 2: SELECT p.Name AS ProductName, … | 23808 | 23808 | 23808 | 13064 | 4 | 8 |
1 | –Query 3: SELECT p.Name AS ProductName, … | 21936 | 21936 | 21936 | 12624 | 3 | 6 |
1 | –Query 4: SELECT p.Name AS ProductName, … | 20128 | 20128 | 20128 | 12760 | 2 | 4 |
1 | –Query 5: SELECT p.Name AS ProductName, … | 18240 | 18240 | 18240 | 11848 | 1 | 0 |
1 | –Query 6: SELECT p.Name AS ProductName, … | 1600 | 1600 | 1600 | 1312 | 1 | 0 |
There are some interesting observations to draw from these results (values of interest bolded).
To begin with, Query 7 is at the top of the list. This was the query executed after the optimizer was tricked into a hugely inflated estimate of the number of rows in table Sales.SalesOrderDetail. Recall that this is when I tricked the optimizer by running UPDATE STATISTICS on the SalesOrderDetail table with a row count of 1 billion and a page count of 1 million. As a result, the ideal memory grant of this query (last_ideal_grant_kb column) was estimated at 130,827,744 KB (~131 GB !), with only 182,992 KB memory actually granted (last_grant_kb column). In my SQL instance configured to 1 GB of max memory, of which most is taken up by the buffer cache, 183 MB of memory is a huge chunk of the work buffer available.
Second, Query 6 is at the bottom of the list. Query 6 is the exact opposite of Query 7; here I had convinced the optimizer that the SalesOrderDetail table was very small (100 rows over 10 pages). There is still a memory grant, due to the SORT and HASH-MATCH operations in the plan, but it is relatively small (1,600 KB). This cardinality under-estimate has another consequence: because the memory-grant size was too small to satisfy the query, intermediate results were spilled to disk, as witnessed by the warnings on the Hash-Match and Sort operators:

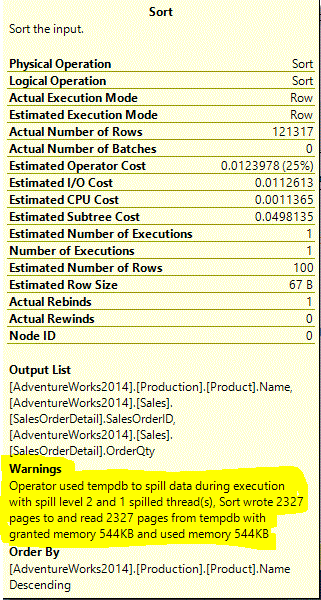
Next, Query 1 is second in the list, due to its large number of executions (50), even though the memory grant for individual executions was small (1,024 KB). This underlies the importance of including the frequency of query execution when analyzing the performance characteristics of a workload.
Query 2 comes third, followed by its variants where I had explicitly set the MAXDOP to 3, 2 and 1 (Queries 5, 4 and 3). Memory-grant values (last_grant_kb column) get progressively lower as the degree of parallelism (last_dop column) is reduced from 4 to 1: from 23,808 MB (Query 2) to 18,240 MB (Query 5). We can see that parallelism directly affects the size of a memory grant, so it is essential for good overall server performance that only those queries that would truly benefit from parallel execution be permitted to do so.
Two final observations are with regards to the last_used_grant_kb and last_used_threads columns. First, the last_used_grant_kb values are always lower than the actual grants given (last_grant_kb). It seems that, at least in this example, SQL Server is not making as efficient a use of the memory grants allocated as one might expect. This is especially evident with Query 1, where a default (I assume) memory grant of 1,024 KB is allocated for a requested 672 KB and an eventually used 16 KB. Even though the memory grant is quite small in this case, we can see how these allocations would pile up in a real-world scenario and why it is important to pay heed to the existence of SORT operations and SORT warnings in query plans. Finally, the last_used_threads vs. last_dop values (when last_dop > 1) tell us something about the anatomy of the query plans involved. For example, the plan of Query 2 below consists of two branches, both containing Parallelism operators, resulting in the number of used threads (8) being twice that of the degree of parallelism (4):

Conclusion
In this tip I have shown how to use the new capabilities of the sys.dm_exec_query_stats DMV to understand in depth how a SQL Server instance uses work-buffer memory for memory-grant allocations. This understanding is crucial for troubleshooting concurrency bottlenecks among memory-intensive queries and tracking performance issues such as tempdb spills, cardinality over-estimates and uninhibited query parallelism.
Next Steps
- Apply the solution outlined in this tip to your environment to obtain a list of the top queries with memory-grant allocations.
- Review these related links to learn more about memory grants and the sys.dm_exec_query_stats DMV:
- Understanding SQL server memory grant
- sys.dm_exec_query_stats (Transact-SQL)
- Troubleshooting SQL Server RESOURCE_SEMAPHORE Waittype Memory Issues
- Never Ignore a Sort Warning in SQL Server
- Correct SQL Server TempDB Spills in Query Plans Caused by Outdated Statistics
- Add Memory Grants columns to sys.dm_exec_query_stats – by RobNicholson, MCSM
- sys.dm_exec_query_memory_grants (Transact-SQL)
- Improved memory grant diagnostics when you use DMV in SQL Server 2012
- SQL Server 2012 SP3 Adds Memory Grant and Performance Features

Marios Philippopoulos has been a SQL Server DBA and developer for over 10 years. In a previous life he was a computational chemist conducting simulations of protein dynamics. He is based in the Toronto area, Ontario, Canada.


