Problem
I am working to improve the performance of a piece of SQL Server T-SQL code and I need to know if an index will help. If so, what index? Can I get SQL Server to tell me? If I make the index, can I prove that the new index was used?
Solution
The answer is an emphatic yes! SQL Server can help advise if an index will help a query run faster. It can even estimate how much the index will help. The best way to determine this is to use the query execution plan. This tip will walk through how to generate, view, and read an execution plan for this purpose. It will also show how to act upon any advice offered by the execution plan.
All of the demos in this tip will use the WideWorldImporters sample database which can be downloaded from here.
Sample Query
Consider this query:
SELECT InvoiceDate
FROM [WideWorldImporters].[Sales].[Invoices]
WHERE InvoiceDate = '2014-03-15';
Will the execution of this query use an index? If not, will adding one help?
This prior tip walks through several ways to measure query performance. It ends by adding an index to this same query and seeing that the query started executing significantly faster. This tip will explain how the author knew to take that action.
Note: For this tip, the index that was created at the end of that tip has been removed and the database therefore returned to its original state.
Generating and reading a SQL Server Execution Plan
There are 2 types of execution plans that can be used to help performance tune a query. They are the estimated execution plan and the actual execution plan.
The estimated execution plan can be viewed without executing the query and the actual requires the query be executed to completion before it can be viewed. The actual execution plan is almost always preferred because it is generally more accurate. The estimated plan should only be used in a situation where the query cannot be run because it would take too long or because the query modifies data.
To retrieve an estimated execution plan in SQL Server Management Studio (SSMS) there is a button in the menu bar immediately above the query window or Ctrl+L can be pressed.

Pressing that button should immediately cause a new tab to appear at the bottom on the screen. The new tab shows the execution plan.
To retrieve an actual execution plan there is a button three places to the right of the estimated plan button in the screenshot above. The keyboard shortcut for this is Ctrl+M. Unlike the estimated plan button/shortcut, enabling the actual execution plan does nothing except highlighting the button. After enabling the feature, the query must be executed to see the actual execution plan.
For this simple query the actual and estimated plans should be the same. The screenshot below shows the actual execution plan. A screenshot of the estimated plan would look the same except there would not be a Results tab since the query wasn’t executed.
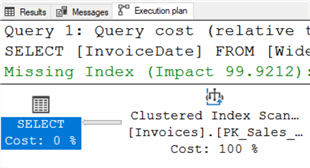
Execution plans are generally read from the bottom up and from right to left. The arrows in the plan will show how the data flowed. This plan tells us that the select statement got its data from a clustered index scan against the invoices table where the clustered index is called PK_Sales_invoices. Most of that index name appears on the plan before getting cut off. This is our first hint that an index will help as scans are generally slower than seeks and can often be improved by adding indexes.
Determining what the index should look like is even easier. Whenever a query is executed, SQL Server looks for an ideal index to make the query run quickly. When it doesn’t find one, it moves on to the next best way to solve the problem and makes note of what the ideal index would have been. The green text (Missing Index) in the plan from the screenshot above is the result of that process. SQL Server further estimates that if that ideal index had existed the query would have executed using 99.9212% (Impact 99.9212) less resources than what it ended up doing, the clustered index scan.
Right clicking anywhere in the execution plan will bring up a context menu. In that menu will be an option for “Missing Index Details…”. Choosing that option will open a new query window with a CREATE INDEX statement commented out. That index is the ideal index that SQL Server had hoped would exist when it was first asked to look at the query.

The code…
/*
Missing Index Details from MSSQLTips.sql - (local).master
The Query Processor estimates that implementing the following index could improve the query cost by 99.9212%.
*/
/*
USE [WideWorldImporters]
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Sales].[Invoices] ([InvoiceDate])
GO
*/
It is important to avoid the temptation to simply highlight and run the CREATE INDEX statement. Doing so will create an index with the literal name <Name of Missing Index, sysname,>. There are probably millions of indexes with that name worldwide for this very reason!

After choosing a more appropriate name (better than the one used for this demo), create the index and rerun the query. The execution plan should look much different now.
CREATE NONCLUSTERED INDEX MAKE_ME_FASTER ON [Sales].[Invoices] ([InvoiceDate])
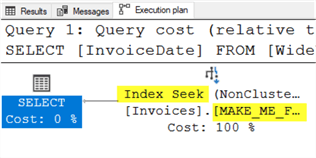
The first thing to notice is that the green text informing the user of the missing index is gone. Next, notice that what had been a Clustered Index Scan is now an Index Seek operation which should be much faster. Finally, the object that was used to perform the select operation is, indeed, the new index that was created.
There might be multiple pieces of advice
This was a very simple example. Most queries combine several tables and involve multiple indexes. That super-useful green text will only show the first of what could be many missing indexes for an individual query. One way to deal with this is to create the missing index and run the query again. If the green line of text remains, it is likely requesting another index. This process can be repeated as long as necessary.
Consider this query.
SELECT AP.EmailAddress, SI.InvoiceDate
FROM [Sales].[Invoices] SI
INNER JOIN [Application].[People] AP ON SI.LastEditedBy = AP.PersonID
WHERE AP.EmailAddress = 'alicaf@wideworldimporters.com';
Requesting an execution plan suggests a single missing index on the Sales.Invoices table yet there are 2 scans that might benefit from a new index.

Creating that index and rerunning the query brings about another missing index, this time on Application.People. Creating that index and running the query a third time shows a query plan that references both the first new index and the second new index. Using IO statistics determined that the number of logical reads for the query dropped from over 6500 to under 10!

Sometimes it gives bad advice
While missing index scripting is a tremendously powerful feature for performance tuning T-SQL code, it isn’t a panacea.
It will not suggest a better index if a “pretty good” index is found.
It will not suggest adding a single included column to an existing index to remove a key lookup.
It will suggest an index with far too many columns included. For instance, changing the very first query of this tip to select * rather than the single column changes the recommended index to the index below. Clearly this is not an index that should be created.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Sales].[Invoices] ([InvoiceDate])
INCLUDE ([InvoiceID],[CustomerID],[BillToCustomerID],[OrderID],[DeliveryMethodID],[ContactPersonID],[AccountsPersonID],[SalespersonPersonID],[PackedByPersonID],[CustomerPurchaseOrderNumber],[IsCreditNote],[CreditNoteReason],[Comments],[DeliveryInstructions],[InternalComments],[TotalDryItems],[TotalChillerItems],[DeliveryRun],[RunPosition],[ReturnedDeliveryData],[ConfirmedDeliveryTime],[ConfirmedReceivedBy],[LastEditedBy],[LastEditedWhen],[SalesPersonName],[ContactPersonName])
It might suggest an index that is pretty similar to an existing index. In such cases it may make more sense to modify an existing index rather than create a brand new one that is so similar.
The whole process is based on estimates. If the column statistics are bad or outdated then the query estimates might be invalid and lead to bad index recommendations.
Next Steps
- Check out this Performance Tuning Tutorial
- Check out this tutorial all about query execution plans
- Get more details on execution plans
- This tip talks about how to read graphical execution plans

Eric has been a SQL Server DBA and Architect in the legal, software, transportation, and insurance industries for over 10 years. Currently he is the Sr Data Architect for Squire Patton Boggs, a leading provider of legal services with 47 offices in 20 countries.
Eric is a 2018-2019 Idera Ace and has co-authored 2 Idera Whitepapers.
He has been a presenter at PASS Summit, IT/DevConnections, SQLSaturdays, the in.sight transportation conference, and the Ohio North SQL Server User’s Group.
- MSSQLTips Awards: Author of the Year Contender – 2021, 2022 | Trendsetter (25+ tips) – 2021


