By: Aaron Bertrand | Comments (9) | Related: 1 | 2 | 3 | 4 | > Temporal Tables
Problem
SQL Server 2016 introduced a new feature, Temporal Tables, which allow you to keep a historical record of all of the versions of each row in a table. As rows get introduced, changed, and deleted over time, you can always see what the table looked like during a certain time period or at a specific point in time.
You may have heard Temporal Tables referred to as system-versioned tables. What happens is that the historical versions of rows, according to the system time of their last modification, are stored in a separate table, while the current version resides in the original table.
For tables that don't change very often, this works fantastic - queries against the base table know, based on the filter criteria, whether to get the data from the base table or the history table. For tables with a high volume of insert/delete activity, however, or with rows that get updated frequently, the history table can quickly grow out of control. Imagine a table with 100 rows, and you update those 100 rows 100 times each - you now have 100 rows in the base table, and 9,900 rows in the history table (99 versions of each row).
While there are definitely going to be regulatory/auditing exceptions, in many cases, you won't want or need to keep every single version of every single row for all of time.
Solution
The MSDN article, Manage Retention of Historical Data in System-Versioned Temporal Tables, provides a few options:
- Stretch Database
- Table Partitioning (sliding window)
- Custom cleanup script
The way these solutions are explained, though, lead you to make a blanket choice about retaining historical data only based on a specific point in time (say, archive everything from before January 1, 2017) or fixed windows (once a month, switch out the oldest month). This may be perfectly adequate for your requirements, and that's okay.
When I considered these solutions, I immediately envisioned a scenario that they wouldn't cover: what if I want to keep only the last three versions of a row, regardless of when those modifications took place? Or all previous versions from the past two weeks or the current calendar year, plus one additional version before that? If I archive or delete based only on a point in time, then I might keep too many versions of some rows, and no historical versions of other rows. If I want to keep the three previous versions, I can't possibly enforce that based on a point in time.
Any criteria can be accomplished, of course, if we put a little more thought into the "custom cleanup script" solution. The procedure demonstrated in the documentation accepts a specific datetime value, and deletes all historical data before that point. I'd like to demonstrate how to accomplish a selective delete (or archiving into yet another historical location) using a different set of criteria.
First, we need a base table, and a few rows:
CREATE TABLE dbo.Employees
(
EmployeeID int PRIMARY KEY,
FirstName nvarchar(64),
LastName nvarchar(64),
Salary int,
ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo datetime2(7) GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
) WITH (SYSTEM_VERSIONING = OFF);
INSERT dbo.Employees(EmployeeID, FirstName, LastName, Salary)
VALUES (1, N'Bobby', N'Orr', 25000),
(2, N'Milt', N'Schmidt', 25000),
(3, N'Eddie', N'Shore', 25000);
Now, even though SYSTEM_VERSIONING is OFF, the ValidFrom and ValidTo values are populated with the time of the insert and the end of the day on 9999-12-31, respectively. If you update the data in this table right now, the ValidFrom value will update the current time, but no historical version of the row will be stored anywhere.
We can then create a history table. The columns and data types must match, but the history table can't have constraints. So we're going to create a clustered index on EmployeeID, ValidFrom, ValidTo:
CREATE TABLE dbo.Employees_History ( EmployeeID int NOT NULL, FirstName nvarchar(64), LastName nvarchar(64), Salary int, ValidFrom datetime2(7) NOT NULL, ValidTo datetime2(7) NOT NULL ); CREATE CLUSTERED INDEX EmployeeID_From_To ON dbo.Employees_History(EmployeeID, ValidFrom, ValidTo);
Next, we'll fictitiously populate it with some historical versions of these rows, just as if I had set this up a couple of years ago (this is *absolutely not* a demonstration of how Temporal Tables should work, nor a recommendation to ever do it this way; we're just trying to set up some dummy data):
-- a historical version representing when we updated salary: INSERT dbo.Employees_History ( EmployeeID, FirstName, LastName, Salary, ValidFrom, ValidTo ) SELECT EmployeeID, FirstName, LastName, 20000, DATEADD(YEAR, -1, ValidFrom), ValidFrom FROM dbo.Employees; INSERT dbo.Employees_History ( EmployeeID, FirstName, LastName, Salary, ValidFrom, ValidTo ) -- then another salary update from a year before: SELECT EmployeeID, FirstName, LastName, 15000, DATEADD(YEAR, -1, ValidFrom), ValidFrom FROM dbo.Employees_History -- and a row that has been "deleted" from the primary table UNION ALL SELECT 4, N'Phil', N'Esposito', 24500, '20150101', '20161231'; -- then, finally, let's add a new row that doesn't exist in history: INSERT dbo.Employees(EmployeeID, FirstName, LastName, Salary) VALUES(5, N'Brad', N'Marchand', 22750);
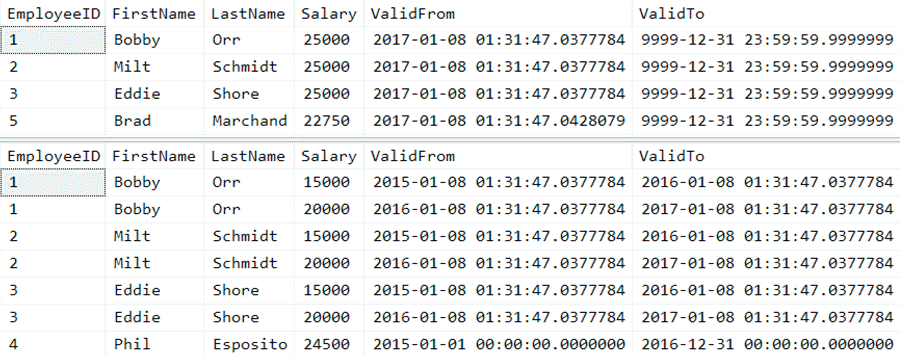
If we take a quick look, we have 4 rows in the base table, and 7 rows in history:
SELECT * FROM dbo.Employees; SELECT * FROM dbo.Employees_History;
Base table and history table rows (click to enlarge)
Now, we can turn system versioning for the table ON:
ALTER TABLE dbo.Employees SET (SYSTEM_VERSIONING = ON ( HISTORY_TABLE = dbo.Employees_History, DATA_CONSISTENCY_CHECK = ON ));
And just for kicks, let's update one row:
UPDATE dbo.Employees SET FirstName = N'Milton' WHERE EmployeeID = 2;
What this does, effectively, is moves the existing row from the base table to the history table, updates the ValidTo value to the current time, then creates a new row in the base table with the updated column and a new ValidFrom value. (That is what happens logically, but not necessarily what happens physically.) Now the two tables look like this - up top, I've highlighted the changed value in the base table, and below, the row that now appears in the history table (click to enlarge):
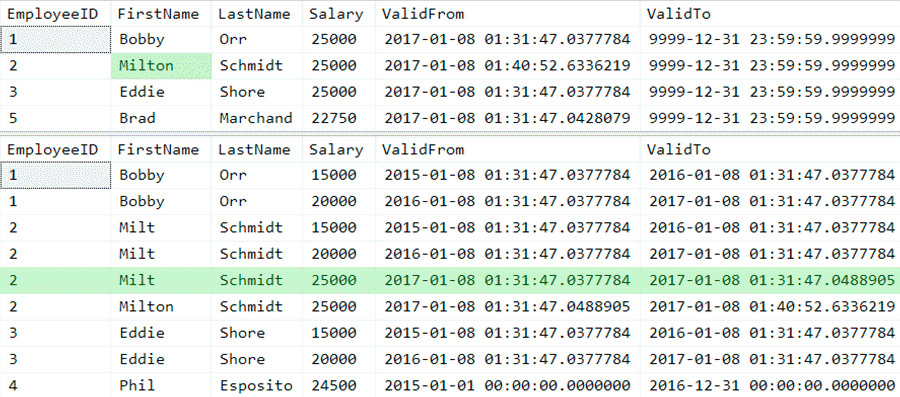
Highlighting changes after an update (click to enlarge)
This should demonstrate the purpose of this article: As you update more rows in the base table, the history table can very quickly ramp up and take over your disk, especially if the rows are a lot wider than this simple example.
Identifying Rows to Clean up
Depending on the rules you want to use to determine which history rows to keep or throw away, it should be easy in this case to visually identify those rows, and then build the proper query.
First, let's look at the total set of rows we have in our base table and the history table together:
SELECT *, src = 'Base table' FROM dbo.Employees UNION ALL SELECT *, 'History table' FROM dbo.Employees_History ORDER BY EmployeeID, ValidFrom;
That looks like this (click to enlarge):

Union of base table and history table data (click to enlarge)
Again, the rules you want to use to dictate which rows to keep and which rows to delete or archive will have bearing on this. There are a variety of things you may want to do, for example you may want to keep a certain number of history versions of a row regardless of time, or you may always want to keep only a certain window, or you may want to use some combination. You may even want to have different retention policies applied to different products, departments, teams, or whatever data you're storing.
Assuming we want to start simple and only keep the previous version of any given row (including the latest version for any key that only exists in the history table), we can first apply shading visually to the above image to highlight the history rows we're going to delete (click to enlarge):
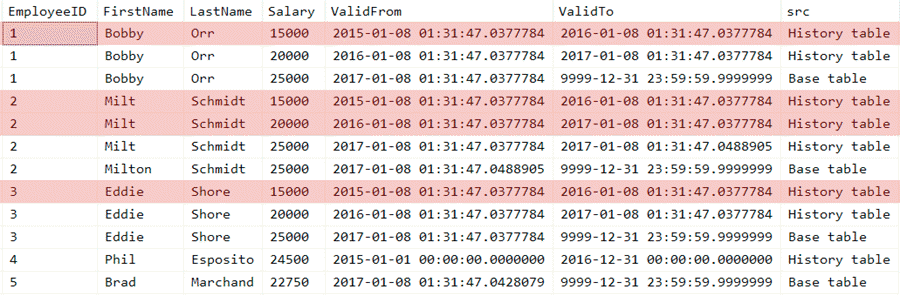
Highlighting history rows to delete (click to enlarge)
My suggestion would be to use a common table expression (CTE) to help identify those rows correctly, as you can then easily change the outer query from a SELECT to a DELETE. So we can start with this:
;WITH h AS
(
SELECT *, rn = ROW_NUMBER() OVER
(PARTITION BY EmployeeID ORDER BY ValidFrom DESC)
FROM dbo.Employees_History
)
SELECT * FROM h WHERE rn > 1
-- DELETE h WHERE rn > 1
;
And sure enough, here are the rows we've identified using the SELECT query (click to enlarge):

Proving we've identified the right rows (click to enlarge)
If we want something more flexible than just keeping the latest history row, like keeping *all* of history for the past month in addition to the latest versioned row before that, it just makes our query a little more complex. In this case it only changes the visual by a single row, marked here as "Now keep!" (click to enlarge):
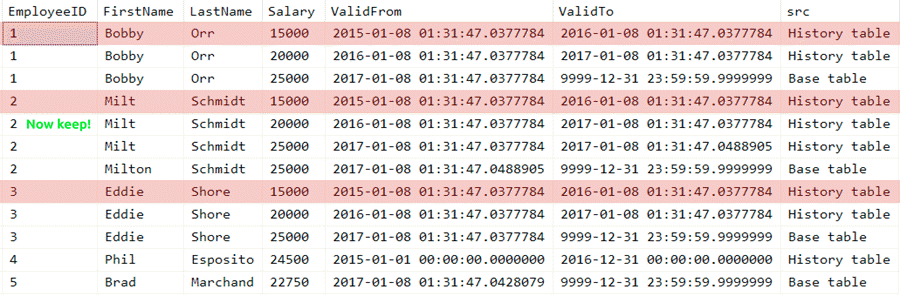
Highlighting rows to delete based on a different retention policy (click to enlarge)
And the code just uses an additional CTE to first eliminate all of the updates in the past month before determining which rows represent the most recent updates:
;WITH only_history_over_a_month_old AS
(
-- select only the rows more than a month old (maybe use SYSUTCDATETIME()):
SELECT * FROM dbo.Employees_History
WHERE ValidFrom < DATEADD(MONTH, -1, SYSDATETIME())
),
h AS
(
SELECT *, rn = ROW_NUMBER() OVER
(PARTITION BY EmployeeID ORDER BY ValidFrom DESC)
FROM only_history_over_a_month_old
)
SELECT * FROM h WHERE rn > 1
-- DELETE h WHERE rn > 1
;
Easier said than done?
The CTEs above use a SELECT as the final query, and have the DELETE commented out. However, you can't just swap the comments to perform the delete. The trick with actually deleting rows from the history table is that system versioning needs to be turned off (true for any DML you want to manually perform). If you try to delete from the table right now, you will get the following error:
Msg 13560, Level 16, State 1 Cannot delete rows from a temporal history table 'SampleDB.dbo.Employees_History'.
You will need to stop versioning the base table, either during a maintenance window, or by implementing the changes within a serializable transaction (or both, to be safe). In either case, you likely want to minimize the amount of time that the base table is not being versioned - by using a serializable transaction, it ensures that any potential writers will be blocked while the changes are taking place.
The sequence, at a high level, would look like this:
- Begin a serializable transaction
- Turn versioning off on the base table
- Purge or move the rows
- Turn versioning back on
- Commit the transaction
And the code would look like this, but keep in mind you'll have to execute each statement independently. If you run this all at once, the parser will complain that you're trying to update a history table you haven't yet disabled.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
ALTER TABLE dbo.Employees SET (SYSTEM_VERSIONING = OFF);
-- assuming the "delete all but the most recent history version" variation:
;WITH h AS
(
SELECT *, rn = ROW_NUMBER() OVER
(PARTITION BY EmployeeID ORDER BY ValidFrom DESC)
FROM dbo.Employees_History
)
DELETE h WHERE rn > 1;
SELECT @@ROWCOUNT; -- maybe only execute up to this point
-- if it doesn't look right, ROLLBACK!
ALTER TABLE dbo.Employees SET (SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.Employees_History,
DATA_CONSISTENCY_CHECK = ON
));
COMMIT TRANSACTION;
-- ROLLBACK TRANSACTION;
That CTE + DELETE in the middle would be the only part that needs to change, depending on the retention policy you want to enforce. I should add the disclaimer that you should check @@ROWCOUNT after the DELETE and make sure that not only the right number of rows, but also the right rows, have been deleted (I've left out error handling and detailed validation for brevity).
If you are deleting a large number of history rows, you will likely want to add some batching logic to this, rather than delete all the rows at once, in order to minimize the impact on the transaction log and, more importantly, blocking. (I describe a technique for this in Break large delete operations into chunks. However, since you're relying on CTEs here, you may need to dump those rows to a #temp table in order to process them x rows at a time, or use a cursor to cycle through a certain number of key values at a time. This is so that you don't inadvertently delete the "most recent" row for any key more than once.)
Another Space-Saving Idea
Since system versioning is all-or-nothing, and you don't necessarily need to maintain a historical record of every change to every column in a table, another thing you can consider doing is removing the data from columns that don't need to be audited. If you had an additional column that stored notes or other unstructured data for each employee, where only the current version really matters, you could use the same process as above to set that column to NULL in the history table.
Summary
Temporal tables provide a rich and powerful way to maintain historical versions of rows, with minimal effort. When history grows to the point that maintenance is required, there are many options for cleaning up, and you aren't restricted to naïve, hard-coded, time-based windows. I hope I have shown here how you can accomplish much more flexible retention policies, allowing you to keep exactly the history you want.
Next Steps
- See these tips and other resources:
- Tip #3680 : Introduction to SQL Server 2016 Temporal Tables
- Temporal Tables (MSDN)
- Tip #3682 : SQL Server 2016 T-SQL Syntax to Query Temporal Tables
- All SQL Server 2016 Tips
- Manage Retention of Historical Data in System-Versioned Temporal Tables (MSDN)
- Temporal Table Considerations and Limitations (MSDN)






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips

