Problem
In my previous tip, SQL Server 2017 Graph Database, we have seen the introduction of the Graph Database feature along with some of the details of Node and Edge tables. In this tip we will see how to extract and query the information from SQL Server 2017 Graphs as well as demonstrate how these queries are different from the relational database queries.
Solution
A graph in SQL Server 2017 is a collection of node and edge tables. A node represents an entity. For example, a person or an organization. An edge represents a relationship between the two nodes it connects. Node or Edge tables can be created under any schema in the database, but they all belong to one logical graph.
Note: Please review the SQL Server 2017 Graph Database tip to understand the example shown below.
CQL Example
Cypher is a declarative graph query language that allows for expressive and efficient querying and updating of a property graph. Cypher is a relatively simple, but still very powerful language. Very complicated database queries can easily be expressed through Cypher. Cypher is Neo4j’s open graph query language and in SQL Server 2017, CQL is used for the Graph Database queries.
Below is the representation in cypher language.

CQL queries starts with the MATCH clause that identifies what data needs to be matched with. The MATCH extension for the T-SQL language is a built-in improvement that allows support of the pattern matching and traversal through the graph within SQL Server.
The format of the first release of the MATCH extension is following:
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
A general structure will be similar to this:
MATCH (node:Label) RETURN node.property
MATCH (node1:Label1)-->(node2:Label2)
WHERE node1.propertyA = {value}
RETURN node2.propertyA, node2.propertyB
Examples of Graph Database Queries
Below is the example that we are going to explore in this demo.
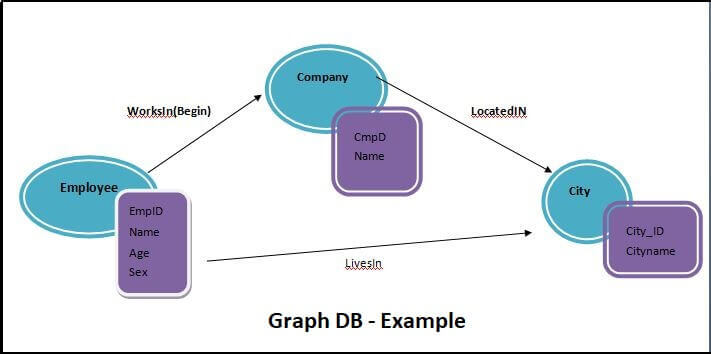
In this example we have following Nodes and Edges:
- Nodes: Employee, Company, City
- Edges: WorksIn(Begin), LocatedIn, LivesIn
SQL Server Relational Database Example
First, we will see how the relational database query’s work. To see this, we will create 3 tables: Employee, WorksIn and Company then see how to retrieve the results.
Create Database Test
Go
USE [Test]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Employee](
[Empid] [int] NOT NULL,
[name] [nvarchar](75) NULL,
[sex] [nvarchar](6) NULL,
PRIMARY KEY CLUSTERED
(
[Empid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[WorksIn](
[EmpID] [int] NULL,
[Cmp_ID] [int] NULL,
[Since] [int] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Company](
[cmp_ID] [int] NULL,
[cmpName] [varchar](100) NULL
) ON [PRIMARY]
GO
Now insert some data into the tables:
INSERT INTO Employee VALUES (1,'Henry Forlonge','Male');
INSERT INTO Employee VALUES (2,'Lily Code','Female');
INSERT INTO Employee VALUES (3,'Taj Shand','Male');
INSERT INTO Employee VALUES (4,'Archer Lamble','Male');
INSERT INTO Employee VALUES (5,'Piper Koch','Female');
INSERT INTO Employee VALUES (6,'Katie Darwin','Female');
INSERT INTO Company VALUES (1,'A Datum')
INSERT INTO Company VALUES (2,'Contoso, Ltd')
INSERT INTO Company VALUES (3,'Fabrikam Land')
INSERT INTO Company VALUES (4,'Nod Publishers')
INSERT INTO WorksIn VALUES(1,1,2015)
INSERT INTO WorksIn VALUES(2,2,2014)
INSERT INTO WorksIn VALUES(3,3,2016)
INSERT INTO WorksIn VALUES(4,3,2016)
INSERT INTO WorksIn VALUES(5,3,2014)
INSERT INTO WorksIn VALUES(6,4,2014)

SQL Server 2017 Graph Database Example
In order to retrieve results such as the list of employees who works in particular company, we might need three index lookups corresponding to the foreign keys. As the complexity increases, we might need more work to be done to retrieve the results.
Note the syntax used here for the below query, it is the old style join syntax. It means that in order to take advantage of this extension, we will need to write the list of the tables that are joined, separated by a comma (,) – instead of using the current join syntax, where we would include the name of the table with the join condition (i.e. INNER or OUTER) for each of the tables separately.
select employee.Name
from Employee ,company,WorksIn
where company.cmpName='Contoso, Ltd'
and WorksIN.Cmp_ID =company.Cmp_id
and WorksIn.EmpID =Employee.Empid
Now we will create the Nodes and Edges table based on the example shown above.
CREATE TABLE [dbo].[Company](
[ID] [int] NOT NULL,
[name] [varchar](100) NULL,
[sector] [varchar](100) NULL,
[city] [varchar](100) NULL
)
AS NODE;
CREATE TABLE [dbo].[Employee](
[ID] [int] NOT NULL,
[name] [varchar](100) NULL,
[sex] [char](10) NULL
) As Node;
CREATE TABLE [dbo].[City](
[ID] [int] NOT NULL,
[name] [varchar](100) NULL,
[stateName] [varchar](100) NULL
) As Node;
CREATE TABLE [WorksIn] ([year] [int] )AS EDGE
CREATE TABLE LocatedIn as edge;
CREATE TABLE LivesIn as edge;
Now let’s insert data into the Node table, notice that inserting data in Node table is same as the relational database statement.
-- Insert data into node tables. Inserting into a node table is same as inserting into a regular table
INSERT INTO Employee VALUES (1,'Henry Forlonge','Male');
INSERT INTO Employee VALUES (2,'Lily Code','FeMale');
INSERT INTO Employee VALUES (3,'Taj Shand','Male');
INSERT INTO Employee VALUES (4,'Archer Lamble','Male');
INSERT INTO Employee VALUES (5,'Piper Koch','FeMale');
INSERT INTO Employee VALUES (6,'Katie Darwin','FeMale');
INSERT INTO Company VALUES (1,'A Datum','Pharma','Bellevue');
INSERT INTO Company VALUES (2,'Contoso, Ltd','Manufacturing','Zionsville');
INSERT INTO Company VALUES (3,'Fabrikam Land','Pharma','Jonesbough');
INSERT INTO Company VALUES (4,'Nod Publishers', 'IT','Jonesbough');
INSERT INTO City VALUES (1,'Bellevue','Karlstad');
INSERT INTO City VALUES (2,'Zionsville','Karlstad');
INSERT INTO City VALUES (3,'Jonesbough','Lancing');
INSERT INTO City VALUES (4,'Abbeville','Lancing');
INSERT INTO City VALUES (5,'Zortman','Wyoming');
INSERT INTO City VALUES (6,'Zortman','Wyoming');
To insert data into the Edge table we need to provide the reference for the $from_id and $to_id as a reference point to both the Nodes.
--Insert into edge table. While inserting into an edge table,
--you need to provide the $node_id from $from_id and $to_id columns.
INSERT INTO WorksIn VALUES ((SELECT $node_id FROM Employee WHERE id = 1),
(SELECT $node_id FROM Company WHERE id = 1),2015);
INSERT INTO WorksIn VALUES ((SELECT $node_id FROM Employee WHERE id = 2),
(SELECT $node_id FROM Company WHERE id = 2),2014);
INSERT INTO WorksIn VALUES ((SELECT $node_id FROM Employee WHERE id = 3),
(SELECT $node_id FROM Company WHERE id = 3),2015);
INSERT INTO WorksIn VALUES ((SELECT $node_id FROM Employee WHERE id = 4),
(SELECT $node_id FROM Company WHERE id = 3),2016);
INSERT INTO WorksIn VALUES ((SELECT $node_id FROM Employee WHERE id = 5),
(SELECT $node_id FROM Company WHERE id = 3),2014);
INSERT INTO WorksIn VALUES ((SELECT $node_id FROM Employee WHERE id = 6),
(SELECT $node_id FROM Company WHERE id = 4),2014);
Insert into LocatedIN values ((select $node_id FROM Company WHERE id = 1),
(select $node_id FROM city where id=2))
Insert into LocatedIN values ((select $node_id FROM Company WHERE id = 2),
(select $node_id FROM city where id=1))
Insert into LocatedIN values ((select $node_id FROM Company WHERE id = 3),
(select $node_id FROM city where id=3))
Insert into LocatedIN values ((select $node_id FROM Company WHERE id = 4),
(select $node_id FROM city where id=2))
Insert into LivesIN values ((select $node_id FROM employee WHERE id = 1),
(select $node_id FROM city where id=6))
Insert into LivesIN values ((select $node_id FROM employee WHERE id = 2),
(select $node_id FROM city where id=5))
Insert into LivesIN values ((select $node_id FROM employee WHERE id = 3),
(select $node_id FROM city where id=4))
Insert into LivesIN values ((select $node_id FROM employee WHERE id = 4),
(select $node_id FROM city where id=2))
Insert into LivesIN values ((select $node_id FROM employee WHERE id = 5),
(select $node_id FROM city where id=3))
Insert into LivesIN values ((select $node_id FROM employee WHERE id = 6),
(select $node_id FROM city where id=1))
Below are examples of the data from the Node and Edge tables:
Node Tables

Edge Tables

Now to retrieve the results from a Graph, we need to run the queries in CQL. For example, to get the employee name who works in a particular company, the Graph Database query will be the following:
SELECT Emp.name FROM Employee Emp, WorksIN, Company Cmp
WHERE MATCH(Emp-(WorksIN)->Cmp)
AND Cmp.name='Contoso, Ltd';

In the image above we can see the query will need 1 index lookup, then it will traverse the relationships by referencing the physical pointers directly.
Sample SQL Server 2017 Graph Database Queries
Below are examples of different result sets retrieved from the Graph Database.
--To Get the Name of the Company where Employee Hentry Forlonge Works SELECT Cmp.Name
FROM Employee Emp, WorksIN, Company Cmp
WHERE MATCH(Emp-(WorksIN)->Cmp)
AND Emp.name='Henry Forlonge';

--To get list of Employee who live in city Zortman
SELECT Emp.name
FROM Employee Emp, LivesIN, City
WHERE MATCH(Emp-(LivesIN)->City)
AND city.name='Zortman';

--To get Employee and Company Name where employee works in company Fabrikam Land and working since 2014
select Employee.name ,company.name
From Employee ,Worksin, company ,LocatedIN,City
where MATCH(Employee-(WorksIN)->company and company-(LocatedIN)->City )
and WorksIN.year='2014' and Company.name='Fabrikam Land'

Next Steps
- Graph databases are a very useful feature added in SQL Server 2017 to represent and retrieve many to many relationships for data. Explore this in your environment and get familiar with this new technology.
- We will explore more about SQL Server 2017 in future tips.
- Explore the SQL Server 2017 preview.
- Read more about SQL Server vNext Linux Tips.

Hi! I am Rajendra Gupta, Database Specialist and Architect, helping organizations implement Microsoft SQL Server, Azure, Couchbase, AWS solutions fast and efficiently, fix related issues, and Performance Tuning with over 14 years of experience.
I am the author of the book “DP-300 Administering Relational Database on Microsoft Azure.” I can be reached at: Rajendra.gupta16@gmail.com for any consulting help.
- MSSQLTips Awards:
- Author of the Year – 2022 | Author Contender – 2021/2023/2024 | Champion Award (100+ tips) – 2020