Problem
Some technical problems do not lend themselves to storing and retrieving data from a predefined table. The popularity of NoSQL databases started with companies such as Facebook, Google and Amazon when working with big data problems and/or real time web applications. This set of technology is coined “Not Only SQL” since they might support a SQL syntax for retrieving data.
While there are many NoSQL database systems, most systems can be placed into one of four widely implemented data stores.
A key value store uses the concept of an associative array to save and retrieve data. The Webster dictionary is the physical implementation of this concept.
A document store encapsulates all the data for an entity (document) using a popular encoding format such as XML or JSON. This technology is popular with applications that have a variety documents with different attributes.
A graph store contains a bunch of elements with a finite number of connections between them. Data such as social relationships, road maps and/or network topologies can be easily represented with this technology.
A column store saves the data using columns instead of rows. This means that columns with discrete values can be highly compressed.
How can we use a document store technology in Azure to save and retrieve data?
Solution
Azure Cosmos database is Microsoft’s new globally distributed, multi-model database service. Right now, there is support for five different application programming interfaces: key value store (table), graph store (gremlin), document store (SQL), Mongo database (documents) and Casandra database (wide column). The highlighted words represent the API option to choose when creating the database account. Please see books on line for details. It is interesting to note that many changes happened to Cosmos database last year.
While there is support for four different application programming interfaces, today we are going to use the SQL API to manage JSON documents.
Business Problem
There are many financial companies that invest in the stock market via mutual funds. Our fictitious company named Big Jon Investments is such a company. They currently invest in the S&P 500 mutual fund but are thinking of investing in individual funds starting in 2018.
The investments department will need historical data to make informed choices when picking stocks. Our boss has asked us to load summarized daily trading data for the 505 stocks that make up the list into a key value store. We have five years’ worth of data stored in comma separated files. Each file has the stock symbol and year as part of the name.
How can we insert, update, delete and select records from Azure Cosmos DB using the SQL API?
Saving Stock Data in JSON format
In a previous article, I talked about the how to use Power Shell to load Azure Table Storage with stock data. There was 2,525 comma separated value (CSV) files that represented five years’ worth of S&P 500 stock data.
Almost all of the services published in Azure use the REST API. Roy Fielding proposed Representational State Transfer (REST) as an architectural approach to designing web services in the year 2000.
With these facts, we want to transform each of the records stored in the CSV file into a document using the JSON format. I am enclosing the PowerShell program that I used to make this conversion happen.
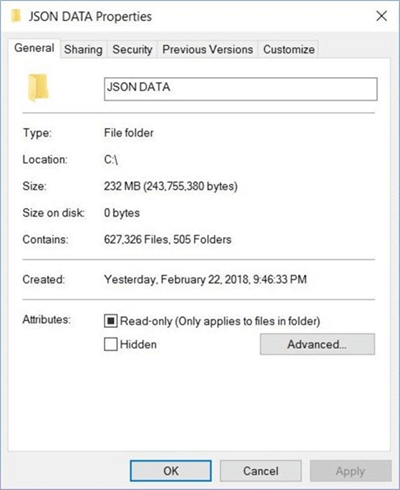
The image shown above is taken from Windows Explorer. It shows that 505 folders were created, one for each S&P 500 stock symbol. There are 627,326 JSON files or 232 MB of data to load into Azure Cosmos DB.
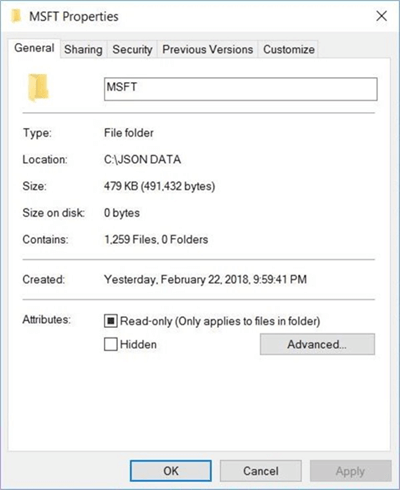
The above image shows the JSON files stored in the MSFT directory. This is the stock symbol for the company named Microsoft Inc.
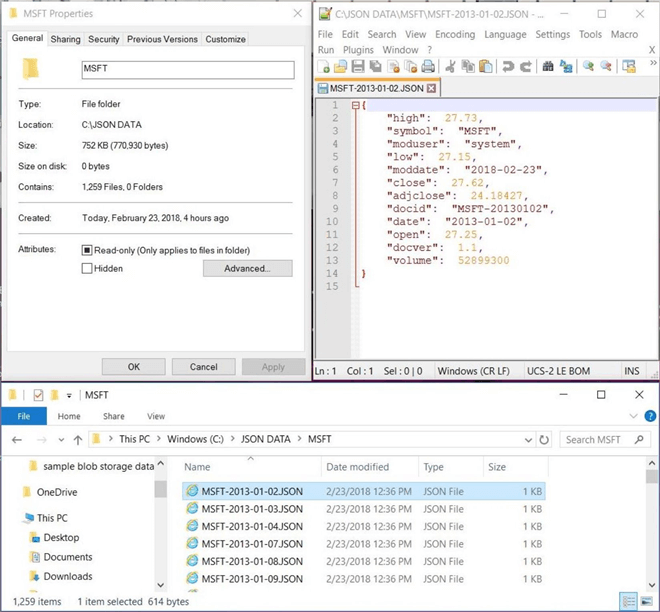
The above collage shows the MSFT directory, the size of one JSON data file, and the contents of one JSON data file.
There are four additional fields that have been added to the document for lineage. First, each document has to have a unique key. The document identifier (docid) is comprised of the stock symbol and the trading date. Second, each document should have a version number (docver). Since the schema is fluid in a NoSQL data store, we need to have governance that keeps track of the differences between version 1.1 and version 1.2. Last, it might be of interest to record who modified the record (moduser) and when was the record modified (moddate).
One decision that you need to make is how to deal with dates? They can be stored as a date string or as Unix epoch values. Read this article by John Macintyre, a partner manager at Microsoft, on this subject. I chose to store dates as searchable strings.
In a nutshell, you might want to add additional fields to the JSON document to satisfy your business requirements.
Azure Cosmos DB Overview
Before we create our first Azure Cosmos database, it is warranted to have an architectural overview of the document store technology. I am going to state the English old idiom. A picture is worth a thousand words.
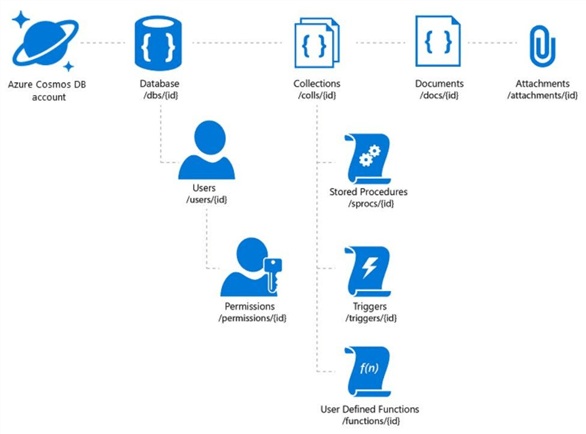
The above diagram taken from MSDN shows each of the components that maybe be used when designing your document store. I am going to call out the objects we need to define before we can load our stock data into the document store.
The database account is where you choose the API that you want to work with. In our case, we want to use the SQL API. Each account can have one or more logical databases. This is where users and permissions are defined. Each database can have one or more logical collections. This is where documents are group together. Resources units (RU) are defined at this level. Last but not least, collections can contain zero or more documents. The documents can be either homogenous or heterogeneous in nature.
Now that we have a high-level understanding of the database system, let us design our first document store using Azure Cosmos DB.
Creating Azure Objects in Azure Cosmos DB
This article assumes that you have an existing Azure subscription. If you do not, Microsoft offers new customers a 30-day trial subscription with a $200-dollar spending limit. Use this link to sign up now.
Once you logged into the Azure Portal, choose create a resource, databases, and Azure Cosmos DB. The following screen shot shows the dialog box to create a new database account.
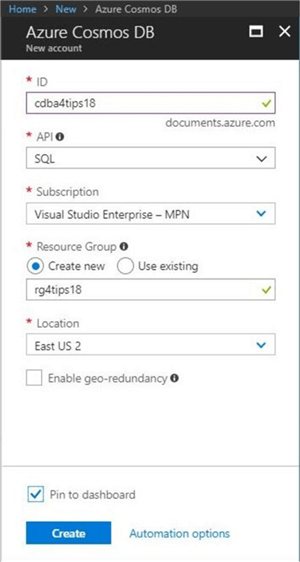
I am using a naming convention for the objects that I define in the Azure Portal. The database account named cdba4tips18 will be deployed in the east us 2 region within the rg4tips18 resource group. Of course, we want to use the SQL API to manage our data. Please note that I choose to pin this object to the dashboard as a short cut.
The image below shows the deployment of the Azure Cosmos DB database. Because this service is globally distributed, an image of the world is shown with all the regions shown as hexagons. Our primary service or database is located in the us east 2 region. Last but not least, the URL for our service is displayed in the top right corner. We will talk about replicating data in a future article.
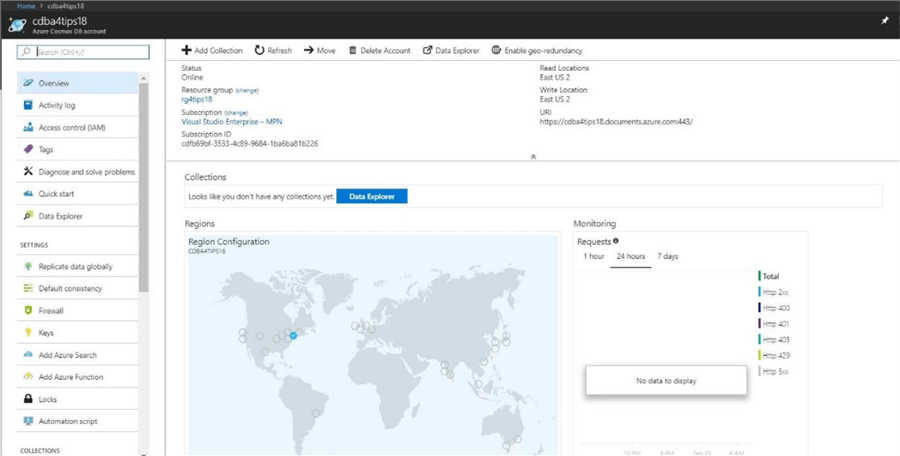
Before we can add JSON documents to the service, we need to define a database and collection. Click the data explore button highlighted in blue to defined these objects now.
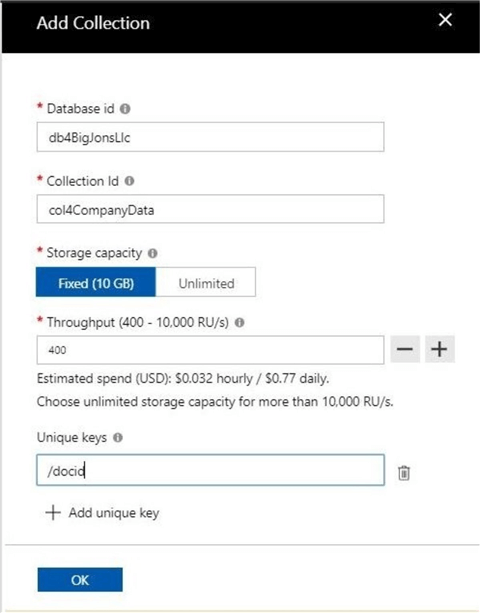
I am choosing to name the database db4BigJonsLlc and the name the collection col4CompanyData. There are two schools of thought when naming objects. The client, project and environment can be the prefix of the name so that all related objects are shown together in the portal. On the other hand, the type of object can be used as the prefix so that all similar objects are grouped together. As long as your company has a naming convention and the developers stick to the rules, your Azure objects should be grouped accordingly.
By default, a collection without a partition key is limited to 10 GB of data. Since partitions and replication are out of scope for this introductory article, we will talk about them in the future. I am choosing to dial down the resource units for the collection to the minimum. That means, a 10 GB collection will cost less than $25 dollars per month. Defining a unique key for the document is a requirement. We will select the document identifier (docid) field we added to the stock data.
Click the okay button to deploy the database and collection.
Three Explorers
The Azure portal has three explorers that can be used to manipulate our newly created collection. The document explorer allows you to add, update and delete documents from a collection. The query explorer allows you to select document data from the collection using a SQL like syntax. To round out our tools, the script explorer allows you to define JavaScript objects to support advanced functionality.
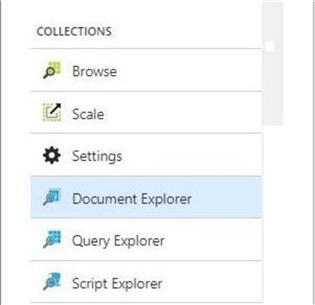
We will explorer each of these tools in the upcoming sections.
Manually Adding Data
The JSON document store would be of no use to our users if there is no data. Click the document explore and the upload button. Select the first seven documents related to stock symbol A or Agilent Technologies, Inc. Click the upload button to complete the action.
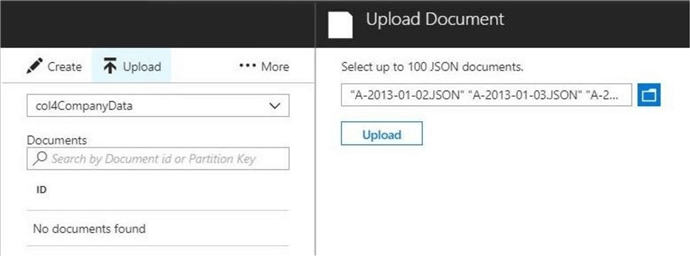
You should now see seven globally unique identifiers (GUIDS) related to the documents you just uploaded. Double click the first document to open it in a web editor.
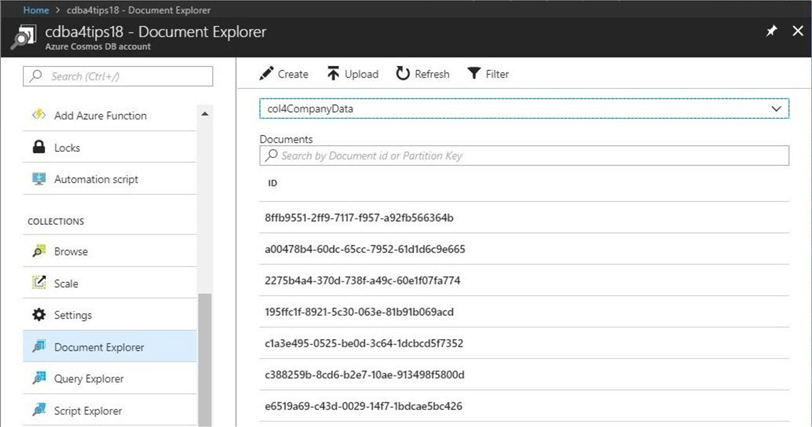
The image below shows the JSON document related to the data for stock symbol A on January 10th, 2013. The Cosmos database system automatically adds the id to the document for internal use.
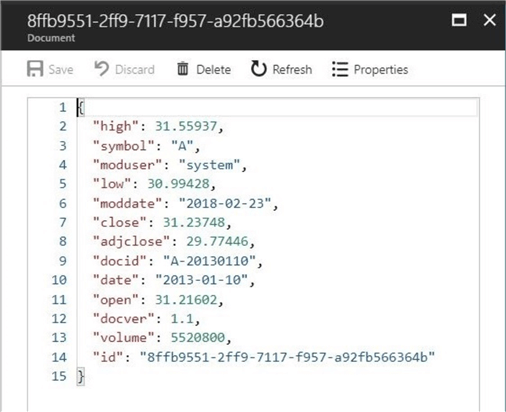
The data explorer can be used to load the collection with a limited number of documents. At most, you can load 100 files at a time. There must be a better way to load our half a million JSON documents to satisfy our business requirements?
Selecting Document Data
The query explorer is used to craft SQL statements to retrieve data from our JSON document store. For instance, a financial analyst at Big Jon’s Investments asked us to return an array of unique identifiers for 7 documents we recently loaded.
The Cosmos database supports a wide variety of SQL statements for the document store API. I will be talking about the various syntax you can used to retrieve data from this service in future articles. The statement below returns the docid attribute for the collection c which is defined as col4CompanyData.
SELECT c.docid FROM c
The image below shows the results of the SQL query.
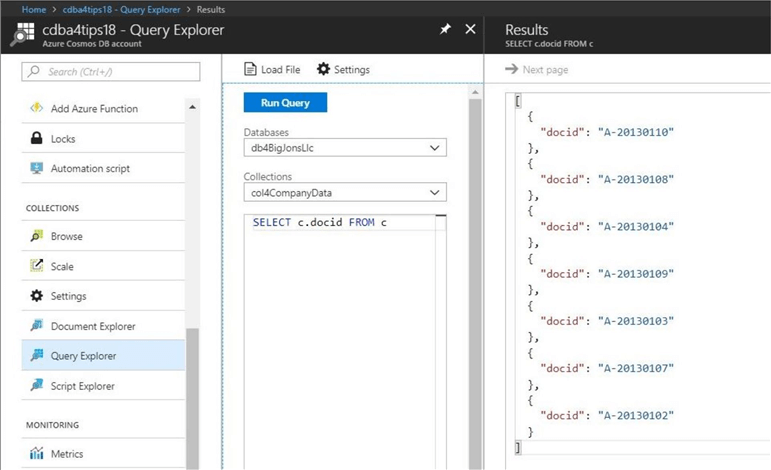
To recap, the document store in Azure Cosmos DB supports querying documents using a familiar SQL (Structured Query Language) like grammar over hierarchical JSON documents without requiring explicit schema or creation of secondary indexes.
Server-Side Programming
JavaScript is the chosen language to extended your design with Stored Procedures, pre and post document creation triggers and user defined functions. Again, these concepts are out of scope for an introductory article. However, I did want to mention that they do exist.
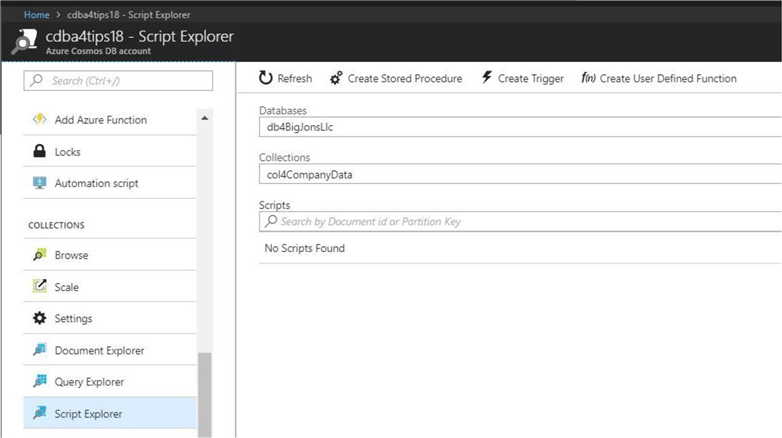
The above image shows the script explore in the Azure Portal. This is where you can deploy your user defined JavaScript code for stored procedures, triggers and functions.
Data Migration for Azure Cosmos DB
The current data explorer in the Azure portal only allows 100 documents to be uploaded per session. We would have to repeat this process more than 6,000 times to load the S&P 500 historical stock JSON documents. This is totally unfeasible. How can we load this data set as an easy and repeatable process?
Microsoft has supplied the administrator with a data migration tool for Azure Cosmos DB. The tool can be downloaded from this web page. This tool has not been updated in a while since it still references Document DB. On the other hand, the tool works just fine.
The first step is to download and unzip the files into a directory. Next, launch the dtui.exe program from Windows Explorer.
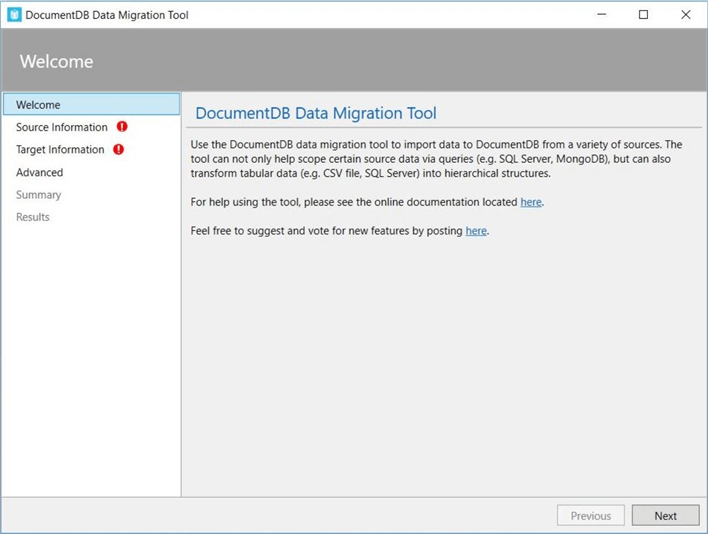
The second step is to define the source information. Choose add folder with the recursive sub-directory option. The image below shows the “C:\JSON DATA\” directory containing our source documents.
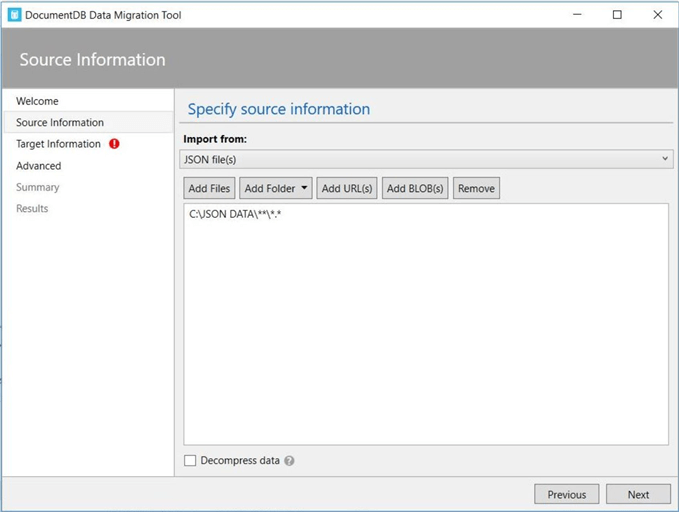
The third step is to define the target information. We need to retrieve this information from the Azure Portal. The image below shows the URL and PRIMARY KEY for our Cosmos Database account named cdba4tips18.
Capture and save this information for the target dialog box.
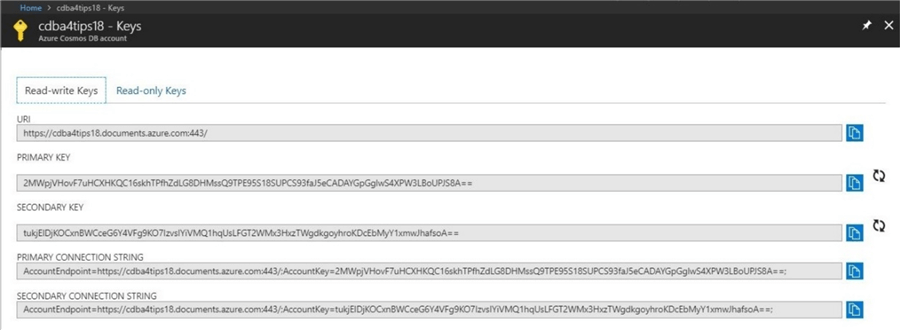
The image below shows the target dialog box. The connection string is comprised of the URL, the account key and the database name. We also need to supply the collection name, the id field and the collection throughput RU.
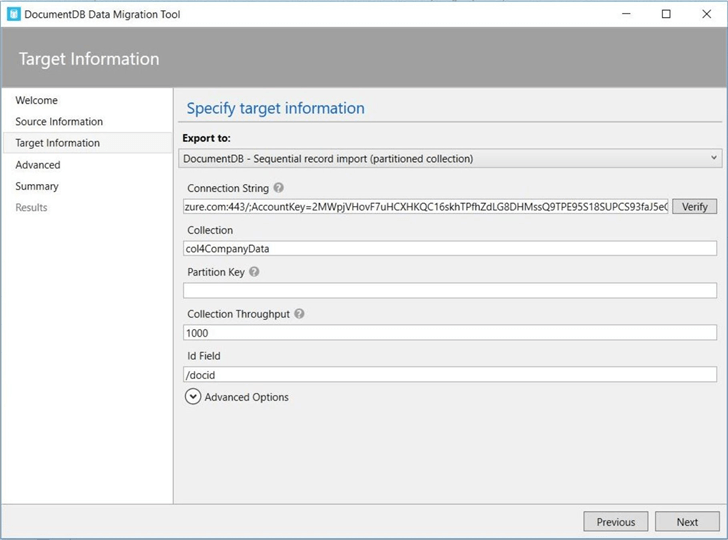
Click the advanced options to choose additional import settings. I have decided to connect using direct TCP, use 25 parallel requests for the import, update any existing documents and save dates as a string format. Last but not least, I will try the operation 30 times before marking it as a failure.
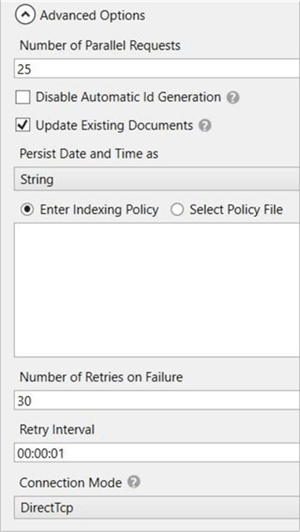
The fourth step is to define where to store error information, and how often do you get notified about the update process. Error logging is very important when determining the root cause of a failed insert.
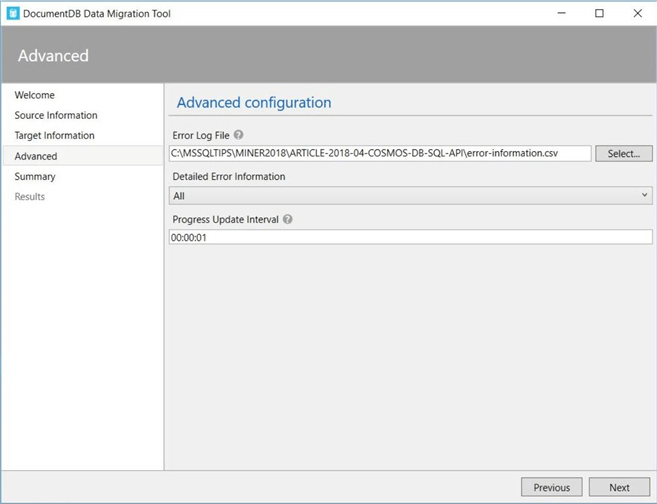
The fifth and last step is to confirm the import settings before execution. Since I am happy with my choices, I am going to click the import button.
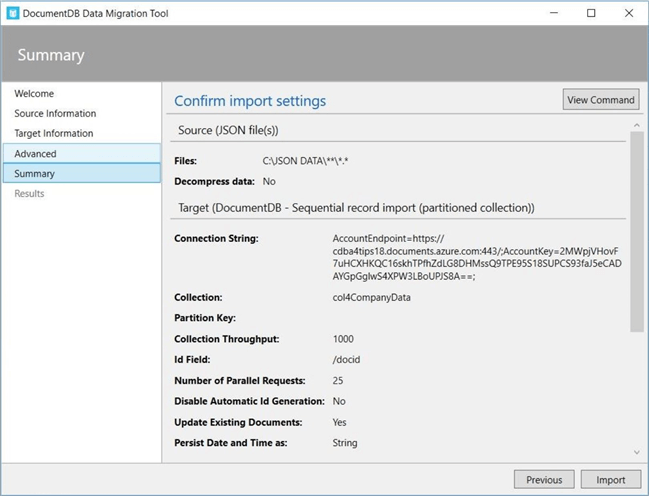
The image below shows the summary information at the end of execution. To display some error information, I did start and stop the process one time. This resulted in 839 records already being stored as documents. If we take a look at the error file, it states that there was a “unique index constraint violation”.
There was a total of 626,487 records imported in 18,110 seconds. That is roughly 34.59 records per second for a duration of 5 hours, 1 minute and 50 seconds.
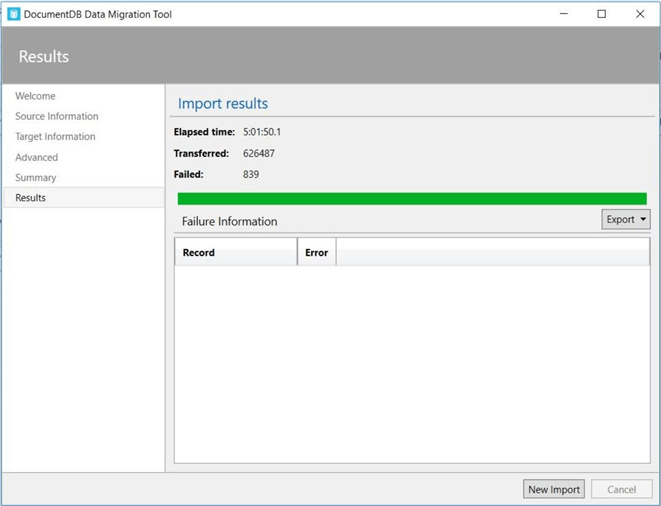
The Microsoft data migration tool is one easy way to load a bunch of documents into the document store.
Checking the Migration to Azure Cosmos DB
Today, we just inserted 627,326 documents into our collection named col4CompanyData which resides in our database named db4BigJonsLlc. Of course, both objects are associated with our database account named cdba4tips18.
Let us write a query to retrieve the number of trading days in which we have data for the stock symbol “MSFT”.
SELECT COUNT(c.docid) as total FROM c WHERE c.symbol = ‘MSFT’
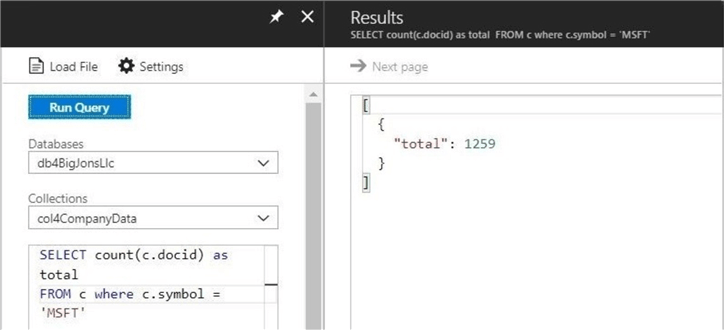
The above image returns a document count of 1,259 which is the correct answer.
Now, let us remove the WHERE clause to COUNT all the documents in the store. Okay, the number 29,535 is the wrong answer. What is going on here?
Unlike a relational database, the collection is throttled at the number of RUs we defined. For collections without a partition key, we can scale this number from 400 to 10,000. If we look at the details of the query execution, we can see that we used around 2314 RU’s and there is more data to be retrieved to arrive at the correct result.
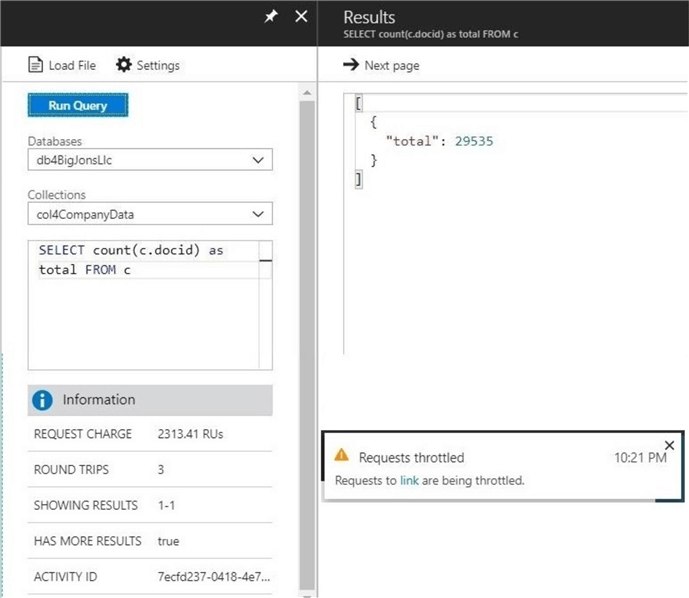
In conclusion, queries might complete with partial results. I leave it up to you to scale up the resource units (RU’s) for the collection and re-execute the query. Maybe it will finish with the correct result.
Azure Cosmos DB Summary
Today, we talked about how a NoSQL database can be categorized as either a key value store, a document store, a graph store or a column store.
Azure Cosmos database is Microsoft’s new globally distributed, multi-model database service. Right now, there is support for five different application programming interfaces: key value store (table), graph store (gremlin), document store (SQL), Mongo database (documents) and Casandra database (wide column).
The S&P 500 historical data set contains data on roughly 505 stocks over the past five years. A PowerShell program was designed to convert the 2,525 comma separated value (CSV) files into 627,326 JSON files or 232 MB of data.
The business problem we solved today was inserting and selecting data from the Azure Cosmos DB database using the Azure Portal. Unfortunately, the portal is not designed to import large amounts of data. Fortunately, Microsoft has supplied the administrator with a migration tool. This tool was used to load the data into Azure in about 5 hours.
Quality assurance is part of being an excellent administrator. A simple query to return the total number of trading days for the MSFT stock was designed and executed. The correct number of records was returned.
Next, the same query was modified to count the total number of records loaded into the database. Since this summary information is not part of the inverted columnar tree index, a full search was executed. A partial result was returned by the portal since the query was throttled by the resource unit governor.
In short, there is a lot more to learn about this NoSQL document store. I will be deep diving into some of the topics listed below in the future.
Next Steps
- Exploring the query syntax available with the SQL API
- Understanding partition and replication for distributed data
- Exploring the different consistency models in the SQL API
- Understanding server-side programming for the SQL API
- Understanding the data migration tools for Azure Cosmos database
- The different application SDK’s available with the SQL API
- Using table storage API with Azure Cosmos database
- Exploring graph storage API with Azure Cosmos database

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023
Superb – Smart !