Problem
If you polled any number of Microsoft SQL Server database professionals and asked the question, "Which is better when defining a primary key, having surrogate key or natural key column(s)?", I'd bet the answer would be very close to a 50/50 split. About the only definitive answer you will get on the subject is most people agree that when implementing a data warehouse, you have to use surrogate keys for your dimension and fact tables. This is because a source OLTP relational database can change at any time due to business requirements and your data warehouse should be able to handle these changes without needing any updates. This tip will go through some of the pros and cons of each type of primary key so that you can make a better decision when deciding which one to implement in your own environments.
Solution
Before we get into the pros and cons let's first make sure we understand the difference between a surrogate and natural key.
Surrogate Key Overview
A surrogate key is a system generated (could be GUID, sequence, unique identifier, etc.) value with no business meaning that is used to uniquely identify a record in a table. The key itself could be made up of one or multiple columns (i.e. Composite Key). The following diagram shows an example of a table with a surrogate key (AddressID column) along with some sample data. Notice the key itself has no business meaning, it's just a sequential integer serving as a unique key.
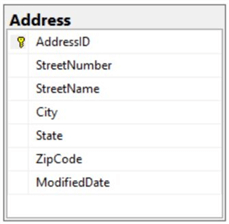

Natural Key Overview
A natural key is a column or set of columns that already exist in the table (e.g. they are attributes of the entity within the data model) and uniquely identify a record in the table. Since these columns are attributes of the entity they obviously have business meaning. The following is an example of a table with a natural key (SSN column) along with some sample data. Notice that the key for the data in this table has business meaning.
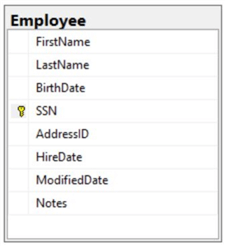

Natural Key vs. Surrogate Key for Database Design
Since this topic has been debated for years with no definitive answer as to which is better, I thought with this tutorial I would put together a list of all the pros and cons of each type of key. This list can then be used as a reference when deciding what type of key would be best suited for your own environment/application. After all, everyone's requirements are different. What works or performs well in one application might not work so well in another.
Natural Key Pros
- Key values have business meaning and can be used as a search key when querying the table
- Column(s) and primary key index already exist so no disk extra space is required for the extra column/index that would be used by a surrogate key column
- Fewer table joins since join columns have meaning. For example, this can reduce disk IO by not having to perform extra reads on a lookup table
Natural Key Cons
- May need to change/rework key if business requirements change. For example, if you used SSN for your employee as in the example above and your company expands outside of the United States not all employees would have a SSN so you would have to come up with a new key for your database tables.
- More difficult to maintain if key requires multiple columns. It's much easier from the application side dealing with a key column that is constructed with just a single column.
- Poorer performance since key value is usually larger and/or is made up of multiple columns. Larger keys will require more IO both when inserting/updating data as well as when you query.
- Can't enter record until key value is known. It's sometimes beneficial for an application to load a placeholder record in one table then load other tables and then come back and update the main table.
- Can sometimes be difficult to pick a good key. There might be multiple candidate keys each with their own trade-offs when it comes to design and/or performance.
Surrogate Key Pros
- No business logic in key so no changes based on business requirements. For example, if the Employee table above used a integer surrogate key you could simply add a separate column for SIN if you added an office in Canada (to be used in place of a Social Security Number)
- Less code if maintaining same key strategy across all entities. For example, application code can be reused when referencing primary keys if they are all implemented as a sequential integer.
- Better performance since key value is smaller. Less disk IO is required on when accessing single column indexes from an optimization perspective.
- Surrogate key is guaranteed to be unique. For example, when moving data between test systems you don't have to worry about duplicate keys since new key will be generated as data is inserted.
- If a sequence used then there is little index maintenance required since the value is ever increasing which leads to less index fragmentation.
Surrogate Key Cons
- Extra column(s)/index for surrogate key will require extra disk space
- Extra column(s)/index for surrogate key will require extra IO when insert/update data
- Requires more table joins to child tables since data has no meaning on its own.
- Can have duplicate values of natural key in table if there is no other unique constraint defined on the natural key
- Difficult to differentiate between test and production data. For example, since surrogate key values are just auto-generated values with no business meaning it's hard to tell if someone took production data and loaded it into a test environment.
- Key value has no relation to data so technically design breaks 3NF (i.e. normalization)
- The surrogate key value can't be used as a search key
- Different implementations are required based on database platform. For example, SQL Server identity columns are implemented a little bit different than they are in Postgres or DB2.
Summary
As mentioned above it's easy to see why this continues to be debated. Each type of key has a similar number of pros and cons. If you read through them though you can see how based your requirements some of the cons might not even apply in your environment. If that's the case then it makes it much easier to decide which type of key is the best fit for your application.
Next Steps
- Read more tips on SQL Server constraints
- Read other tips on data warehousing
- Read more information auto generated keys in SQL Server

Ben Snaidero has been a Database Administrator for just over 10 years. Starting out working mainly with Oracle he got into SQL Server in 2005 and has worked primarily with SQL Server for the last 3 years. His main focus with both Oracle and SQL Server is in the area of performance tuning.
- MSSQLTips Awards: Achiever (75+ tips) – 2018 | Author of the Year Contender – 2016-2017


