Problem
A SQL Server data warehouse generally receives data from multiple sources. For dimension tables, typically an additional surrogate key is included with the other attributes. This tip explains advantages and necessities of having surrogate keys in SQL Server dimension tables.
Solution
In a typical data warehouse design, a surrogate key is included in Dimensions tables. The following covers the reasons to have special surrogate keys in Dimension tables.
Protect the Data Warehouse from Unexpected Administrative Changes
If you are not using a special key as a primary key in a dimension, your only option is to include the current business key as a primary key of the dimension table. In the case of a data warehouse, we are dealing with millions of records which can span decades. In the case where we have included a natural business key as the primary key of the dimension table, the same key will be included in the fact table. Since data warehouses do not have control over the source systems, it is important to know that the business key can be changed over time due to administrative and operational needs. When this change occurs, the entire fact table needs to be updated. Mind you, we are taking about millions of records and updates to that many records will have other implications such as the table not being available until the update completes.
In the case where we include a surrogate key to the dimension table, it is only a matter of changing the dimension records which won’t be in the order of millions, as fact tables are linked with the surrogate key. Therefore, updating dimension records won’t have a major impact to the data warehouse system.
Let’s look at the below example which is taken from the AdventureWorksDW sample database. In this example, the CutomerKey is the surrogate key in the DimCustomer Table.
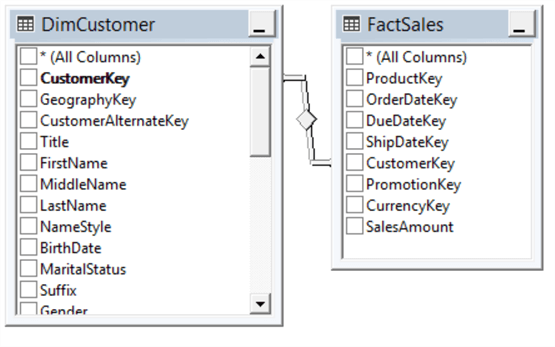
In case CustomerAlternateKey is modified, which is the business key of the Customer dimension, you only have to change the dimension table not the fact tables. Both data changes and data type changes can be handled with this method.
Integrate Same Data
As said previously, a data warehouse receives data from multiple sources. Sometimes, the same dimension will receive data from multiple sources. For example, for an organization who has employees at multiple sites, in the data warehouse you need to include all of them in one dimension for analysis purposes. In the case of OLTP, these data sets are maintained in isolation and they are unique in isolation. When these data are integrated into the data warehouse, there can be cases where the same primary key is used for multiple records in different locations. Since primary keys cannot be duplicated, loading data into the data warehouse will fail if you try to extract and load both records to the data warehouse.
Since we are including a surrogate key, duplicate issues will be fixed as the surrogate key is the primary key in the dimension table.
Add Rows to Dimensions that Do not Exist in the Source System
A dimension table can have records which are not in the source systems. When fact tables are updated, there can be multiple surrogate keys for one fact table.
Let’s look at the FactSales fact table.

In this fact table, for a given record, the ProductKey, OrderDateKey, DueDateKey, ShipDateKey, CustomerKey, PromotionKey and CurrencyKey are surrogate keys which should be updated. Since data is being received from multiple sources, there can be cases where one or two dimensions are not available. If these are not available, you have to ignore the entire record and foreign key violations will occur. To avoid this, there will be need to be manually entered records in the dimension. Typically, 0 or -1 will be used as a surrogate key which will be tagged in the fact table without violating foreign key constraints.
Provide the Means for Tracking Changes in Dimension Attributes Over Time
This is something where you can’t avoid surrogate keys in dimension tables. As we know, keeping historical data is essential in a data warehouse. Therefore, dimension changes need to be tracked in the data warehouse. To facilitate historical tracking in a dimension, type two slowly changing dimensions (SCD) are used. Details of this is item are discussed here.
In type 2 SCDs, a new row is added. If you don’t have the surrogate keys, there is difficulty of adopting the historical tracking in the data warehouse. With surrogate keys, a new record will have a different surrogate key to the previous records.
Maintaining Junk Dimensions
As we are aware, there are many statuses and flags in OLTP systems. Ideally, these need to be mapped to a dimension table in the data warehouse which will end up with a large number of dimension tables. However, to ease operations, multiple statuses are combined to one junk dimension table. Since this dimension table does not exist, you need to add a primary key which is a surrogate key.
Performance Compared to Larger Character or GUID Keys
As said multiple times in this article, large volumes of data are used in a data warehouse. Fact tables and dimension tables mainly join via surrogate keys. If those are integer columns, it will be better performing than using character columns.
Recommendations
Typically, an auto increment integer column is used as the surrogate key in a dimension table. Normally, surrogate keys do not have any meaning except for a surrogate key in the date dimension. In a date dimension, YYYYMMDD format is used mainly to enhance the data partitioning.
Next Steps
- Read how to implement surrogate keys in Slowly Changing Dimensions

Dinesh Asanka holds a Bachelor of Science in Electrical Engineering, an MBA in Information Technology, a Master of Science in Artificial Intelligence, and an MPhil in Data Warehousing from the University of Moratuwa. With more than 30 years of industry experience, he has successfully bridged the gap between theoretical knowledge and practical application in the fields of data management and analytics. Currently serving as a Senior Lecturer at the University of Kelaniya, he teaches subjects including Data Science, Big Data Analytics, and Database Administration. His research interests focus on Educational Analytics, Health Analytics, Data Science, and Artificial Intelligence-driven solutions for decision-making and learning enhancement. In addition to his academic and research contributions, Dinesh is also an active columnist and presenter who regularly contributes to professional forums, conferences, workshops, and public discussions related to technology, analytics, and digital transformation.
- MSSQLTips Awards: Rookie of the Year Contender – 2018


