Problem
With a Microsoft Visual Studio Database Project, we can use version control software to manage changes to databases and we may face these problems:
- The database project deployment failed, and the error message said “The schema update is terminating because data loss might occur”.
- A database object, for example a table, was removed in the project, but the object was still in the target database after a successful deployment.
Solution
When publishing a database project to the target database server using Microsoft Visual Studio, we can solve these problems through the “Advanced Publish Setting” window. When deploying the dacpac file by using command “SqlPackage.exe”, we can solve these two problems with adding specific parameters.
The solution was tested with Microsoft Visual Studio Community 2017 on Windows 10 Home 10.0 <X64>. The DBMS is Microsoft SQL Server 2017 Enterprise Evaluation Edition (64-bit). The sample data was retrieved from the AdventureWorks sample databases.
Add NOT NULL Columns to a Table
We have a staging table “[dbo].[Stage_Special_Offer]” in the database project “DWH_ETL_STORE”. The following screenshot presented the table structure. The table has some data.

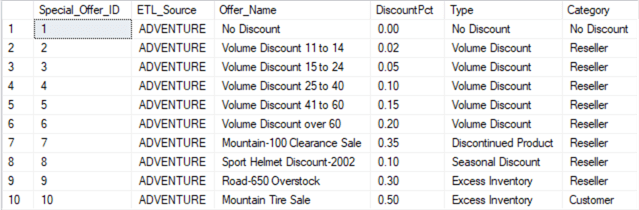
We added a new column “Offer_Description” with data type “NCARCHAR (50) NOT NULL”. Then we published the project by using the database project publishing wizard. We received this error message:
(48,1): SQL72014: .Net SqlClient Data Provider: Msg 50000, Level 16, State 127, Line 6 Rows were detected. The schema update is terminating because data loss might occur.
(43,0): SQL72045: Script execution error. The executed script:
IF EXISTS (SELECT TOP 1 1
FROM [dbo].[Stage_Special_Offer])
RAISERROR (N'Rows were detected. The schema update is terminating because data loss might occur.', 16, 127)
WITH NOWAIT;
An error occurred while the batch was being executed.
We found this comment in the “DWH_ETL_Store.publish.sql”:
must be added, but the column has no default value and does not allow NULL values.
If the table contains data, the ALTER script will not work. To avoid this issue,
you must either: add a default value to the column, mark it as allowing NULL
values, or enable the generation of smart-defaults as a deployment option. */
Some developers may add a default value to the column. I do not think this is a preferable solution for a table in a data warehouse. A not NULL column usually was needed on the basis of business requirements. Adding a default value seems to bypass the requirement unless a business requirement asks to do this. In addition, ETL developers could not find a data integrity error immediately if some bugs in the ETL process added a NULL value to the not NULL column.
Publish Table Changes by Enabling Smart Defaults with GUI
A preferable solution for a data warehouse table is to enable the generation of smart defaults as a deployment option, and then the ETL process ensures the data integrity and validation.
Here is the process to publish a database project with the generation of smart defaults as a deployment option enabled.
Step 1
Right click the project name in the “Solution Explorer” window and select “Publish” from the pop-up menu. Configure the “Target Database Settings” as follows, then click on the Advanced button.

Step 2
On the Advanced Publish Settings window, check the “Generate smart defaults, when applicable” checkbox. Then click the “OK” button. This gets us back to the above screen where we can use the Save Profile As if we want to save these settings for next time.

Step 3
Then click the “Publish” button.
The following screenshot shows the data in the table after the database project was published successfully. The new column “Offer_Description” was added with empty values.
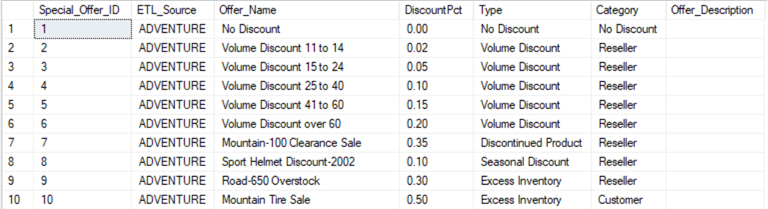
Publish Table Changes by Enabling Smart Defaults using Command Line
If we want to do this from the command line, we can use this command line syntax to deploy the project with the command “SqlPackage.exe”.
/Action:Publish /SourceFile:"DWH_ETL_STORE.dacpac" /TargetConnectionString:"Data
Source=IDEA-PC;Integrated Security=True;Initial Catalog=DWH_ETL_STORE;"
/p:GenerateSmartDefaults=True
This shows the project was deployed successfully with these confirmation messages.
C:\Users\z_000\Documents\MSSQLTips\DB_DEPLOYMENT\DWH_ETL_STORE>"C:\Program Files (x86)\Microsoft SQL Server\140\DAC\bin\SqlPackage.exe" /Action:Publish /SourceFile:"DWH_ETL_STORE.dacpac" /TargetConnectionString:"Data Source=IDEA-PC;Integrated Security=True;Initial Catalog=DWH_ETL_STORE;" /p:GenerateSmartDefaults=True Publishing to database 'DWH_ETL_STORE' on server 'IDEA-PC'. Initializing deployment (Start) Initializing deployment (Complete) Analyzing deployment plan (Start) Analyzing deployment plan (Complete) Updating database (Start) Altering [dbo].[Stage_Special_Offer]... Update complete. Updating database (Complete) Successfully published database.
Alter Not NULL Columns in a Table
Sometimes we might receive the same “data loss” error when we change a name of a not NULL column. This might not always happen, it depends on how we change the column name. If we change the name in the “T-SQL” panel, the error occurs.

To publish the project successfully, we need to change the not NULL column name in the “Design” panel. Note that other versions of Microsoft Visual Studio may provide a “Rename” menu item in the “Refactor” context menu.
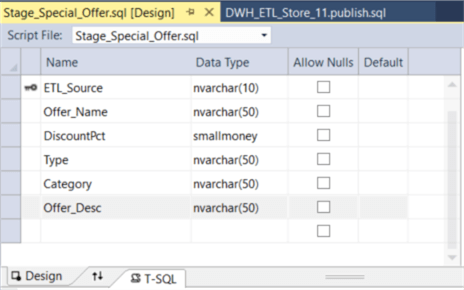
When we changed the column name in the “Design” panel, a “refactorlog” file “DWH_ETL_STORE.refactorlog”, was generated with these XML elements:
<?xml version="1.0" encoding="utf-8"?> <Operations Version="1.0" xmlns="http://schemas.microsoft.com/sqlserver/dac/Serialization/2012/02"> <Operation Name="Rename Refactor" Key="d83fba08-359c-4fd4-86ac-286ae63150cf" ChangeDateTime="04/07/2018 02:30:38"> <Property Name="ElementName" Value="[dbo].[Stage_Special_Offer].[Offer_Description]" /> <Property Name="ElementType" Value="SqlSimpleColumn" /> <Property Name="ParentElementName" Value="[dbo].[Stage_Special_Offer]" /> <Property Name="ParentElementType" Value="SqlTable" /> <Property Name="NewName" Value="Offer_Desc" /> </Operation> </Operations>
With this “DWH_ETL_STORE.refactorlog”, the publish scripts used “sp_rename” to rename the column, thus no data loss occurred.
GO EXECUTE sp_rename @objname = N'[dbo].[Stage_Special_Offer].[Offer_Description]', @newname = N'Offer_Desc', @objtype = N'COLUMN' GO
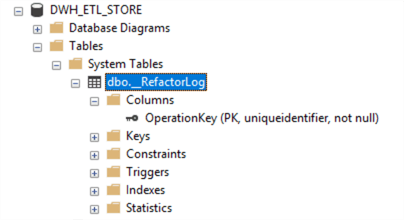
A system table “[dbo].[__RefactorLog]” was created in the target database to trace the database refactoring.
Drop Objects In Target But Not In Source
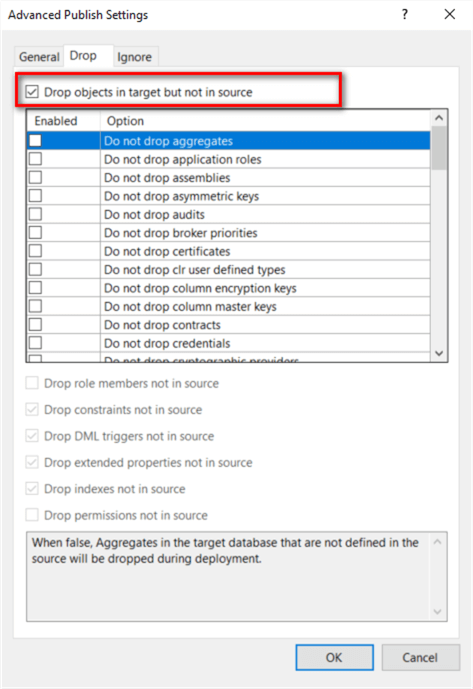
We might find tables deleted from the database project are still in the target database. The database deployment could add new tables, but the deployment did not remove unused tables. We can solve this through the “Advanced Publish Settings”.
Check the checkbox “Drop objects in target but not in source” in the “Advanced Publish Settings” window as shown in the screenshot. This will remove objects that were deleted from the database project.
Here is the command line syntax to deploy the project with the command “SqlPackage.exe”.
/Action:Publish /SourceFile:"DWH_ETL_STORE.dacpac" /TargetConnectionString:"Data
Source=IDEA-PC;Integrated Security=True;Initial Catalog=DWH_ETL_STORE;"
/p:GenerateSmartDefaults=True /p:DropObjectsNotInSource=True /p:UnmodifiableObjectWarnings=False
References
[1] AdventureWorks sample databases. Retrieved March 2, 2018 https://msdn.microsoft.com/en-us/library/ms124825(v=sql.100).aspx/.
[2] Walkthrough: Apply Database Refactoring Techniques. Retrieved April 7, 2018 https://msdn.microsoft.com/en-us/library/dd193272(v=vs.100).aspx/.
Next Steps
- In practice, we usually use scripts to deploy a database project to target servers automatically. This document about SqlPackage.exe is very helpful to construct the automation scripts. Microsoft Visual Studio also provides a function to compare the schema between the database project and the target database. We can use this function to ensure all of the not NULL column name changes were captured in the “refactorlog” file. This file should be stored under the version control system.
- Check out these related tips:

Nai Biao Zhou has twenty years of experience in software development, with strong analytical skills and a broad range of computer expertise.
He has fifteen years of experience in development and maintenance of database applications on SQL Server in OLTP/OLAP/BI environments.
He has a master’s degree in Control Engineering and is pursuing a Master of Science degree in Predictive Analytics.
Knowledge/Skills
Advanced computer programming skills and well versed with C/C#, Java, ASP.NET, JavaScript, and SQL.
In depth knowledge of Solution Architecture, and Software Development Life Cycle (SDLC).
Microsoft Certified Application Developer (MCAD) since 2004.
- MSSQLTips Awards: Author of the Year – 2021 | Rising Star (50+ tips) – 2024 | Author Contender – 2020, 2023



Thank You!! This worked for me!!!
Thank you, Badari! Very good point.
Go to Properties of that table where do not want modify anything, and select BuildAction to “NONE” option so this table will not be touched in deployment