Problem
In part 1 of this tip, we have set up a self-hosted IR environment in an Azure Data Factory (ADF) environment. We then added a node to this IR hosted on our local machine. Through this node, ADF will be able to connect to local resources, such as a local database instance of SQL Server. In this part, we’ll use this set up in a practical use case: we’re going to read data from the local server and push it to Azure Blob storage in an ADF pipeline.
Solution
If you haven’t already, please go through the tip Connect to On-premises Data in Azure Data Factory with the Self-hosted Integration Runtime – Part 1, since we’re going to build upon the setup configured in that tip. The current state is a self-hosted IR environment in ADF with one node hosted on a local server:

Through this IR, we created a connection to the AdventureWorks Data Warehouse on the default instance of SQL Server:

Copy Data from SQL Server
The first step is to create a dataset in ADF. In the Edit pane, click on the plus icon next to Factory Resources and choose Dataset:

There are many different types to choose from. You can quickly find SQL Server by typing “sql” into the search bar.

Choose the SQL Server dataset type and type in a name and description:

In the Connection tab, choose the linked service (which was created in part 1) and the table from which we want to read. In our example, we’re going to read from DimEmployee.

In the Schema tab, you can import the columns from the table. If you want, you can remove columns from the dataset.

The next step is to create a dataset on Azure Blob Storage. But first we need to create a linked service to Azure Blob Storage. In the Connections pane, go to Linked Services and click on New. Then choose the Azure Blob Storage data store.

In the configuration menu, you need to specify a name and an optional description. Since the storage account is in the same tenant in Azure, we can choose to connect through the AutoResolveIntegrationRuntime and use the current account key. If you have multiple subscriptions, choose the one you need from the dropdown and pick the storage account you want to use.
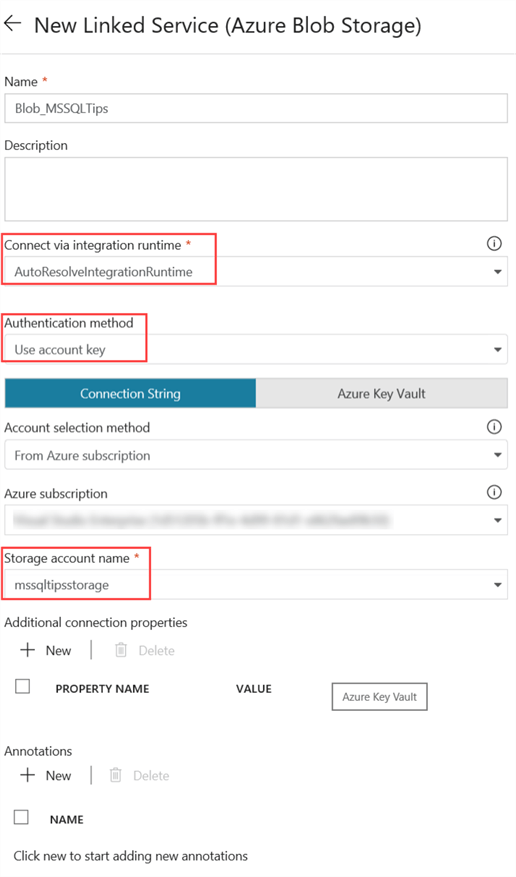
Optionally, you can test the connection:

Click Finish, then create a new dataset, choosing the blob data store:

In the connection tab, choose the linked service we just created. For the file path, you can use the browse button to find the correct blog container.

For this example, I created a blob container called employee. You can create this container either the Azure portal or through Azure Storage Explorer.

When browsing, you can choose the employee container from the listed containers.
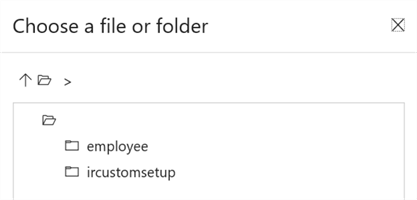
(If you’re wondering, the ircustomsetup folder is created in the tip Customized Setup for the Azure-SSIS Integration Runtime)
After choosing the blob container, you can choose the filename and the compression type.

Next the file format needs to be configured. We’re choosing a CSV type with a pipe as delimiter and a header as the first row.

Now we’re going to create a pipeline in ADF. Click on the plus icon again next to Factory Resources and choose Pipeline.

In the pipeline, add a Copy Data activity.

Give it a meaningful name:

Next, go to the Source configuration:

Here we choose the AW_Employees dataset we created earlier. Although we specified the schema in the dataset, you can still choose to specify a query or a stored procedure. Unfortunately, it’s currently not possible to do this directly in the dataset, which would be a more logical location to configure the data. In our example, we just need the entire table, so we’re going to leave the default. If you need more complex logic though, you can write any valid SQL statement or use a pre-defined stored procedure.
In the Sink (aka the destination) we choose the blob dataset:

There are different options for the copy behavior:

However, little documentation is available on what each option does exactly. In our example, we can leave the behavior to None (which is just a straight copy of the data source). You also have the option to specify the mapping in the next tab, but since our destination blob file doesn’t actually exist yet, this will result in an error. By leaving the mapping empty (and by specifying None as copy behavior), we’re dumping the result of the Source directly in the blob without any modifications.
In the Settings tab, you can further configure the behavior of the Copy Data Activity – such as error handling – but again, we’re leaving everything as-is.

The only thing left to do is running the pipeline. You can publish it and then trigger it to have it executed, but you can also debug the pipeline, which makes it run interactively (a bit like in an Integration Services control flow).

When looking at the blob container, we can see a file has indeed been added:

While inspecting the file, we can see the employee data from AdventureWorks has been added to the file in a .csv structure:

Now that the data is in blob storage (Azure Data Lake would also have been a good option), it can be used by other processes, such as advanced analytics, machine learning, APIs or other data pipelines.
Next Steps
- Try it out yourself! To follow along with this tip, you need a valid Azure subscription (free trials are available) and a local machine to host the node for the self-hosted IR.
- More tips about Azure Data Factory and the Azure-SSIS IR:
- Connect to On-premises Data in Azure Data Factory with the Self-hosted Integration Runtime – Part 1
- Executing Integration Services Packages in the Azure-SSIS Integration Runtime
- Parallel package execution in Azure-SSIS Runtime
- Configure an Azure SQL Server Integration Services Integration Runtime
- Customized Setup for the Azure-SSIS Integration Runtime

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025