Problem
In my previous article, Using Azure Data Lake Analytics and U-SQL Queries, I demonstrated how to write U-SQL in Azure Data Lake Analytics (ADLA). I now want to understand how I can create a database in Azure Data Lake and perform some similar routines as I would in a traditional SQL Server Database such as creating schemas, tables, views, table-valued functions and stored procedures.
Solution
While Azure Data Lake Analytics is designed for processing big data workstreams, Microsoft has neatly implemented some common features that we are familiar working with in the traditional SQL Server experiences. In this article, I will demonstrate and explain some of these features with specific examples on how to create schemas, tables, views, stored procedures and functions.
Creating an Azure Data Lake Analytics Account
To process data in Azure Data Lake Analytics, you’ll need an Azure Data Lake Analytics account and associate it with an Azure Data Lake store.
- In a web browser, navigate to http://portal.azure.com, and if prompted, sign in using the Microsoft account that is associated with your Azure subscription.
- In the Microsoft Azure portal, in the Hub Menu, click New. Then navigate to Data Lake Analytics.
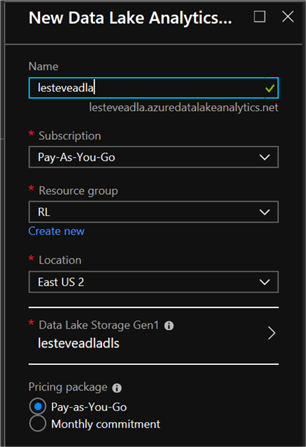
- In the New Data Lake Analytics Account blade, enter the following settings, and then click Create:
- Name: Enter a unique name
- Subscription: Select your Azure subscription
- Resource Group: Create a new resource group
- Location: Select a resource
- Data Lake Store: Create a new Data Lake Store
Creating an Azure Data Lake Database
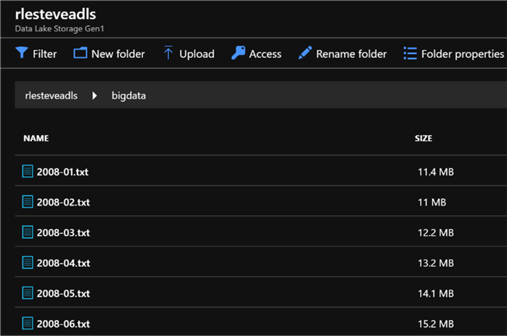
By creating a database, I’ll be able to store data in a structured and query able format. For this article, I will upload a collection of 6 log files containing data 6 months of log data.
Once I’ve uploaded my files, I will click on the blade for my Azure Data Lake Analytics account and then click New Job.
I will then name it Create ADL DB:
In the code editor, I’ll enter the following code and then click submit:
CREATE DATABASE IF NOT EXISTS logdata;
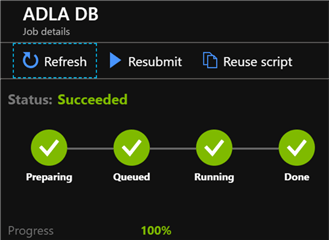
Once the job has successfully completed running, I will navigate to my Azure Data Lake Analytics account and then click Data Explorer. I can see that the logdata database has been created in my ADLA account within the catalog section.
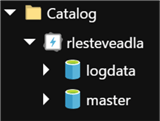
Creating a Schema and Table in Azure Data Lake
Since I now have a database, I can go ahead and create a schema and table, much like I would in SQL SERVER with T-SQL.
Once again, I will click New Job, and then create a new Job called Create Schema and Table.
Within my code editor, I will enter the following code, which will create a schema named iis and a table named log in the logdata database:
USE DATABASE logdata;
CREATE SCHEMA IF NOT EXISTS iis;
CREATE TABLE iis.log
(date string,
time string,
client_ip string,
username string,
server_ip string,
port int,
method string,
stem string,
query string,
status string,
server_bytes int,
client_bytes int,
time_taken int?,
user_agent string,
referrer string,
INDEX idx_logdate CLUSTERED (date))
DISTRIBUTED BY HASH(client_ip);This newly created table will have a clustered index on the date column, and the data will be distributed in the data lake store based on a hash of the client_ip column. As we can see the time_taken column is declared with the data type int?. The ? character indicates that this numeric column allows NULL values. Note that the string data type allows NULLs by default.
Once the job has successfully completed running, I will navigate to my Azure Data Lake Analytics account and then click Data Explorer. When I expand table, I can see that the iis.log table along with its columns and indexes have has been created in my ADLA account under Catalog.

Inserting Data into the Table in Azure Data Lake
Now that I have a database, schema, and table I can start entering data into my newly created Azure Data Lake Database.
Once again, I will begin this process by navigating to my Azure Data Lake Analytics account, and then I will click New Job and name the job Insert Data.
In the code editor, I will enter the following code and run the job, which will read all files with a .txt extension from the iislogs folder into the schema that matches the table and will then insert the extracted data into the table.
USE DATABASE logdata;
@log =
EXTRACT date string,
time string,
client_ip string,
username string,
server_ip string,
port int,
method string,
stem string,
query string,
status string,
server_bytes int,
client_bytes int,
time_taken int?,
user_agent string,
referrer string
FROM "/bigdata/{*}.txt"
USING Extractors.Text(' ', silent:true);
INSERT INTO iis.log SELECT * FROM @log;Once the job completes running successfully, I can see the Job graph which specifies the number of files loaded, the number of rows loaded, and the stage progress.
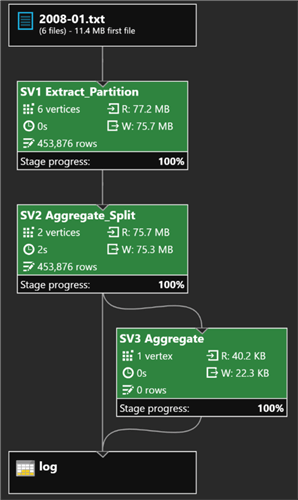
Querying a Table in Azure Data Lake
Once this job completes running, I will return to my Azure Data Lake Analytics account and click Data Explorer. Under Catalog, I will select iis.log and then click Query Table.
I can modify the default query by replacing with the following code, which will query the table and return the first 10 rows ordered by date and time and then run the job:
@table = SELECT * FROM [logdata].[iis].[log]
ORDER BY date, time
FETCH FIRST 10;
OUTPUT @table
TO "/Outputs/logdata.iis.log.tsv"
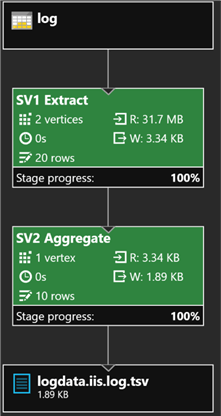
USING Outputters.Tsv();Once the job successfully completes, I will click the Output tab and select logdata.iis.log.tsv to preview the results and verify that the table now contains data. Additionally, I can see from the job graph that 10 rows were aggregated and exported to my logdata.iis.log.tsv file.
Creating a View in Azure Data Lake
Views are commonly used in relational databases and are supported in U-SQL by using the CREATE VIEW statement.
Once again, I will navigate to my Azure Data Lake Analytics account and click New Job, naming it Create View.
I’ll then enter the following code to create my view, which will retrieve aggregated values from the log table.
USE DATABASE logdata;
CREATE VIEW iis.summary
AS
SELECT date,
COUNT(*) AS hits,
SUM(server_bytes) AS bytes_sent,
SUM(client_bytes) AS bytes_received
FROM iis.log
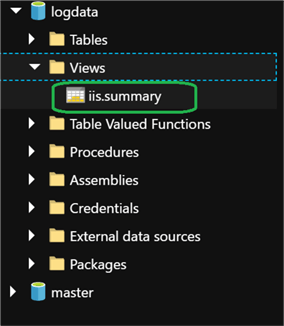
GROUP BY date;Once the job completed running successfully, I can navigate to my Azure Data Lake Analytics account and click Data Explorer. Under views within my logdata db, I can see that my view has been created.
Querying a View in Azure Data Lake
Now that I have created my view, I can begin querying my view by navigating to Data Explorer, under Catalog, expand Views, and select iis.summary. Then click Query View.
Modify the default query as follows and run the query, which will query the view and return the output ordered by date:
@view = SELECT * FROM [logdata].[iis].[summary];
OUTPUT @view
TO "/Outputs/logdata.iis.summary.tsv"
ORDER BY date
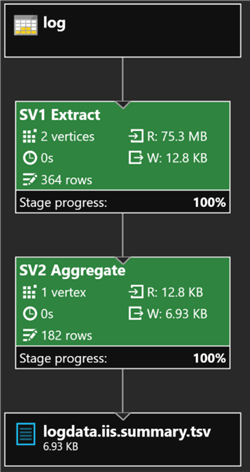
USING Outputters.Tsv();After the job completes successfully, I will click the Output tab and select logdata.iis.summary.tsv to see a preview of the results. Additionally, from the job graph I can see that 182 rows were aggregated and exported to the file logdata.iis.summary.tsv.
Creating a Table-Valued Function in Azure Data Lake
Table-valued functions provide another way to encapsulate a query that returns a row- set. Additionally, table-values functions can include parameters; making them more flexible than views in some scenarios.
To create a Table-valued function, I will navigate to my Azure Data Lake Analytics account and click New Job and name it Create TVF.
In the code editor, I’ll enter the following code and run the job, which creates a function named summarizelog that retrieves data from the summary view for a specified year and month:
USE DATABASE logdata;
CREATE FUNCTION iis.summarizelog(@Year int, @Month int)
RETURNS @summarizedlog TABLE
(
date string,
hits long?,
bytes_sent long?,
bytes_received long?
)
AS
BEGIN
@summarizedlog =
SELECT date,
hits,
bytes_sent,
bytes_received
FROM iis.summary
WHERE DateTime.Parse(date).Year == @Year
AND DateTime.Parse(date).Month == @Month;
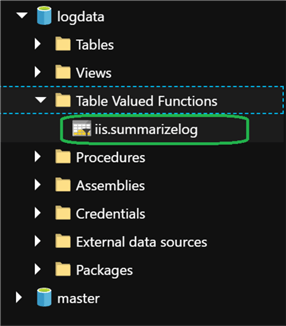
END;After the job completes running successfully, I will navigate to my Azure Data Lake Analytics account and click Data Explorer. I can see that the TVF has been created.
Querying a Table-Valued Function in Azure Data Lake
Now that I have created a table-valued function, I can query it by navigating to my Azure Data Lake Analytics account, clicking New Job, naming it Query TVF and entering the following code in the code editor:
USE DATABASE logdata;
@june = iis.summarizelog(2008, 6);
OUTPUT @june
TO "/Outputs/june.csv"
ORDER BY date
USING Outputters.Csv(); I’ll then run this code, which calls the summarizelog function, specifying the parameters for June 2008 and returns the output ordered by date.
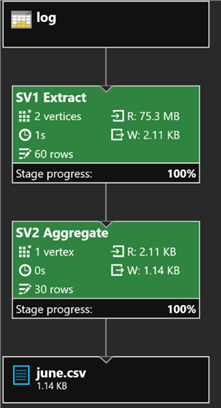
Once the job completes running, I will click the Output tab and select june.csv to see a preview of the results, and note that each row in the data contains a daily summary of hits, bytes sent, and bytes received for June 2008
Creating a Stored Procedure in Azure Data Lake
Stored Procedures provide a way to run tasks, such as extracting data from files and inserting it into tables.
To create my stored procedure, I will navigate to my Azure Data Lake Analytics account, click New Job, and then name the job Create SP.
I’ll then enter and run the following code in the code editor, which will create a procedure named LoadLog that loads data from the specified file path into the log table:
USE DATABASE logdata;
CREATE PROCEDURE iis.LoadLog (@File string)
AS
BEGIN
@log =
EXTRACT date string,
time string,
client_ip string,
username string,
server_ip string,
port int,
method string,
stem string,
query string,
status string,
server_bytes int,
client_bytes int,
time_taken int?,
user_agent string,
referrer string
FROM @File
USING Extractors.Text(' ', silent:true);
INSERT INTO iis.log
SELECT * FROM @log;
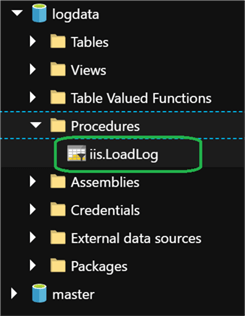
END;Once the job completes running, I will navigate to me logdata db and verify that the Stored Procedure has been created:
Running a Stored Procedure in Azure Data Lake
Now that my stored procedure has been created, I can test it by uploading a new file to my Azure Data Lake Storage account and then run the stored procedure to test if the file loads to my logdata db.
After I upload my new data file to my storage account and then run my stored procedure by selecting iis.LoadLog and then clicking Run Procedure, I’ll enter the following code in the code editor:
[logdata].[iis].[LoadLog]("/bigdata/2008-07.txt");This code uses the LoadLog procedure to load the data from the 2008-07.txt file in the bigdata folder into the log table. Once the job finishes, I can see from the job graph that the new data has been loaded:
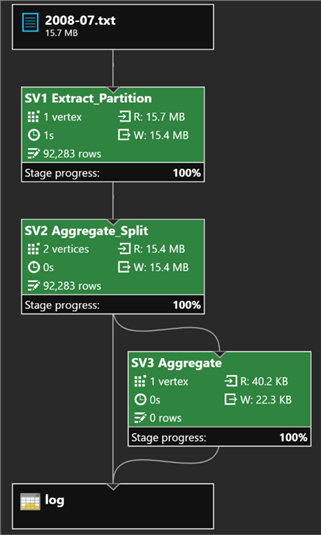
Next, I will run the following code as a new job which I will name Get July:
USE DATABASE logdata;
@july = iis.summarizelog(2008, 7);
OUTPUT @july
TO "/Outputs/july.csv"
ORDER BY date
USING Outputters.Csv();This code calls the function, specifying the parameters for July 2008, returns the output ordered by date.
Once the Job successfully completes, I will click the Output tab and select july.csv to see a preview of the results and note that each row in the data contains a daily summary of hits, bytes sent, and bytes received for July 2008. This data was inserted into the log table by the LoadLog procedure, and then queried through the summary view by the summarizelog table-valued function.
Next Steps
- In this article, we created and queried an Azure Data Lake Database, Schema, Table, View, Table-Valued Function and Store Procedure.
- For more information about the U-SQL CREATE TABLE syntax, see the documentation at https://msdn.microsoft.com/en-us/library/mt706196.aspx.
- For more information related to Azure Data Lake Analytics and U-SQL, check out my articles on

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


