Problem
I am an ETL developer and know about ETL processes, but now I keep hearing about ELT. What’s the difference in SQL Server?
Solution
What is ETL?
ETL (Extraction, Transformation and Loading) is a data integration method where data from one or more source systems is first read (i.e. extracted), then made to go through some changes (i.e. transformed) and then the changed data is written to a target system (i.e. loaded).
ETL processes are different from regular data migration in the sense that:
- ETLs are typically used for loading data from one or more source systems to a single data mart or data warehouse.
- ETL processes involve "transforming" data, which means source data is changed in transit.
- ETL processes are typically developed for long-time deployment and operation. The data pipeline becomes an integral part of the data ecosystem.
- ETL processes are usually run from a dedicated ETL server or managed environment in the cloud.
The image below shows data flow in ETL:
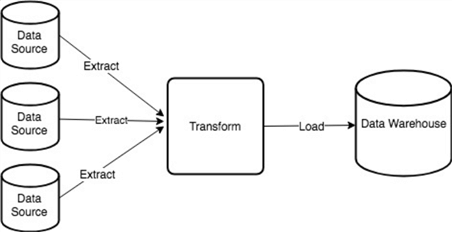
Enterprises have been using ETLs for many years and there any many established tools in the market today; SQL Server Integration Service (SSIS) is one such tool. Today’s ETL tools can connect to a plethora of data sources, including non-relational data, and load to an equally varied number of destinations. A typical ETL workflow will:
- Periodically connect to one or more operational data sources such as an ERP, CRM or SCM. This is usually a nightly process.
- Extract batches of rows from one or more source system tables based on some criteria. For example, it will read all rows since the last batch of data was loaded.
- Copy the extracted data to a staging area. This can be another RDBMS of the same type or a blob storage.
- Perform transformation on the staged data. These transformations:
- Are done in-memory or in temporary tables on disk.
- Can be iterative in nature (for example, aggregating batch of rows per customer transaction).
- May involve transactions, so any in-process error may abort the whole operation.
- Usually write the process outputs to log files for debugging.
- Can involve operations like data cleansing, filtering, converting data types, formatting, enriching, applying lookups and calculations, masking, removing duplicates, sorting and aggregating to name just a few.
- Connect to the target data warehouse and copy the processed data to one or more tables (for example, aggregated summary to measure tables and dimension data to dimension tables).
Modern ETLs have GUI canvasses and tool palettes to create data transformations and flows with minimal coding effort. Some tools have custom scripting language support, advanced conditional decision-making capability, error handling and debugging facility and even dedicated runtime schedulers.
The case for ELT
ETL processes are best suited for monolithic – and often legacy – data sources with transactional support for batch operations. Although these databases are usually OLTP (Online Transaction Processing) in nature, the speed of data insert, or update is not high. Data modification is primarily done by manual or batch processes.
Companies now also have to collect, process and store data from various other sources. With the proliferation of mobile applications, cloud-hosted systems, kiosks, videos, social media interaction and REST API based applications, data has to be collected from every touch point. There’s an explosion of data and the speed of that data is many times that of traditional OLTP systems. To make things more complicated, this new class of data is very often non-relational.
The highly dynamic, schema-less data is typically ingested into non-relational data stores like NoSQL databases, Hadoop file system or blob storage. From there they are transformed and processed into tabular format for analytics workload.
There’s also limited time to make business decisions from this data. Traditional business intelligence reports are generated daily – or even weekly – after nightly data loads. With large volumes of streaming data, decisions are expected to be made on almost live data. A continuous live stream of stock market data is one such example.
ETL applications quickly slows down in such cases. The queues for incoming data become saturated and the transformation processes grind to halt, all resulting in unacceptable wait times for the user.
To address this challenge, an alternate data processing method called ELT (Extraction, Loading and Transformation) is used.
The main difference between ETL and ELT is where the data transformation is happening. Unlike ETL, ELT does not transform anything in transit. The transformation is left to the back-end database. This means data is captured from source systems and directly pushed into the target data warehouse, in a staging area. The transformation business logic then kicks-in within the database. The transformation process work son the raw, staged data and finally copies the processed data to a separate area. The following image illustrates this:

With ELT:
- The speed of data ingestion is high
- The pipeline does not have to do any heavy lifting
- The processing happens in the target data warehouse’s native language instead of ETL-native language
Another contributing factor to the rise of ELT is the rise and wide adoption of cloud data warehouses. Most cloud-hosted data warehouses are now managed, which means enterprises don’t need to purchase or manage any hardware or storage, install any software or think about scaling – the cloud provider takes care of everything. A cloud-hosted data warehouse like Amazon Redshift for example can be provisioned within minutes. Cloud data warehouse like Snowflake offers complete separation between compute and storage and the ability to store unlimited data.
Cloud data warehouses are run in powerful machines with multi-core processors, large amounts of RAM and high-speed SSD disk storage. Multi-node clusters remain online even if there is a failover of one or more nodes. The number of nodes can dynamically scale and up down based on load configuration. These are also known as Massively Parallel Processing (MPP) systems with columnar store. The MPP feature allows distributed, parallel processing of queries across all nodes’ CPU cores and the columnar storage mechanism allows quick retrieval of data.
All these features make cloud data warehouses ideal for transforming ingested data without significantly penalizing query performance.
ETL vs. ELT Differences
Obviously, the next logical question now arises: which data integration method is good – ETL or ELT?
The answer is, like so many other topics in IT: it all depends on the use case.
For example, with ETL, there is a large moving part – the ETL server itself. It may be hard to scale, it may be running on legacy version of a product that does not allow multi-node scaling, or it may be getting slow with larger volumes of data. Under such circumstances, adding or changing hardware is not a permanent solution.
But then, if the ETL system is working as expected, you don’t have to worry about anything – you have a tried and tested piece of technology that’s dependable. Also, your target database can be hosted in less-powerful, cheaper hardware, because it’s not transforming any data.
Moving to an ELT can mean certain benefits though. First of all, you don’t have to deal with two vendor products (one for ETL and another for the data warehouse) and worry about compatibility, drivers and support. The processing logic is native to the data warehouse. As long as the ELT tool can connect to source and destination systems, you know processing is the easy part.
Secondly, much of the moving machinery of the ETL server is gone, a less powerful machine can take care of extraction and loading which can result in cost saving. The need for dedicated ETL development skills is diminished as more SQL-savvy technicians build server-side processing logic.
On the flip side, moving to an ELT model can be difficult for existing ETL packages because all logic have to be refactored and rewritten for nonprocedural language and tested. Also, as raw data is ingested into the target database, there is a greater need to ensure data security.
Should I use ETL or ELT?
If you have a legacy ETL system that’s too difficult to port, but otherwise working without any issue – we recommend you leave it running. For new data warehouses, you may want to start playing with cloud-based solutions and ELT tools.
Some traditional ETL tools now offer ELT feature which can help migration really easy. Also, like managed data warehouses, there are managed ELT solutions from different vendors. It may be worthwhile to explore those options.
Sometimes ETL and ELT tools can work together to deliver value. For example, an ELT tool may extract data from various source systems and store them in a data lake, made up of Amazon S3 or Azure Blob Storage. An ETL process can extract the data from the lake after that, transform it and load into a data warehouse for reporting.
There are some basic questions to keep in mind when deciding between ETL and ELT and choosing a product:
- How often data needs to be ingested to the data warehouse?
- How busy will be the data warehouse serving user queries?
- What types of data transformation will be needed?
- Can the data warehouse natively handle those transformations?
- Does the integration tool have widgets for these transformations?
- How matured is the integration tool in the market?
- Does the tool support both ETL and ELT?
- What types of data sources and target systems are natively supported by the ETL or ELT tool?
- Is there native support for ANSI SQL?
- Does it use proprietary scripting language or is there support for well-known languages like Python, Java or PowerShell?
- Where does the tool run from: server-side or desktop?
- Is there a cloud-hosted, managed option available?
- Is there any option for scheduling the integration tasks?
- How does the tool scale with increased load?
- How is security handled in the tool?
- How does pricing and licensing work?
This is just a guideline and by no means an exhaustive list. What we are trying to highlight here is that you exercise due diligence.
Conclusion
As you can see, choosing a data integration method depends on a number of factors and that’s why it’s not an easy task. Fortunately, most ETL or ELT vendors offer time-limited free evaluation of their product. The following steps can help making the choice simpler:
- Creating a set of real-life use cases that’s tested with every tool
- Evaluating the performance and features of every tool against each use case
- Comparing the results for optimum balance between value, features and performance
Next Steps
- Learn more about modern cloud native data warehouses like Amazon Redshift, Google BigQuery or Snowflake
- Learn more about modern ELT tools like Fivetran or Alooma
- Learn more about modern ETL tools like Talend or Matillion

Sadequl Hussain lives in Sydney, Australia and holds a Bachelor’s degree in Electrical Engineering. His more than 15 years’ experience in IT has seen him in various roles including training, technical writing, web application development and database administration. Sadequl has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical database systems for various large companies. He is also an Oracle DBA and an avid Linux administrator. Over the years Sadequl has achieved various certifications including those from Microsoft, CompTIA and ITIL. He is currently having fun preparing for other ones from Amazon and the Open Group. He regularly contributes to various SQL Server and Linux online publications. Apart from spending time with his wife and daughter, he loves his part-time career as a photographer and film-maker and also loves to travel.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2017



Hello, Sadequl! Thanks for this helpful article about ETL and ELT workflows. I also recommend another one: https://skyvia.com/blog/elt-vs-etl. I think it complements your guide because it also describes cloud ETL and ELT solutions.