Problem
We configured SQL Server Always On Availability Groups from an on-premises SQL Server instance to a SQL Server instance running on an Azure Virtual machine and we were noticing a lot of error messages similar to the following in the SQL Server error log on the secondary server: "There have been X misaligned log IOs which required falling back to synchronous IO. The current IO is on file xxx". What is this caused from and how can this be fixed?
Solution
Currently we are working on an on-premises to Azure Migration using the IAAS solution provided by Microsoft. We are going to host our production databases in an on-premises datacenter in a clustered environment for high availability and we are going to use Availability Groups in Azure for DR.
We are using IAAS as we wanted to have full control on our servers and databases. We had hosted Azure premium storage using managed storage and we are using SSDs for faster performance and throughput. For high availability, we are using Availability Groups between the on-premises SQL Server cluster to an Azure standalone SQL Server.
We have setup Availability Groups between the on-premises SQL Server replicas to the Azure DR replica using SQL Server 2016. After we setup the Availability Groups between the production SQL Server (on-prem) and the DR SQL server (Azure), we started seeing multiple errors in the SQL Server error log every few minutes "There have been X misaligned log IOs which required falling back to synchronous IO. The current IO is on file xxx." (see screenshot below).
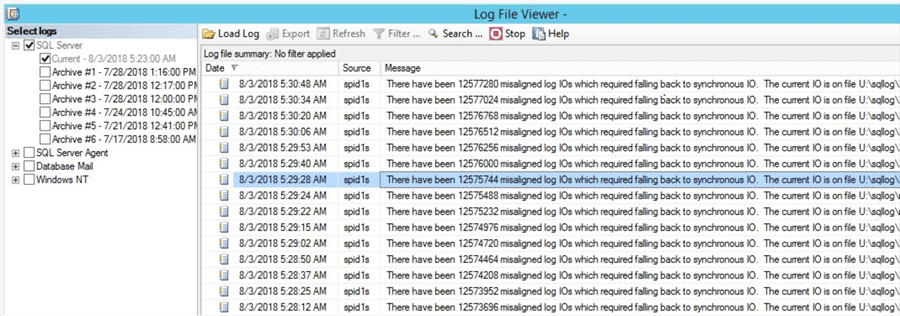
Looking at the error, we initially suspected the issue might be with a corrupt drive or the configuration between the on-premises server and the Azure server is not optimal in terms of network bandwidth. We had issues with the network for our migration and later we opened an express route to overcome the bandwidth issue.
We thought there might be some corruption when we setup the AG, as we did a manual setup of AG since the size of database as very large and using the AG wizard was taking too much time. Hence, we manually took a full and log backup and restored them to the Azure AG replica and then we joined the replica to AG through the Always On configuration wizard.
To omit the possibility of corruption in the database during the AG configuration we did reconfigure the AG, but to our surprise the issue was still there. After further investigating we found there was an issue with the drive’s physical sector configuration between the on-premises SQL Server and the Azure DR server.
To troubleshoot further, we looked at the drive properties with the help of Fsutil.exe. After running fsutil on both drives which hosted the SQL database we found that there was a physical sector mismatch between the on-premises SQL Server and the Azure SQL Server. The physical sector on the on-premises server was 512 bytes and on the Azure server it was 4096 bytes (4KB) and we later found out that this is a known Microsoft issue.
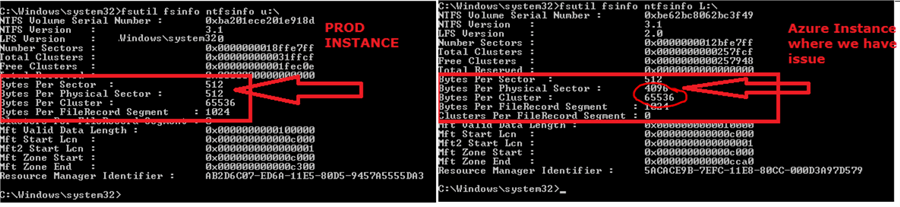
Now, we were at the bottom of the cause, but how do we resolve this.
Fixing Mismatched Physical Sector Settings for SQL Server
Let’s see how we can fix it.
As a best practice, Microsoft recommends having the same sector size for all disks on all replicas (at least all disks that host log files). In mixed environments, where the secondary has a physical sector of 512 bytes and the primary has a sector size of 4KB, we can use Trace Flag 1800 as a start-up flag on all servers or replicas that have the 512 byte physical sector size. This makes sure that the ongoing log creation format uses a 4KB sector size. Microsoft recommends enabling trace flag 1800 to overcome this issue.
Steps to Enable SQL Server Trace Flag 1800
We can enable trace flag 1800 using DBCC TRACEON and this change will take immediate effect.
dbcc traceon (1800, -1)
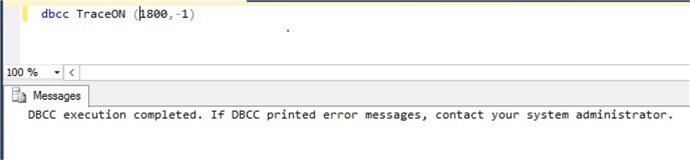
After you enable the trace you will see below message in the error log.
only; no user action is required.
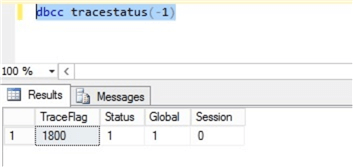
You can confirm if the trace flag is enabled by running DBCC Tracestatus (-1) and you will see all trace flags that are running on the server.
To ensure the trace flag remains in place after restart, we will have to add the trace flag as a startup parameter as shown below, we added "-T1800" as a parameter. (Note: I hid some of my server information in the red rectangle below).

This will ensure that if SQL Server restarts the trace flag will be enabled as a startup parameter and there will be no need of manual intervention afterwards.
Note: We have to enable trace flag only on replicas where we have a 512-byte sector size as per Microsoft’s recommendation. The secondary replica has a 4KB sector size, so we don’t need to enable the trace flag there.
Summary
The issue was resolved after enabling trace flag 1800 on all replicas. It took some time for the messages to go away from the SQL Server error logs. You might continue to see errors in the SQL Server error log even after applying the fix and this an indication that the AG agent is still replicating some portions of the log that were written in the old format from the primary to the secondary and it will eventually catch up.
If you still see issue in your environment, then you can try the below options to see if it fixes the issue.
- Restart the secondary replica to see if that makes a difference.
- If the databases are not too big, try to reinitializing the secondary replica.
Next Steps
Here is some additional reading:
- Frequently asked questions for SQL Server running on Windows Azure Virtual Machines
- https://blogs.msdn.microsoft.com/alwaysonpro/
- https://docs.microsoft.com/en-us/azure/virtual-machines/windows/sql/virtual-machines-windows-sql-performance

Atul Gaikwad has over 14+ years of experience with SQL Server. He currently works for one of the leading MNCs in Pune as a Delivery Manager handling small to large SQL Server production support projects. He is technology savvy and believes in automation and innovation. He likes to automate anything and everything which can help save time and make a DBAs life effortless and smooth, to focus on larger projects. He has extensive hands on experience in SQL Server administration and high availability solutions like clustering, replication, log shipping, mirroring, etc. He also possesses strong knowledge of SSRS and SSIS.
- MSSQLTips Awards: Rookie of the Year Contender – 2016

the TF must be enabled on the replica with 512bytes. In my case it was my primary, after a server upgrade. enabling TF with DBCC TRACEON has no effect. SQL service must be restarted.
Will this solution work when the situation is reversed? so when the Primary is 512K and the replica are 4K does setting the trace flag on the primary resolve this issue?