Problem
In the first part of this tip series, we covered different methods of filtering and polishing datasets. Thereafter, data analysts often find a need to change the granularity of data by aggregating it. For example, to consume the data in a visualization like a histogram, one may need to bin the data in different buckets and a count of the data for each bucket may be required. Another such example would be that if a million records are rendered on a scatterplot, the entire visual would look like a black screen. So, one would need to make the data more focused, take a filtered fraction of the data and then analyze it in one scatterplot. Such data processing techniques can be made easier, if there is a ready to use function for it instead of developing custom logic for these types of needs. In this tip, we will discuss data processing at the next level with topics like data aggregation, data sampling, command chaining and much more.
Solution
Before you get started with this tip, be sure you read part 1 first.
The dplyr package is a powerful R-package to transform and summarize tabular data with functions like summarize, transmute, group_by and one of the most popular operators in R is the pipe operator, which enables complex data aggregation with a succinct amount of code. Let’s go ahead and see this in action.
Advanced functions of dplyr library
We will cover some of the advanced functions in this package below.
Create user-defined columns with mutate() and transmute()
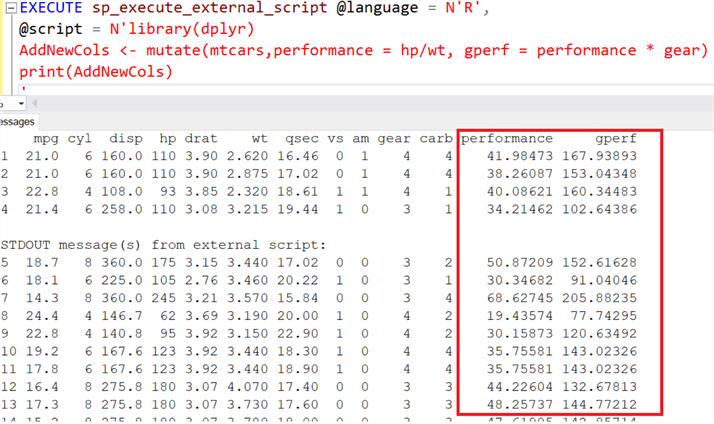
The mutate() function in the dplyr library lets you add as many new calculated columns as you need to in the data frame. Like other verbs of the dplyr package, we will pass data as the first argument in mutate() and definition of new column(s) in the subsequent arguments. Additionally, it also allows us to create new columns that refer to the columns that you have just created in the same line of command. Let’s go ahead and create two new columns as 1. performance (which is the ratio of existing columns hp to wt) and 2. gperf (that uses a newly created column performance in its computation). We will use one of the famous datasets in R – mtcars to return all the columns and two new computed columns as shown below.
EXECUTE sp_execute_external_script @language = N'R',
@script = N'library(dplyr)
AddNewCols <- mutate(mtcars,performance = hp/wt, gperf = performance * gear)
print(AddNewCols)
'
1.1 transmute() to display only new columns
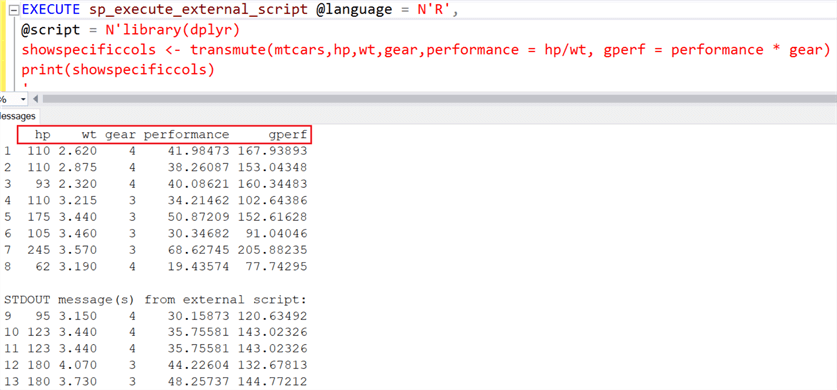
If you notice above, the mtcars dataset has a relatively lesser number of variables than what data professionals in real scenarios actually have to deal with. When creating new computed columns in the larger datasets (with numerous existing columns), it becomes tedious and challenging to keep track of the columns that are of actual interest to the developer using mutate(). Having a function like transmute() that will not only keep columns mentioned in the function, but also return new calculated columns, proves to be beneficial. An example of how transmute() with mtcars dataset looks like is shown below.
EXECUTE sp_execute_external_script @language = N'R',
@script = N'library(dplyr)
showspecificcols <- transmute(mtcars,hp,wt,gear, performance = hp/wt, gperf = performance * gear)
print(showspecificcols)
'
Data aggregations with summarise() and group_by() using dplyr >> GROUP BY (SQL keyword equivalent)
The summarise() function is used to summarize multiple values into a single value with the help of aggregate functions like min(), max(), mean(), sum(), median(), etc. While calculating the aggregated value, we can use ‘na.rm = TRUE’ to remove all NA values in order to avoid invalid results. The following line of code calculates mean value of the number of cylinders used and we have named the summary value to be returned as ‘cylmeanvalue’ in the result set.
EXECUTE sp_execute_external_script @language = N'R',
@script = N'library(dplyr)
cylmeanvalue <- summarise(mtcars,cylmeanvalue = mean(cyl,na.rm = TRUE))
print(cylmeanvalue)
'

The summarise() function when synchronized with the group_by() function in dplyr becomes very powerful and efficient as they work together to create a GROUP BY clause in SQL. The group_by function is used to group data by one or more columns. As a SQL developer, in retrospect, I used to have issues using the GROUP BY clause in the initial stages of learning T-SQL. This probably was due to the fact that, it is mandatory to include the columns referenced in the GROUP BY clause in the SELECT statement and with any aggregate functions used. The upper edge of using group_by() in dplyr is that we just need to mention the column(s) that needs to be grouped using the group_by clause and the aggregate function in the summarize clause.
In the example below, we are grouping the data together based on the type of cylinders (4,6,8) and then using the summarise function (SUM) to calculate total gear values for each cylinder.
EXECUTE sp_execute_external_script @language = N'R',
@script = N'library(dplyr)
groupbycyl <- summarise(group_by(mtcars,cyl),totalgears = sum(gear, na.rm = TRUE))
print(groupbycyl)
'

We walked through the dplyr library comprising of a set of tools for various data transformation operations. There are several more important functions (like slice(), join, sample_frac(), top_n, glimpse(), etc.) in the dplyr package that make data manipulation and analysis easier for data analysts, however, for the sake of brevity, we won’t be covering them here. You can refer to this link to learn more about the rest of the functions in dplyr.
Pipe Operator in dplyr
All these functions or verbs covered so far are used to perform simple and independent operations like creating subsets of the data or creating a calculated column or filtering rows based on certain conditions. But, working on a complex data processing logic often requires you to employ multiple operations on the dataset, for example we want to select and filter data after performing some aggregations on it. This can be achieved either by using nested queries or by using intermediate variables to make multiple assignments. Both of these options come with its own share of problems like difficulty to read the process from inside out and consumption of memory space respectively.
Here is when the pipe operator in dplyr comes to the rescue. The pipeline operator helps you to connect multiple functions or operations into a single pipeline and is denoted as '%>%'. This operator allows taking the output of one function and sending it to the next and it processes them from left to right. Let's quickly jump over the working of pipe operator to see how efficient and easier the code becomes by using them.
Basic syntax of using pipes in dplyr – Data %>% Operation1 %>% Operation2 %>% Operation3….
Let’s execute the code below to subset data using the pipe operator. Here, we are use the pipe to send the mtcars dataset first, we will keep the rows where mpg is greater than 25, using the filter() function and then with the function select() to keep a few columns and finally sorting the resultset on column hp in descending order. This approach of using pipe operators is so straight forward to use and read that there is no need to pass the data as an argument every time we use different functions with pipes with the dplyr package.
EXECUTE sp_execute_external_script @language = N'R',
@script = N'library(dplyr)
FilteredData <-mtcars %>% filter(mpg >25) %>% select(mpg,hp,cyl,drat,vs,carb) %>% arrange(desc(hp))
print(FilteredData)
'

Filtering aggregated data using pipe operator >> WHERE/HAVING (SQL keyword equivalent)
Developers often use nested subqueries in T-SQL to chain multiple operations together and in dplyr, pipes are typically used to link a sequence of functions. Such chaining of functions with a pipe is far more liberal than the structure of nested SQL subqueries especially when we have to use aggregate functions along with other operations. For instance, here we intend to do the following operations on mtcars dataset:
- Compute average of hp and compare it with the actual value of hp in each row using mutate().
- Selecting a few columns in the result set using select().
- Grouping data by gear column using group_by().
- Filtering grouped data for cyl column as 4 using filter().
- Sorting the result data in the descending order of gear using arrange().
EXECUTE sp_execute_external_script @language = N'R',
@script = N'library(dplyr)
ComputedData <- mtcars %>% group_by(gear) %>% filter(cyl ==4) %>% mutate(meanhp = mean(hp),newmean = mean(hp) - hp) %>% select(mpg,cyl,hp,wt,gear,meanhp,newmean) %>% arrange(desc(gear))
print(ComputedData)
'

A quick comparison of the conventional way of writing the above query with nested functions vs the pipe operator is shown below. It is difficult to comprehend the code from inside out in the nested functions, whereas, with pipe operator code is cleaner and easier to read.
With Nested Functions:
arrange(select(mutate(filter(group_by(mtcars,gear),cyl ==4), meanhp = mean(hp),newmean = mean(hp) - hp),mpg,cyl,hp,wt,gear,meanhp,newmean),desc(gear))
With Pipe Operator:
mtcars %>% group_by(gear) %>% filter(cyl ==4) %>% mutate(meanhp = mean(hp),newmean = mean(hp) - hp)%>% select(mpg,cyl,hp,wt,gear,meanhp,newmean)%>% arrange(desc(gear))
Sampling data for visualizations using sample_frac() and filter() dplyr functions
This brings us to the last leg of this series. We will need a voluminous data set that also contains some trend to simulate data exploration graphs like scatter plots, histograms, box plots, etc. We will also learn how quickly we can inspect the data using dplyr function with scatter plots.
We need to install the library ggplot2 in the same way we installed dplyr package to execute the below code. Once we have this package in place, execute the below code.
EXECUTE sp_execute_external_script
@language = N'R',
@script = N'
library(ggplot2)
jpeg(filename="C:\\temp\\plots\\DiamondsData.jpeg", width = 980, height = 980, units = "px", pointsize = 20, quality = 100,);
plot(diamonds$carat,diamonds$price, col = diamonds$cut, main="Diamonds data",xlab="Carat ",
ylab="Diamond Price ($)", pch=19 )
legend("topright", legend=c("Ideal", "Premium", "Good", "Very Good","Fair"), col = c(1:5), lty="solid")
dev.off();
'

In the above code, we are using the library ggplot2 which contains the diamonds dataset. Then we are opening the graphics device using the jpeg function and passing different rendering parameters to it. Then we are rendering a scatterplot using the most used plotting function in R programming – plot() function, and finally saving the file to the desired location. The final plot output of the entire dataset can be seen above and a data analyst or data scientist would not be able to conclude anything from it. Let’s say that we need to take a focused look at this dataset where we want only a fraction of the data having the desired attributes – for example clarity of the diamonds should be IF / VVS2 / VS1 / VS2. This sampling and filtering can be performed on the dataset using the sample_frac() function chained with the filter function using %>% pipe operator as shown in the below code.
EXECUTE sp_execute_external_script
@language = N'R',
@script = N'
library(dplyr)
library(ggplot2)
jpeg(filename="C:\\temp\\plots\\SampledDiamonds.jpeg", width = 980, height = 980, units = "px",
pointsize = 20, quality = 100,);
diamonds <- diamonds %>% sample_frac(0.1) %>% filter(clarity %in% c("IF","vvs1","vvs2","vs1","vs2"))
plot(diamonds$carat,diamonds$price, col = diamonds$cut, main="Diamonds data",xlab="Carat ",
ylab="Diamond Price ($)", pch=19 )
legend("topright", legend=c("Ideal", "Premium", "Good", "Very Good","Fair"), col = c(1:5), lty="solid")
dev.off();
'

The final output of the plot would look as shown above. The plot looks more focused with filtered data of interest, instead of an overpopulated scatterplot. This is one of the basic exercises performed for exploratory data analysis and dplyr can make the job much easier with its built-in functions and operators.
Summary
The dplyr package with its umpteen functions caters to a variety of data processing needs in a data science project. We covered some of the most powerful functions and operators in this package that assist data professionals to increase efficiency and have improved readability with lesser efforts in the project. We also observed, how we can generate basic graphs using T-SQL to have quick insight into the data without involving external reporting tools like SQL Server Reporting Services or any other visualization platforms like Power BI.
Next Steps
- You can refer to the dplyr package manual here to learn more about this functions and operators offered by this package.
- For more information on SQL Server and R related topics, refer to these other tips.

Gauri Mahajan is a SQL Server Professional with 6+ years of experience of working with global multinational consulting and technology organizations. She is very passionate about SQL Server Reporting Services, R, Python, Power BI, Database engine, etc. She has years of experience in technical documentation and enjoys writing. She has deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and has passed the 70-463: Implementing Data Warehouses with Microsoft SQL Server exam.
- MSSQLTips Awards: Author of the Year Contender – 2019