Problem
A derived table is a subquery nested within a FROM clause. Because of being in a FROM clause, the subquery’s result set can be used similarly to a SQL Server table. The subquery in the FROM clause must have a name. One reason for including a derived table in an outer query is to simplify the outer query. This is because you can bury the complexity of a subquery in a derived table in a FROM clause and refer to subquery result column values in the derived table. Because you can treat derived tables like regular SQL Server tables, you can join two or more derived tables. Also, you can nest queries referencing a derived table inside of one another. A code sample in this part of the tutorial demonstrates this derived table capability for the enumeration of duplicate records in a data source.
Solution
For the examples below we are using the AdventureWorks2014 database. Download a copy and restore to your instance of SQL Server to test the below scripts.
Creating a Basic Derived Table
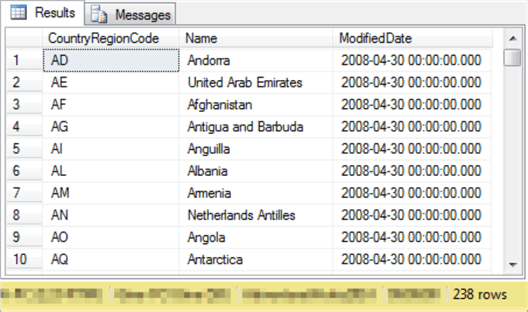
The following query will serve as the subquery for a derived table. It is often a good idea to examine the result set from a query before using the T-SQL for the subquery in a derived table. The following query lists the values for the three columns from the CountryRegion table in the AdventureWorks2014 database. Each row in the table is for a country. The CountryRegionCode column is the primary key for the CountryRegion table. This code is a short nvarchar data type field value that represents a country; you can think of it as a country name abbreviation. The Name column is the full name of the country on a row in the table. The ModifiedDate column is a datetime field denoting the last datetime the row was entered or changed, whichever is most recent.
-- columns of data from CountryRegion table in Person schema
SELECT
[CountryRegionCode],
[Name],
[ModifiedDate]
FROM [AdventureWorks2014].[Person].[CountryRegion]
Here’s an excerpt from the first ten rows in the result set from the preceding query. Notice from the right-hand corner of the display that there are two hundred thirty-eight rows in the full result set.
The next T-SQL code block is for a very basic derived table example. The inner-most query in the following script contains the query for the three columns from the CountryRegion table in its FROM clause. The subquery in the FROM clause has the name my_derived_table. The outer-most query uses the derived table as its source. In addition, three special operations are performed.
- First, a column named Country Alphabet index leads the list of SELECT items. This is a computed column based on the Name field from the inner-most query. The substring function extracts the first letter of the Name column value from the inner-most query.
- Second, the next SELECT item assigns an alias of Country Name to the Name column from the inner-most query. When the result set is displayed by a SELECT statement, it appears with the name of its alias. However, you must still reference the Name column from the inner-most query by its un-aliased name in SELECT list items as well as WHERE and ORDER BY clauses.
- Third, the outer-most query also sorts its result set by the first character of the Name column value from the derived table.
-- country name and country region code in alphabetical order
-- alphabetized by country name
SELECT
SUBSTRING(name, 1, 1) [Country Alphabet index],
name [Country Name],
[CountryRegionCode]
FROM ( -- columns of data from CountryRegion table in Person schema
SELECT
[CountryRegionCode],
[Name],
[ModifiedDate]
FROM [AdventureWorks2014].[Person].[CountryRegion]
) my_derived_table
ORDER BY LEFT(name, 1)
Here’s an excerpt showing the first ten result set rows from the preceding script. The columns are not all identical to those in the derived table.
- The first column has the name Country Alphabet index. The value for this index is just the first letter for the name of a country extracted via the substring function.
- The second column has a column header of Country Name, which is the alias for Name from the derived table.
- The third column has the same name as in the derived table – CountryRegionCode.
- The third column from the derived table is filtered out in the outer-most query. The filtering is performed by failing to include the column name ModifiedDate in the outer-most query.
- The order of rows in the result set is based on the ORDER BY clause at the end of the query. Notice that T-SQL code references the un-aliased name (name) and not the aliased name (Country Name) in the ORDER BY clause.
- Finally, notice that there are two hundred thirty-eight rows in the result set of the outer-most query. All the rows from the derived table pass through to the outer-most query. However, you can optionally use a filter in a WHERE clause to limit the passing of rows from the derived table to the outer-most query.

Joining Derived Tables
This section introduces two additional tables from the Adventureworks2014 database. The first of these tables is the CountryRegionCurrency table, and the second additional table is the Currency table.
- The CountryRegionCurrency table is a junction table between the CountryRegion table and the Currency table.
- The primary key for the CountryRegionCurrency table is a composite key based on two fields: CountryRegionCode and CurrencyCode. Recall that:
- The CountryRegionCode is also the primary key for the CountryRegion table.
- The CurrencyCode is also the primary key for the Currency table.
- Each row in the CountryRegion table can match zero, one, or more than one row in the Currency table.
- Each row in the Currency table can match one or more rows in the CountryRegion table.
The following T-SQL scripts list all the rows in CountryRegionCurrency and Currency tables. A script for listing the rows of the CountryRegion table appears in the preceding example.
-- columns of data from CountryRegionCurrency table in Sales schema
SELECT
[CountryRegionCode],
[CurrencyCode],
[ModifiedDate]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency]
----------------------------------------------------------------------------------
-- columns of data from Currency table in Sales schema
SELECT
[CurrencyCode],
[Name],
[ModifiedDate]
FROM [AdventureWorks2014].[Sales].[Currency]
Here’s an excerpt with the first ten rows from each of the two preceding queries.
- The top pane depicts rows from the CountryRegionCurrency table.
- The bottom pane shows rows from Currency table.
- Not shown in the excerpt below is the count of rows in each table. There are 109 rows in the CountryRegionCurrency table, and 105 rows in the Currency table.
- Since there 238 rows in the CountryRegion table, this confirms that there are many countries in the CountryRegion table without a matching currency in the Currency table.
- Similarly, since the number of rows in the Currency table is less than the number of rows in the CountryRegionCurrency table this confirms that some countries can have more than one matching currency.
- The top pane illustrates the preceding point in its third and fourth rows.
- Both rows are for Austria, which has a value of AT for its CountryRegionCode.
- The third row references the Austrian Shilling (ATS) as a currency.
- The fourth row denotes the Euro (EUR) as a currency.

The next script shows how to specify an inner join between two derived tables – one based on the CountryRegion table and the other based on the CountryRegionCurrency table.
- The derived table labelled cr returns a result set of 238 rows from the CountryRegion table.
- The derived table labelled crc returns a result set of 109 rows from the CountryRegionCurrency table.
- The inner join operator and its matching on keywords (CountryRegionCode) indicate that each row in the cr derived table result set should be matched to as many rows in crc derived table result set whenever the CountryRegionCode value is the same in both tables.
- Because there are just 109 rows in the crc derived table and each of its rows match one row in the cr derived table, the result set for the outer query contains 109 rows.
-- there are 109 country-currency pairings
-- this query demonstrates an inner join with derived tables
-- some countries have more than one matching currency
SELECT
cr.CountryRegionCode,
cr.Name [Country Name],
crc.CurrencyCode
FROM ( -- there are 238 country region codes
SELECT
[CountryRegionCode],
[Name],
[ModifiedDate]
FROM [AdventureWorks2014].[Person].[CountryRegion]
) cr
INNER JOIN
( -- there are 109 currency codes in CountryRegionCurrency
SELECT
[CountryRegionCode],
[CurrencyCode],
[ModifiedDate]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency]
) crc ON cr.CountryRegionCode = crc.CountryRegionCode The following excerpt displays the first ten rows from the outer-most result set.
- The result set has three columns based on the SELECT list items from the outer query in the preceding script.
- The columns are for
- CountryRegionCode from the cr derived table
- Name from the cr derived table; this field is assigned an alias name of Country Name
- CurrencyCode from the crc derived table
- Because of the inclusion of Country Name for matching CountryRegionCode values, users of the listing can quickly translate from a CountryRegionCode value to its matching country name.
- With the inclusion of country name in the result set, it is easy to determine that Austria and Belgium have multiple currency types in the result set.

One potential way to improve the usefulness of the preceding result set is to add currency name as a column. You can achieve this outcome by adding a left join of rows from the Currency table to the rows of the CountryRegionCurrency table in the preceding query. The following script illustrates how to accomplish this outcome with derived tables.
- This outer-most query references three derived tables.
- The cr derived table is for rows from the CountryRegion table.
- The crc derived table is for rows from the CountryRegionCurrency table.
- The c derived table is for rows from the Currency table.
- The outer-most query from the following script adds relative to the preceding script a left join and an ORDER BY clause.
- The left join facilitates the inclusion of currency name in the result set.
- The ORDER BY clause sorts the result set CountryRegionCode.
- The script below illustrates the syntax for a left join between two derived tables. A left join is generally a good design feature to use when different column values from one data source can match more than one column value from another data source. The left join below is between the c derived table and the crc derived table.
- The ORDER BY clause at the bottom of the outer-most query specifies the sort order for the rows in the result set. The sort order is by CountryRegionCode column values from the cr derived table.
-- there are 109 country-currency pairings
-- some countries have more than one matching currency
-- this query adds currency name to the result set via
-- a left join
SELECT
cr.CountryRegionCode [Country Region Code],
cr.Name [Country Name],
crc.CurrencyCode [Currency Code],
c.Name [Currency Name]
FROM
( -- there are 238 country region codes
SELECT
[CountryRegionCode],
[Name],
[ModifiedDate]
FROM [AdventureWorks2014].[Person].[CountryRegion]
) cr
INNER JOIN
( -- there are 109 currency codes in CountryRegionCurrency
SELECT
[CountryRegionCode],
[CurrencyCode],
[ModifiedDate]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency]
) crc ON cr.CountryRegionCode = crc.CountryRegionCode
LEFT JOIN
( -- columns of data from Currency table in Sales schema
SELECT
[CurrencyCode],
[Name],
[ModifiedDate]
FROM [AdventureWorks2014].[Sales].[Currency]
) c ON crc.CurrencyCode = c.CurrencyCode
ORDER BY cr.CountryRegionCode
The screen shot below shows the top ten rows from the preceding script. Notice that it is the same as the preceding screen shot — except for the addition of a new column named Currency Name.

Detecting Duplicate Rows with a Subquery Based on a Derived Table
Duplicate rows in a data source have the same value for one or more columns. A common database task is to identify programmatically duplicate rows in a data source. Your final goal for identifying duplicate rows may be to delete all duplicate rows, update one or members of some duplicate sets, or delete all members of some duplicate sets. In the preceding screen shot, rows 3 and 4 as well as rows 8 and 9 comprise two different duplicate sets based on CountryRegionCode and Country Name.
The following script presents a pair of SELECT statements that will eventually be used for identifying and gathering information about duplicate column values in a set of rows.
- The top SELECT statement generates a result set with columns named CountryRegionCode, CurrencyCode, and Currency Name. This query is based on a left join of the Currency table to the CountryRegionCurrency table.
- Some rows in the result set from the top query have more than one Currency value for a single CountryRegionCode. One reason for this is because more than one row from the Currency table matches the same CountryRegionCode in the CountryRegionCurrency table.
- The second SELECT statement generates a list of all the CountryRegionCode values with more than one Currency.
- A derived table (myderivedtable) uses a Windows function to count the currency types partitioned by countryregioncode.
- The outer query includes a WHERE clause that returns only CountryRegionCode values with a count of more than one currency.
-- list country region codes with currency names
SELECT
crc.CountryRegionCode,
crc.CurrencyCode,
cur.name [Currency Name]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency] crc
LEFT JOIN [AdventureWorks2014].[Sales].[Currency] cur
ON crc.currencycode = cur.currencycode
ORDER BY crc.countryregioncode
--------------------------------------------------------------------------------------
-- list country region codes with more than 1 currency code
-- this example illustrates a nested derived table in a where clause
SELECT
CountryRegionCode
FROM
( -- inner query
SELECT DISTINCT
CountryRegionCode,
COUNT(CurrencyCode) OVER (PARTITION BY countryregioncode) [Country Currency Count]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency]
) myderivedtable
WHERE [Country Currency Count] > 1
Here’s a screen shot with some output from both queries.
- The top pane shows an excerpt of the first 15 rows from the initial query. This query returns a separate row for all 109 rows within the CountryRegionCurrency table.
- The second pane shows the 13 CountryRegionCode values for countries that have more than one currency associated with them.
- The overall Results tab has 122 rows: 109 rows from the top query plus 13 rows from the bottom query.

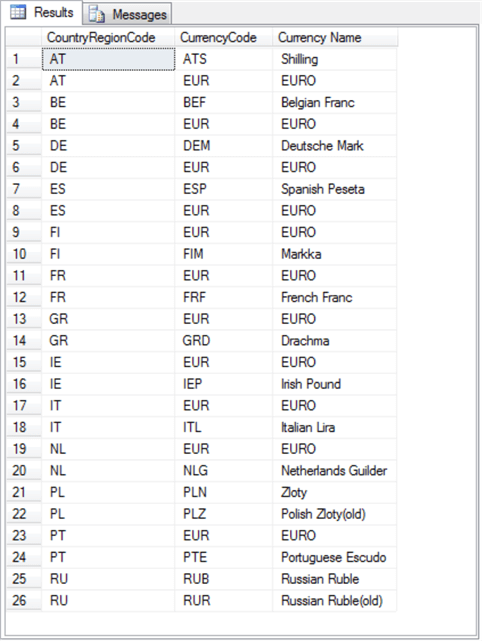
The next query statement combines the preceding two queries to list the CountryRegionCode value, CurrencyCode value, and Currency Name for each CountryRegionCode value that has more than one currency associated with it.
- This outer-most query, which is the first of the preceding pair of queries, returns three columns. These columns have names of CountryRegionCode, CurrencyCode, and Currency Name.
- The outer-most query ends in a WHERE clause; this is a modification to the first of the preceding queries.
- The argument for the WHERE clause is the second query from the preceding pair of SELECT statements. This second query enumerates the CountryRegionCode values that have more than one currency associated with them.
- Therefore, the overall design of the full query is one in which an inner-most query that is based on a derived table is nested inside an outer-most query. The return values from the inner-most query constrain the values returned from the full query.
- Because the outer-most query includes separate columns for CountryRegionCode, CurrencyCode, and Currency Name, the result set from the full query shows all duplicate CountryRegionCode values with their matching currency names that cause the CountryRegionCode values to appear more than once.
-- list country region codes with more than one currency name
SELECT
crc.CountryRegionCode,
crc.CurrencyCode,
cur.name [Currency Name]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency] crc
LEFT JOIN [AdventureWorks2014].[Sales].[Currency] cur
ON crc.currencycode = cur.currencycode
WHERE crc.countryregioncode IN
( SELECT countryregioncode
FROM ( -- inner query
SELECT DISTINCT
countryregioncode,
COUNT(currencycode) OVER (PARTITION BY countryregioncode) [Country Currency Count]
FROM [AdventureWorks2014].[Sales].[CountryRegionCurrency]
) myderivedtable
WHERE [Country Currency Count] > 1
)
The result set from the preceding query appears next. As you can see, there are twenty-six rows in the result set. This is because each of the thirteen duplicate CountryRegionCode values appear with two different currencies. As mentioned above, the first step in deciding how to process duplicate values is to enumerate and review them. The preceding query accomplishes that goal.
Next Steps
Here are some links to resources that you may find useful to help you grow your understanding of content from this section of the tutorial.
- Using Derived Tables to Simplify the SQL Server Query Process
- Inner Joins with Derived Tables
- SQL LEFT JOIN Derived table with INNER JOIN tables in derived table processing performance
- SELECT – OVER Clause (Transact-SQL)

Rick Dobson is a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been a practicing Python developer for more than the past half decade – with a special emphasis for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. If you are interested in growing your skills in any of these areas especially as they relate to financial securities, consider visiting his blog at https://securitytradinganalytics.blogspot.com/2023/12/.
- MSSQLTips Awards: Leadership (200+ tips) – 2025 | Author of the Year Contender – 2017-2024
