By: Siddharth Mehta | Comments (1) | Related: > SQL Server 2017
Problem
Relational databases are found almost in every conceivable business scenario, and SQL is arguably the de-facto standard of accessing data from database systems. With the advent of NoSQL database systems, as well as with some very successful adopters of graph like Google, Facebook, LinkedIn and others, graph has become quite popular and the database community is not that aware and open towards non-relational database management systems. With such a wide adoption of relational databases and a large community of relational database professionals, eventually one would encounter questions like what’s the difference between a relational database and a graph database, when should I consider using a graph database, etc.
In this tip, we will address questions that will help relational database developers understand the various considerations for using a graph database.
Solution
As the complexity in data and value in relationships increases, the ability of relational databases to address the data requirements decreases and use of graph databases increases, which leads to the adoption of graph databases for the right use-cases.
Data exists in various forms from simplest structures and relationships to the very complex forms. At its simplest form, data can be expressed in the form of key-value pairs. Key value databases store data in terms of unique identifiers which are also known as keys, and they have corresponding values. Examples of key values are connection string, session tokens, products in an e-commerce site, etc. Considering a relatively complex form of data with increased relationships, the next logical move from key-value stores goes towards NoSQL data stores.
NoSQL data stores are of various types like document oriented, key-value, columnar, object store, XML store, etc. The data complexity handled by these data stores expands to more complex structures like JSON documents, blob objects, unstructured data, etc. But these data elements are generally not expected to have very strong and rigid relationships. The data elements are self-sufficient and grouped under a common logical space like an index or a database without necessarily having to have a point to point relationship with other data elements.
Once the data complexity increases to complex schemas, stringent constraints on the data as well as transactions, the relationship of one entity with another, and the need to control as well as manage those relationship in a highly controlled manner, relational databases come into picture. Relational databases have been generally seen as the norm of database management unless the use-case requires out-of-the-ordinary characteristics from a database management system for structured data.
A relational database typically stores data in normalized schemas which is formed of a set of normalized as well as de-normalized tables organized typically under databases and schemas. These tables have fixed attributes also known as fields, which have features like data-types, constraints, etc. If the consumers have a rapidly changing need compared to the structure created in the relational databases, it requires a schema or structural change in the database to suit the needs of consumption. Else it would require a high level of overhead to modulate the data from the fixed structure of the relational databases to the needs of consumers.
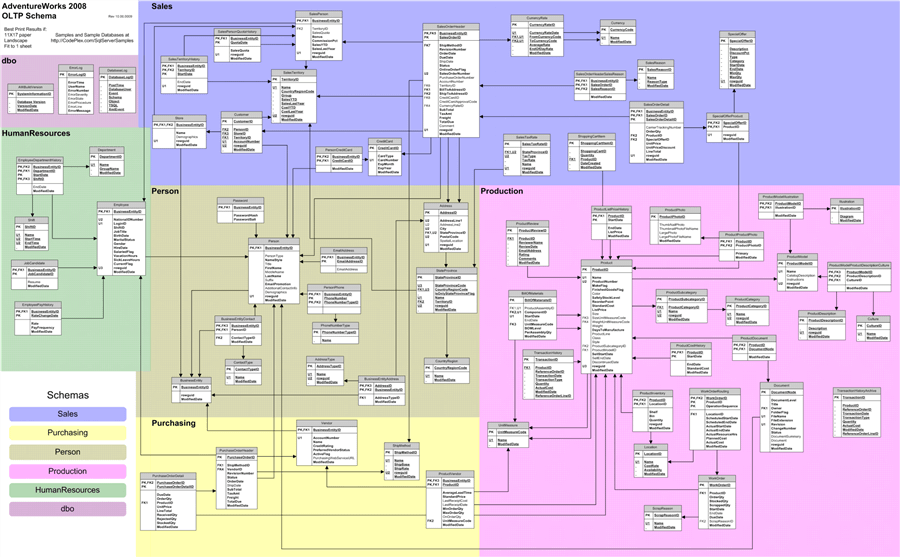
The diagram shown above is a logical database diagram of the Northwind sample database that shows how tables are interconnected with primary and foreign keys. These relationships between normalized tables are evaluated at query time by joining attributes from one or more tables with another which is typically known as table JOINs. These are performance intensive operations, and the larger the scale of the data the harder it becomes to perform these joins to extract the desired data using the right relationships.
Entities can have one-to-one, one-to-many as well as many-to-many relationships. These relationships can be direct between two tables, or indirect as well. For example, a business can have departments, which can have employees. To find employees that belong to a business, either data would have to be joined through departments, or the data would have to be denormalized in a single table, which may cause loss of relationships. The more complex the data grows, the more one would normalize entities in a relational database and the representation of relationships becomes more convoluted.
At this stage, when the complexity or variability of data is extreme and the value or utilization of relationships between entities is of prime importance, graph databases becomes a natural choice. Some of the typical examples of use-cases for graph data models are fraud detection, supply-chain, network related data, etc. One of the most easily understood example of a graph is a social network graph, where people are entities and the associations between them are relationships. A subset of the relationships in the Northwind database can be represented as shown in the below diagram.
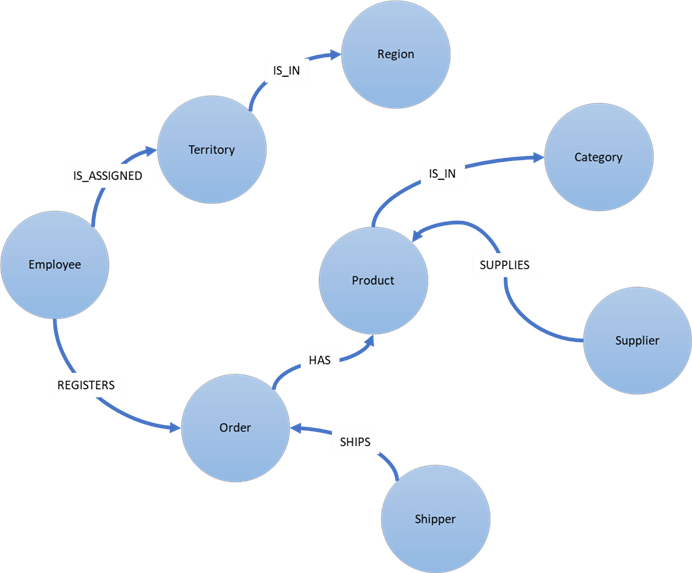
Let us understand the key characteristics of a graph.
- In a graph data model, the conceptual model becomes the actual physical model of the graph. We create entities first and then associate them with relationships, and the data is stored in the same manner unlike relational databases where data is always joined with one or more attributes.
- A graph database does not have any fixed schema, but graph can have directions in the edges, sub-graphs, weight of the edges and other such features that define relationships.
- Relationships are physically stored in the database along with actual data, which makes data retrieval much faster compared to relational databases which evaluate relationships at query time.
- Graph database reduce the amount of data required to derive insights typically in a highly connected data environment, as it does not have fixed data structure limitations like relational databases.
- A graph data model is composed of nodes and edges, where nodes are the entities and edges are relationships between those entities.
- Graph models are basically of two types – Labeled Property Graph and Resource Description Framework (RDF). A Property Graph generally has nodes and edges with unique ids, and internal structures attached to them in the form of key-value pairs. RDFs on the other hand are formed of triples also known as subject-predicate-object, which represent two nodes associated by an edge, without any internal structure.
- Gremlin is typically used to query a property graph, and SPARQL for querying an RDF graph. Cypher is another query language for graph querying.
Microsoft Azure Cosmos DB as well as Microsoft SQL Server both support hosting graph database models. Now that we understand why and when we would start using a graph database, I would highly encourage you to analyze how these databases support graph database models and the mechanism to exploit the maximum potential of these database systems for the right use-cases.
Next Steps
- Consider reading tips like this to start broadening your understanding about graph in SQL Server and staring your journey in the world of Graph Database Systems.






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
