Problem
I am working with a system that doesn’t allow for NULLs in the SQL Server data model. However, I have clear cases where I’m missing information. For instance, I’m dealing with building out our academic system into a new platform and we have columns for final grade in a course as well as several date columns for various reasons. Under our current system, we are allowed to use NULLs, but that’s not allowed in the new system.
How do I handle these types of requirements in this no NULL allowed SQL Server database system?
Solution
The need for NULLs has been argued all the way back to the originator of relational database systems, E.F. Codd, who argued for the inclusion of NULLs. However, if the system you are using doesn’t support NULLs for its data model, here are the two typical options:
- Use default values
- Break up your entities into further entities
There are pros and cons with each of these approaches.
Use Default Values
Let’s take the case of the final grade. If we have a column for the final grade, let’s set a default value of 0. Here’s a paired down example containing only the 3 relevant columns:
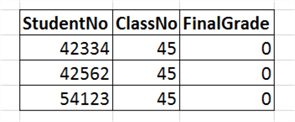
This default value works if there’s a final date when that final grade becomes the actual grade. For instance, most academic institutions have a final date where incomplete grades revert to a final status. Anyone working with the data should be aware of what those dates are because they influence what the data means. Reports will have to take those dates into account.
Pros
The main reason to choose this option is we don’t have to have a lot more tables to create and manage. It simplifies access to the data and being able to bring information together.
Cons
The biggest con is that anything working with the data has to know that there is a default value and handle any calculations accordingly. If there are cases where a default value becomes the permanent value after a certain trigger, like a date, anyone working with the data will need to understand what those triggers are.
For instance, during the exam period, instructors for courses with exams scheduled first should be the ones who are able to put a real value for FinalGrade. However, until the final exam is completed and the professor is able to enter in grades, that 0 is meaningless. Any reports or calculations done during the exam period (and even shortly thereafter) should take into account that some of those final grade values are still default values. There’s probably another table which contains the final exam schedule, or better, when grades must be in. That table is critical if someone is trying to do a calculation before the final exam period ends.
But what if there isn’t a defined period? For instance, what if it’s when a student graduates? Let’s look at that example:
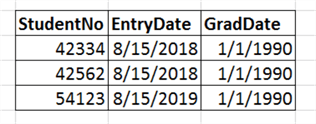
Default values for dates works well when you can put a date that’s obviously not correct. For instance, someone who has entered in 2018 or 2019 can’t possibly have graduated in 1990. We still have the issues with anything using the data and being aware of what has default values and what those values are. For instance, if a report writer is not aware that 1/1/1990 is a default value and then builds a report on graduating classes, all students who haven’t graduated will appear as the Class of 1990, even if the institution didn’t exist in 1990.
One concern with default values for dates is the dates must be before or after what is actually possible. For instance, if the academic institution has existed since 1890, then default dates with 1990 or even 1900 for GradDate will potentially cause a data integrity issue.
Break Up Entities into Further Entities
To avoid using default values, additional tables would have to be generated. Here’s an example involving the final grades again. If we care about seeing a final grade and not having to perform a calculation of all grades each time we need to report on the final grade, we’ll need another table just for final grade. We might look at the data visually like so:
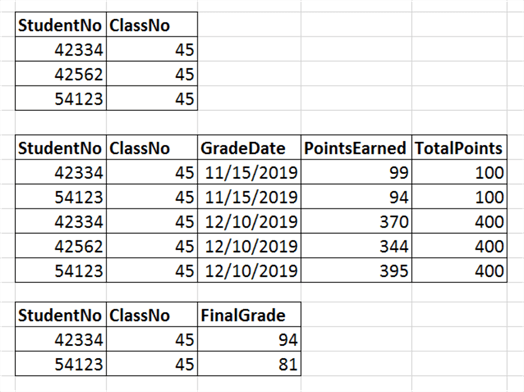
We have three tables from top-to-bottom with only the relevant columns for this example:
- ClassRegistration
- ClassGrade
- ClassFinalGrade
ClassRegistration contains information about student registration for each class. ClassGrade has the information on every grade received for each course. Finally, ClassFinalGrade is where we store the actual final grade value. Since we’re not using default values and we aren’t allowing NULL, if a row that we’d expect to be in the table isn’t there, that means the data is missing.
Note that under ClassRegistration there are 3 students listed. All 3 students have grades in the ClassGrade table but there are only two students listed in ClassFinalGrade. The student identified by StudentNo 42562 doesn’t appear. If we look more closely at ClassGrade, we see that that there was a graded entry for November 15, 2019 but StudentNo 42562 doesn’t have a grade listed. That student has a grade missing. As a result, the professor has not entered a final grade for that student.
Pros
The biggest pro is there is nothing to understand about default values because those aren’t used unless they have some real meaning. For instance, if there is a column in the system to mark whether a student is an undergrad or a graduate student and the institution only offers undergraduate degrees, then a default value marking every student as an undergraduate makes sense.
Since default values are not being used for missing values, there is nothing to pass on with regards to default values to anyone working with the data.
Cons
Everything that could have a missing value has to be broken out in some way. For instance, while we might want a single table to track class registration with a final grade as part of that table, like we did with the default values method, we can’t do this if we want to avoid default values. That’s why there are two separate tables.
Also, anyone working with the data has to understand that if the data isn’t known, there won’t be an entry in the appropriate table. That obviously has an impact if someone is using an [INNER] JOIN but needs to keep information from one or both of the tables on either side of the JOIN.
Next Steps
- If you can use NULLs, be aware of some tricky situations involving NULLs.
- Understand how JOINs work so data isn’t lost when building out more tables to avoid NULL values.

Brian Kelley is an author, columnist, Certified Information Systems Auditor (CISA), and former Microsoft Data Platform (SQL Server) MVP (2009-2016) focusing primarily on SQL Server and Windows security. Brian currently serves as a data architect as well as an independent infrastructure/security architect concentrating on Active Directory, SQL Server, and Windows Server. He has served in a myriad of other positions including senior database administrator, data warehouse architect, web developer, incident response team lead, and project manager. Brian has spoken at 24 Hours of PASS, IT/Dev Connections, SQLConnections, the Techno Security and Forensics Investigation Conference, the IT GRC Forum, SyntaxCon, and at various SQL Saturdays, Code Camps, and user groups.
- MSSQLTips Awards: Author of the Year Contender – 2015, 2017 | Champion (100+ tips) – 2014


