Problem
I am writing SQL Server T-SQL code and I’m not sure if I should use a view, common table expression (CTE), traditional subquery, temp table or table variable to get the best performance. How can I test these options to determine the best performing code?
Solution
This tip will show how to measure the difference in performance of these different TSQL constructs to help figure out the best choice for a given query. The performance tuning methodology shown will work in many other performance tuning scenarios as well! Finally, the tip will provide some thoughts on how to choose which subquery solution to use for a given situation.
All of the demos in this tip will use the WideWorldImporters sample database which can be downloaded from here and will be run against SQL Server 2019. The images might be different, but the methodology should still work on older versions of SQL Server.
Sample Query
A T-SQL developer has been tasked with finding the invoice date and purchase order number for each customer’s largest individual purchase during the first quarter of 2014.
There are 2 steps to calculating this. The first step is to determine which is the largest individual purchase for each customer during the quarter. That can be achieved using this query.
SELECT BillToCustomerID, MAX(ExtendedPrice) Amt FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014' GROUP BY BillToCustomerID;
It’s not as simple as choosing the MAX() invoice date or purchase order as the resulting value may or may not be from the same invoice as the MAX(ExtendedPrice). Those 2 columns can’t be added to the GROUP BY clause as there would likely be more than one row per customer. This can be accomplished with a subquery.
Once that calculation has been made, the 2 resulting columns must be joined back to the invoice tables to determine the invoice date and customer purchase order number of the invoice that contains the largest purchase.
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID INNER JOIN THAT_QUERY_FROM_ABOVE t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice
It is at this point that the decision must be made to use a CTE, traditional subquery, view, or temporary table to accomplish the final query.
Comparing the CTE option to a traditional subquery
The 2 versions of the queries are below. They will be executed with both STATISTICS IO and Include Actual Execution Plans on.
--CTE Version WITH TopPurchase AS( SELECT BillToCustomerID, MAX(ExtendedPrice) Amt FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014' GROUP BY BillToCustomerID) SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID INNER JOIN TopPurchase t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice --Subquery Version SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID INNER JOIN( SELECT BillToCustomerID, MAX(ExtendedPrice) Amt FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014' GROUP BY BillToCustomerID) t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice
The first output to be analyzed will be the execution plans where there are 2 queries shown. Each one is estimated to take 50% (yellow highlight) of the workload for the entire batch. These percentages are based on estimates and won’t always be accurate. There isn’t room on the screen to show the entirety of the query plans, but this screenshot snippet shows several matching operators between the 2 plans. A more thorough examination would confirm that they match exactly.
This suggests that there is no performance difference between the 2 versions of the query.
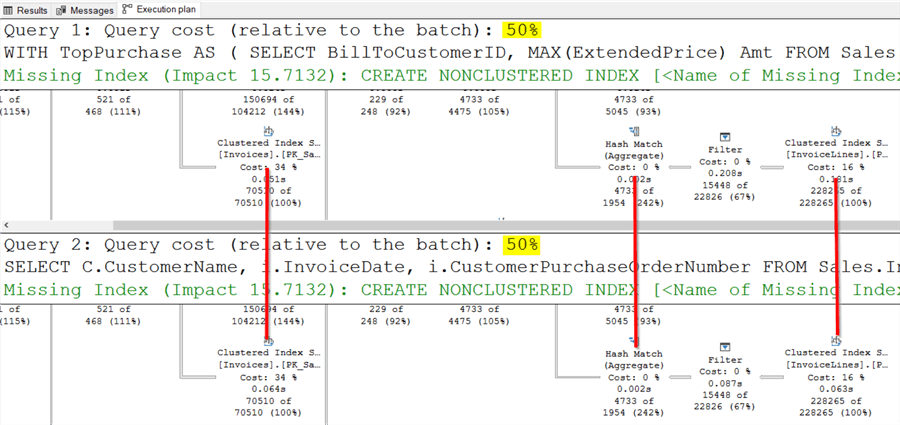
Moving on to the Messages tab. It shows the output of STATISTICS IO and row counts of the query executions. This output shows that both queries returned 521 rows (in red). The text that says “1 row affected line” is for the execution plans.
The other 3 lines in yellow, green, and purple show that both versions queried the same tables for the same amount of data. The information on this tab confirms that there is no performance difference between these queries and likely means that the 50% estimates from the execution plan tab is accurate.

Using a view instead of a CTE or traditional Subquery
The next version of the query will be created using a view to build the first query. This is the view definition.
CREATE VIEW vTopPurchase AS SELECT BillToCustomerID, MAX(ExtendedPrice) Amt FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014' GROUP BY BillToCustomerID;
The new query:
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID INNER JOIN vTopPurchase t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice
Executing this query returns the same row counts and exact same IO statistics as the first 2 versions of the query. An examination of the query plan shows the identical plan again!
What does this mean?
The SQL Server engine optimizes every query that is given to it. When it encounters a CTE, traditional subquery, or view, it sees them all the same way and optimizes them the same way. This involves looking at the underlying tables, considering their statistics, and choosing the best way to proceed. In most cases they will return the same plan and therefore perform exactly the same.
Temporary Tables
Another option for such a query is to use a temporary table to store the intermediate results before joining in the temporary table in the final select. The use of temporary tables will always yield different query plans which may be faster or slower, depending on the queries involved. There are 2 methods to implement temporary tables. They are the table variable and TempDB temporary table.
Using a TempDB temporary table
This option involves creating a table in tempdb using CREATE TABLE #NAME. The table will be created in TempDB and then populated. It is that table that will be joined in the second query.
CREATE TABLE #TopPurchase(BillToCustomerID INT, Amt DECIMAL(18,2)) INSERT INTO #TopPurchase(BillToCustomerID, Amt) SELECT BillToCustomerID, MAX(ExtendedPrice) Amt FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014' GROUP BY BillToCustomerID SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID INNER JOIN #TopPurchase t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice
Looking at the IO statistics for this query show 2 different queries. The first set of results is for the population of the temporary table and the second is for the SELECT statement.

To compare this output to the prior executions the values will need to be added together. Adding them together results in 23,394 reads against Invoices, 10,259 reads against InvoiceLines, and 40 against Customers. This is very similar, but slightly higher than the single-query versions.
The way these 2 queries are optimized is very similar to the queries above. For the query that inserted rows into the temporary table, the optimizer looked at the table statistics and chose the best way forward. It actually made new table statistics for the temporary table and then used them to run the second. This brings about very similar performance.
Utilizing a table variable
This option involves creating a table in tempdb using DECLARE @NAME TABLE. SQL Server will attempt to store this table in memory.
DECLARE @TopPurchase TABLE(BillToCustomerID INT, Amt DECIMAL(18,2)) INSERT INTO @TopPurchase(BillToCustomerID, Amt) SELECT BillToCustomerID, MAX(ExtendedPrice) Amt FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014' GROUP BY BillToCustomerID SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID INNER JOIN @TopPurchase t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice
Running this version of the query returns these shocking IO statistics.
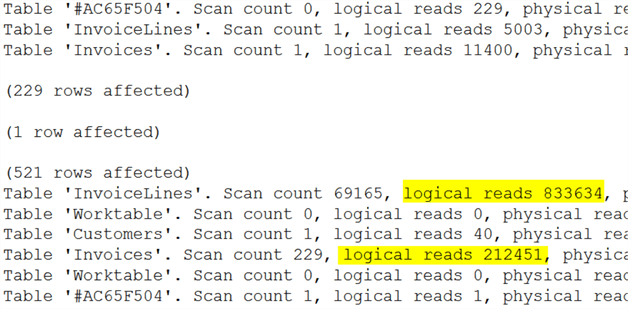
The insert query runs very similarly to the TempDB table version, but the select statement uses many, many more resources. This is because the first query can run the same way in both instances, but the table variable does not have any table statistics generated for it like the TempDB table did. This means the optimizer has to make a wild guess as to how to proceed. In this example it made a very, very poor decision.
This is not to write off table variables. They surely have their place as will be discussed later in the tip.
What happens with missing (or bad) table statistics?
This tip mentioned at the top that sometimes the query cost estimate percentages of the execution plan aren’t accurate. Consider a query batch that calls one of the 3 queries from the top half of this tip (which all performed identically) and then calls the pair from the table variable version for 3 total queries executed. From the data above it would be expected that the 3rd query would account for most of the cost as the first query completes about 33,000 reads, the second about 16,000, and the 3rd well over 1,000,000.
The screenshot below tells a very different story. It is right to estimate that the second query was about half the effort of the first, but it is not even close to suggest that the 3rd query was only 2% of the overall effort.
Knowing this, it is important to consider other factors (like IO statistics) and not rely solely on these cost estimates when looking to performance tune a query.

How to choose?
Seeing that the performance is rarely going to be a factor when choosing between a CTE, subquery, or view, how can one decide which option to use? When is it appropriate to use a temporary table or table variable?
There are a lot of personal choices and style decisions that dictate which method to use, but there are some definite differences between the choices that can help guide a T-SQL developer to a solution.
This author rarely uses traditional subqueries as they are hard to read and don’t offer any of the special features that the other methods can. They are only preferred for a very small subquery that can be typed in a single line of T-SQL code.
CTEs are a popular choice because unlike traditional subqueries they can be organized at the top of a query making the final query easy to read. They can also be nested such that any CTE starting with the second CTE can reference any previous CTE for a query. A CTE can even reference itself!
Views are useful when the query is likely to be reused. It is much easier to share that logic between queries when it is saved as its own object within the database.
Temporary tables and table variables are useful when the intermediate results are going to be needed more than once within the same batch. It often makes sense to store those values rather than repeatedly calculate them.
Choosing between a TempDB temporary table and table variable is pretty straightforward. A temporary table will be stored on disk and have statistics calculated on it and a table variable will not. Because of this difference temporary tables are best when the expected row count is >100 and the table variable for smaller expected row counts where the lack of statistics will be less likely to lead to a bad query plan.
Next Steps
- Check out these related tips:

Eric has been a SQL Server DBA and Architect in the legal, software, transportation, and insurance industries for over 10 years. Currently he is the Sr Data Architect for Squire Patton Boggs, a leading provider of legal services with 47 offices in 20 countries.
Eric is a 2018-2019 Idera Ace and has co-authored 2 Idera Whitepapers.
He has been a presenter at PASS Summit, IT/DevConnections, SQLSaturdays, the in.sight transportation conference, and the Ohio North SQL Server User’s Group.
- MSSQLTips Awards: Author of the Year Contender – 2021, 2022 | Trendsetter (25+ tips) – 2021


