Problem
We have a large number of data files stored in Amazon S3 that we would like to import into an RDS SQL Server database. We know we can use ETL tools for this, but is there any way to import this data without ETL?
Solution
Amazon Web Service (AWS) recently announced a new feature of its Relational Database Service (RDS) for SQL Server. This feature allows a native integration between Amazon RDS SQL Server and Amazon S3. With this integration, it’s now possible to import files from an Amazon S3 bucket into a local folder of the RDS instance. Similarly, files from that folder can be exported to S3. The RDS local folder path is D:\S3\.
This integration is a great way to import data into RDS SQL Server databases without using an ETL tool. S3 data files downloaded to the local drive can be easily ingested using the BULK INSERT command.
Test Scenario
In this article, we will see how to prepare an RDS SQL Server for native S3 integration. Although the feature is available for both single-AZ and multi-AZ scenarios, we will use a single-AZ RDS instance. We will copy some sample data files from an S3 bucket to the RDS instance and then ingest that data into a database.
Source Data
The data files for the examples in this article are from the City of Los Angeles Open Data Portal. There are many publicly available datasets on this site, some of which are from the Los Angeles Police Department (LAPD). One such dataset is the yearly LAPD Calls for Service. These datasets contain anonymized details of service requests made to the LAPD each year. The files are in CSV format and have header rows.
The image below shows a sample of the data:
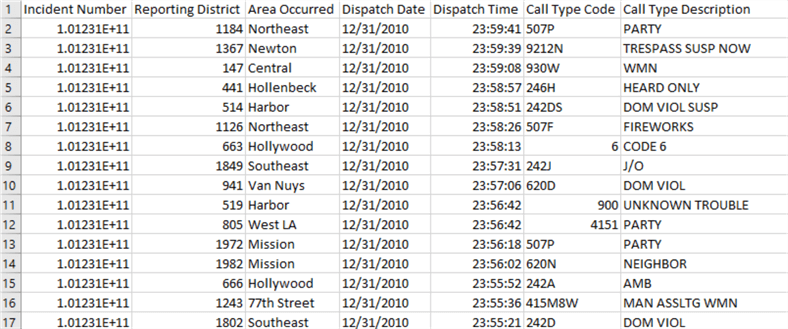
As you can see, there are seven columns in each dataset which are more-or-less self-explanatory:
- Incident Number – Unique number that identifies the call
- Reporting District – Numerical representation of the place where the call originated from
- Area Occurred – Place where the incident is reported to have occurred
- Dispatch Date – Date the call was dispatched to an officer of the LAPD
- Dispatch Time – Time the call was dispatched to an officer of the LAPD
- Call Type Code – Alphanumeric code for the service request type
- Call Type Description – Short description of the service request type
S3 Source Location
We have copied the files under a folder called “data” in an S3 bucket:
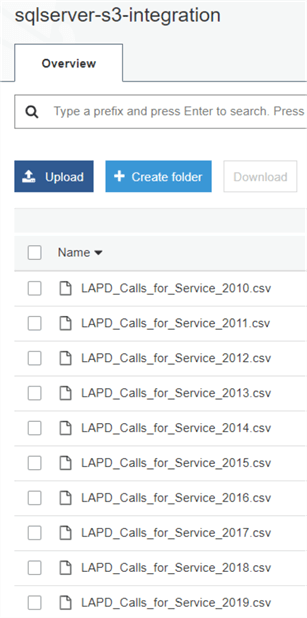
Notice how the files follow a naming style. Each file has a prefix “LAPD_Calls_for_Service_”, followed by the year. Every file has an .csv extension. Here, we have files between 2010 and 2019. We will use these naming style in a script later.
RDS SQL Server Instance
We created a single-AZ RDS SQL Server 2017 instance in the same region as the S3 bucket (us-east-1, North Virginia):
Destination Database and Table
We created a database called “s3_integration“, and also created a table called “lapd_service_calls” in it. The table’s fields represent the source file columns.
-- Create destination database CREATE DATABASE [s3_integration] CONTAINMENT = NONE ON PRIMARY ( NAME = N's3_integration', FILENAME = N'D:\rdsdbdata\DATA\s3_integration.mdf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) LOG ON ( NAME = N's3_integration_log', FILENAME = N'D:\rdsdbdata\DATA\s3_integration_log.ldf' , SIZE = 25600KB , FILEGROWTH = 32768KB ) GO USE s3_integration GO -- Create destination table CREATE TABLE lapd_service_calls ( incident_number varchar(20) NOT NULL, reporting_district varchar(20) NOT NULL, area_occurred varchar(20) NOT NULL, dispatch_date varchar(30) NOT NULL, dispatch_time varchar(20) NOT NULL, call_type_code varchar(20) NOT NULL, call_type_description varchar(30) NULL ) GO
Although some of the fields in the source data are numeric (Incident Number) or date (Dispatch Date) type, we are specifying each field as varchar to keep the loading process simple.
Configuring S3 Integration
We will now configure the RDS instance for S3 integration.
Step 1: Creating IAM Policy and Role
The first step for RDS SQL Server integration to S3 is to create an IAM role with access to the source S3 bucket and folders. In the images below, we are creating an IAM policy with necessary access privileges:
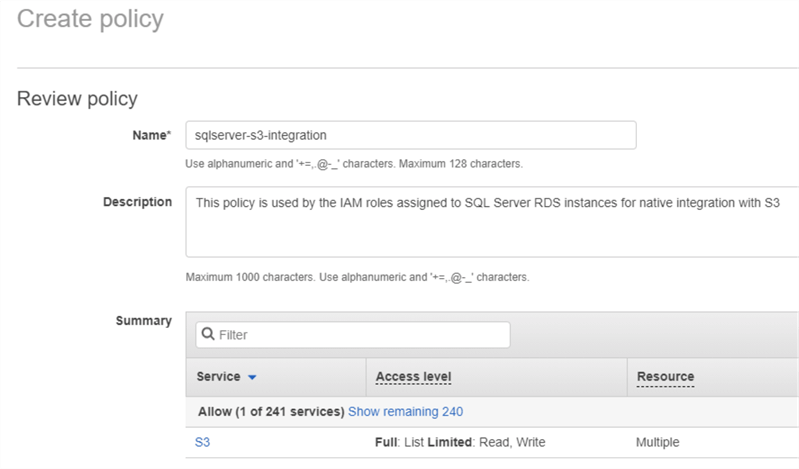
We are calling this policy “sqlserver-s3-integration“. Next, we are assigning S3 permissions to the policy:
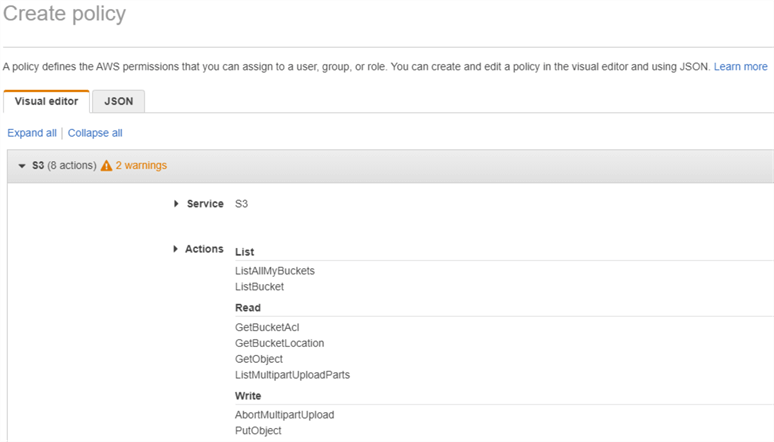
Finally, we are specifying the S3 resource on which these permissions will apply. In this case, we are providing the ARN (Amazon Resource Name) of the source S3 bucket. Note how we are selecting the option to include all objects (including folders) under this bucket:
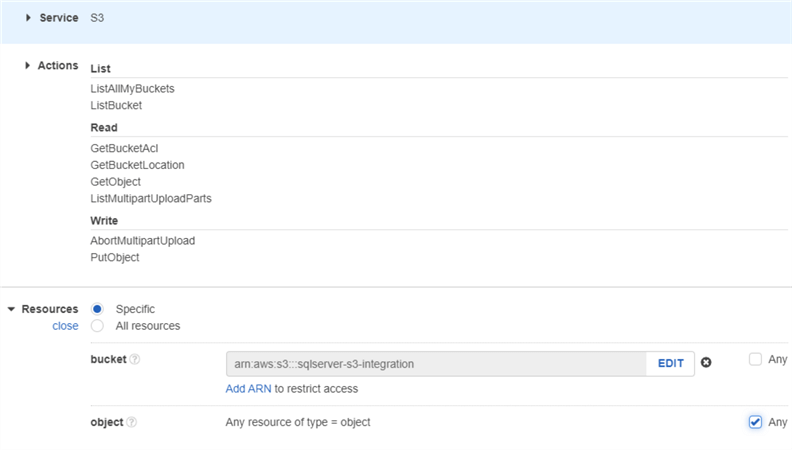
Once the policy is created, we have to assign it to an AIM role. In the images below, we are creating an IAM role with the same name as the policy, and assigning the policy to it:
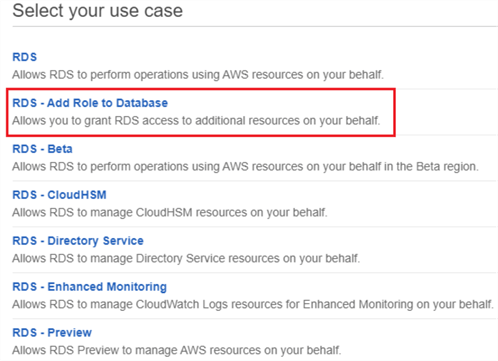
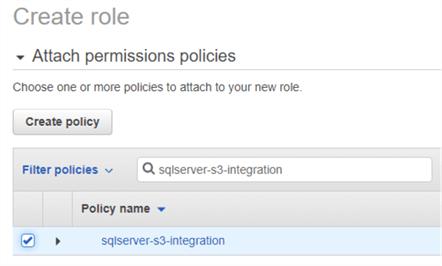
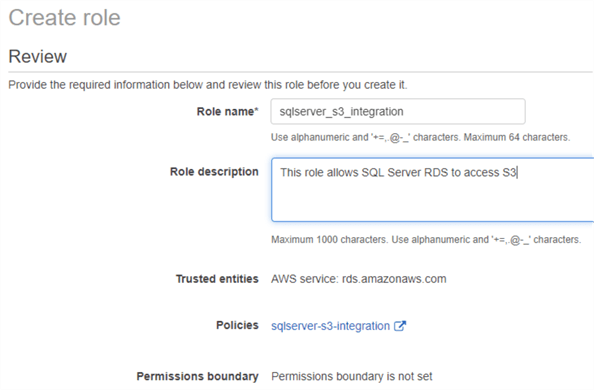
Step 2: Add IAM Role to RDS SQL Server Instance
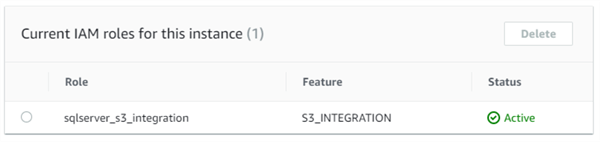
The next step is to attach the IAM role to the RDS instance. This can be done from the “Connectivity and security” tab of the RDS instance’s property. Under the “Manage IAM roles” section, we can select the role just created and then select “S3_INTEGRATION” from the “features” drop-down list:
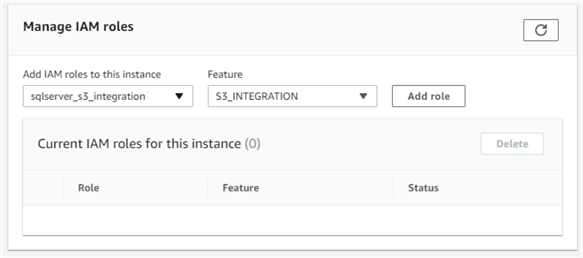
Once the change takes effect, the role has “Active” status:
Importing Data from S3
Importing the data from S3 into a database table involves two steps:
- Download the S3 files to a local folder (D:\S3\) in RDS
- Use the BULK INSERT command to import the local data files into the table
Step 1: Download S3 Files
Amazon RDS for SQL Server comes with several custom stored procedures and functions. These are located in the msdb database. The stored procedure to download files from S3 is “rds_download_from_s3“. The syntax for this stored procedure is shown here:
exec msdb.dbo.rds_download_from_s3 @s3_arn_of_file='arn:aws:s3:::<bucket_name>/<file_name>', @rds_file_path='D:\S3\<custom_folder_name>\<file_name>', @overwrite_file=1;
The first parameter specifies the ARN of an S3 file.
The second parameter sets the destination path in the RDS instance. The root path is D:\S3\, but we can specify a custom folder name under it. The folder will be created if it doesn’t already exist.
The third parameter is a flag. It indicates if an already downloaded source file will be deleted when the procedure runs again.
Please note that you cannot specify wildcards to copy multiple files. The function expects individual file names.
Instead of running this command multiple times, we are using a small script to automate the process:
declare @year_start smallint declare @year_end smallint declare @filename_prefix varchar(50) declare @filename varchar(50) declare @filename_suffix varchar(10) declare @s3path_root varchar(200) declare @s3path varchar(200) declare @local_path_root varchar(20) declare @local_path varchar(300) declare @sql nvarchar(1000) set @year_start=2010 set @year_end=2019 set @filename_prefix = 'LAPD_Calls_for_Service_' set @filename_suffix = '.csv' set @s3path_root = 'arn:aws:s3:::sqlserver-s3-integration/data/' set @local_path_root = 'D:\S3\source_data\' -- Loop through the file names and dynamically build a query to import the files while (@year_start <= @year_end) begin set @filename = @filename_prefix + convert(varchar(4), @year_start) + @filename_suffix set @s3path = @s3path_root + @filename set @sql = 'exec msdb.dbo.rds_download_from_s3 ' set @sql = @sql + '@s3_arn_of_file=' + '''' + @s3path + ''', ' set @sql = @sql + '@rds_file_path=' + '''' + @local_path_root + @filename + ''', ' set @sql = @sql + '@overwrite_file=1;' exec(@sql) set @year_start = @year_start +1 end
This script loops through the numbers 2010 and 2019, and dynamically builds each source filename within each loop. As we saw before, the source files have a common naming pattern, which makes this process easy. A dynamic SQL command is then generated with the file name to call the rds_download_from_s3 stored procedure. Note how we are using a custom folder (“source_data”) to save our files.
With each iteration, a download task is added to a queue for the RDS instance. RDS for SQL Server processes the tasks in this queue sequentially. At any time, there can be two tasks running simultaneously.
Once the script finishes running, we can run another stored procedure to list the files copied to the local folder. This stored procedure is called “rds_gather_file_details“. Running the stored procedure also adds a task at the end of the queue:
exec msdb.dbo.rds_gather_file_details;
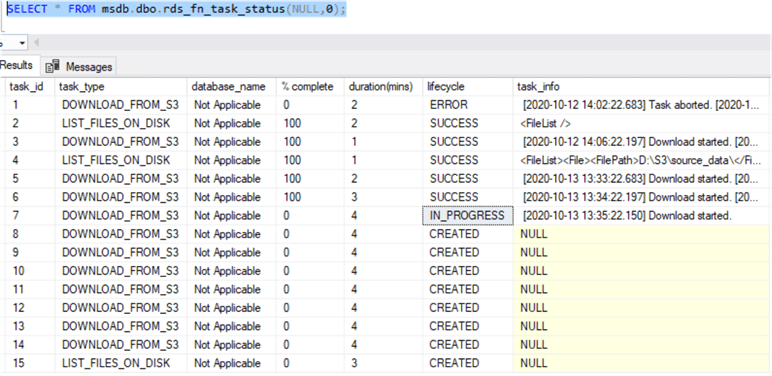
We can check the status of all the queued tasks by running the “rds_fn_task_status” function:
SELECT * FROM msdb.dbo.rds_fn_task_status(NULL,0);
The first parameter value is always NULL. The second parameter is the task ID. In this case, we want to know the status of all tasks, so we specify 0.
The image below shows the various task status. Note how some download tasks have succeeded, one is in progress, and some are yet to run. Also, the last task (“LIST_FILES_ON_DISK“) was added when we ran the “rds_gather_file_details” stored procedure. This task has an ID of 15.
When all files are successfully downloaded, and the “LIST_FILES_ON_DISK” task is also completed, we can run another function to see the list of locally downloaded files:
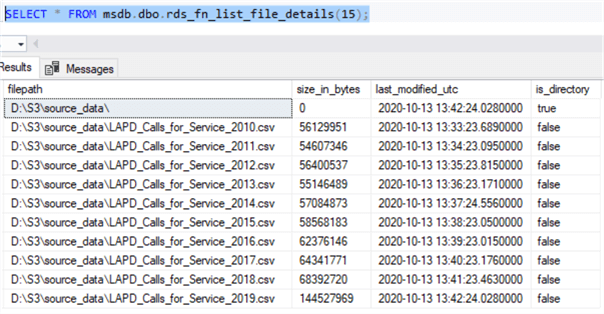
SELECT * FROM msdb.dbo.rds_fn_list_file_details(15);
The “rds_fn_list_file_details” function’s parameter value is the task ID of the “LIST_FILES_ON_DISK“ task. In this case, it was 15. The image below shows the result:
Step 2: BULK INSERT the Data
We can run a series of BULK INSERT commands to load the data into the table we created. The code snippet below shows the load process:
declare @year_start smallint declare @year_end smallint declare @local_filename_prefix varchar(50) declare @local_filename_suffix varchar(10) declare @local_filename varchar(100) declare @tablename sysname declare @sql nvarchar(1000) set @year_start=2010 set @year_end=2019 set @local_filename_prefix = 'D:\S3\source_data\LAPD_Calls_for_Service_' set @local_filename_suffix = '.csv' set @tablename = 's3_integration.dbo.lapd_service_calls' while (@year_start <= @year_end) begin set @local_filename = @local_filename_prefix + convert(varchar(4), @year_start) + @local_filename_suffix set @sql = 'BULK INSERT ' + @tablename + ' FROM ''' + @local_filename + ''' WITH (DATAFILETYPE = ''char'', FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''0x0a'')' exec(@sql) set @year_start = @year_start +1 end
Once again, we are using the year as a variable and looping through the values between 2010 and 2019 to build a dynamic SQL command. Once all the files are loaded, the output looks like this:

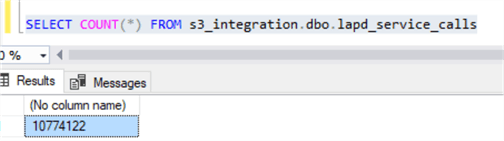
We can now run a query to see the total number of rows loaded:
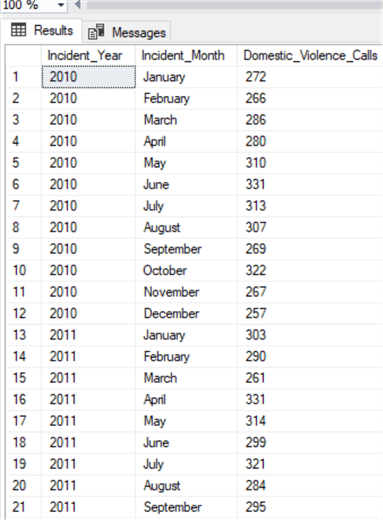
We can also run some analysis on the loaded data. In the code snippet below, we are finding the total number of calls made to LAPD every month about possible occurrences of domestic violence in the Hollywood neighborhood.
SELECT RIGHT(dispatch_date, 4) AS Incident_Year, CASE LEFT(dispatch_date,2) WHEN '01' THEN 'January' WHEN '02' THEN 'February' WHEN '03' THEN 'March' WHEN '04' THEN 'April' WHEN '05' THEN 'May' WHEN '06' THEN 'June' WHEN '07' THEN 'July' WHEN '08' THEN 'August' WHEN '09' THEN 'September' WHEN '10' THEN 'October' WHEN '11' THEN 'November' WHEN '12' THEN 'December' ELSE 'Unknown' END AS Incident_Month, COUNT(*) AS Domestic_Violence_Calls FROM s3_integration.dbo.lapd_service_calls WHERE area_occurred LIKE '%Hollywood%' AND call_type_description LIKE '%DOM%' GROUP BY RIGHT(dispatch_date, 4), LEFT(dispatch_date,2) ORDER BY RIGHT(dispatch_date, 4), LEFT(dispatch_date,2);
The results may show some interesting trends:
A Few Points to Remember
There are some limitations to RDS’ integration with S3.
First of all, both the RDS instance and the S3 bucket has to be in the same AWS region. Cross-region integration isn’t supported at the time of writing (2020). Similarly, the IAM role owner and the S3 bucket owner has to be the same IAM user. In other words, the S3 bucket cannot be in another AWS account.
Secondly, only files without any extension or files with the following extensions are supported:
- *.bcp
- *.csv
- *.dat
- *.fmt
- *.info
- *.lst
- *.tbl
- *.txt
- *.xml
Third, the maximum number of files allowed for local download is 100. But this can be overcome by removing the files once they are imported into a database.
Fourth, the maximum file size allowed for download is 50 GB.
Fifth, the S3 integration feature isn’t automatically enabled in a restored RDS instance. It has to be reconfigured once an instance snapshot is restored.
Sixth, the files in the D:\S3 folder are lost when an RDS instance fails over to its standby replica node in a multi-AZ setup. The S3 integration needs to be reenabled in the new node.
Other Functionality
There are other RDS-specific stored procedures for S3 integration:
- rds_delete_from_filesystem is used to delete files from the RDS local folder
- rds_cancel_task is used to cancel a task from the queue
- rds_upload_to_s3 is used to upload files from the RDS instance to S3
Next Steps
This article showed how to use RDS SQL Server’s S3 integration feature. Readers are encouraged to refer to AWS documentation for more details. Also, it will be worthwhile to build an ETL framework based on this feature and develop
- Data output stored procedures to upload query results from RDS to S3
- Data loading stored procedures that can run from SQL Agent jobs
- Data cleaning stored procedures to regularly clean-up downloaded and ingested files. This stored procedure can use a status table to keep track of files already migrated
- A self-healing mechanism for failover in a multi-AZ scenario. With this feature, the RDS SQL Server instance will run a stored procedure to check the existence of a specific folder or file under D:\S3. If the file or folder doesn’t exist or the process fails, it will mean a failover has happened, and the new node isn’t configured for S3 integration. The procedure can then record a message in SQL Server log.

Sadequl Hussain lives in Sydney, Australia and holds a Bachelor’s degree in Electrical Engineering. His more than 15 years’ experience in IT has seen him in various roles including training, technical writing, web application development and database administration. Sadequl has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical database systems for various large companies. He is also an Oracle DBA and an avid Linux administrator. Over the years Sadequl has achieved various certifications including those from Microsoft, CompTIA and ITIL. He is currently having fun preparing for other ones from Amazon and the Open Group. He regularly contributes to various SQL Server and Linux online publications. Apart from spending time with his wife and daughter, he loves his part-time career as a photographer and film-maker and also loves to travel.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2017



Great article, helped me greatly ….
Hi. Is there a version of this for MySQL databases? I need to do the same process for this DB engine.
Hi Yashpal,
The reason it takes a while for files to load from S3 to RDS using SSIS is because of the location of the source files. Unlike the traditional on-premise SQL Server/SSIS scenario, S3 files are accessed over the Internet and the RDS instance may not be in the same virtual server that the S3 storage layer’s network is serving.
You can use other AWS services for the initial loading such as data pipeline, Kinesis, and so on. With these technologies, the error trapping is automatic.
Hi Ian,
Sorry for the very late reply. Well, this is one way of loading data into an RDS SQL Server, and it’s certainly cheaper than using a dedicated ETL platform. But bear in mind that in most cases, loading data as-is from source files is only the start of an ETL process. In most cases, you would want to do some data validation, cleansing, transforming before loading the data. In such cases you have to use other ETL methods.
Thanks for sharing great article.
Question: How long does it takes to download/transfer the files from S3 to RDS ?
In one of the application I’m working right now is, enabling SSIS on RDS. First step is to load the corresponding CSV file from S3 to RDS (D:\S3) so SSIS enabled on RDS can pick-up those files at the time of execution.
Issue is, it takes around 5 to 7 mins to load the files from S3 to RDS and that too we need to keep checking the progress on copy task, is complete or not. Is there any way we can expedite the file transfer from S3 to RDS or in your case how long does it take?
The file size I use is very small in bytes with .csv extension.