Problem
We want to leverage Always On Availability Groups to offload our reporting and analytics workloads from the primary replica to the other secondary replicas. We have an existing 2-replica Always On Availability Group that we configured for disaster recovery using Read-Scale Availability Groups. How can we leverage our existing Read-Scale Availability Groups that we use for disaster recovery to offload our reporting and analytics workloads?
Solution
In a previous tip on Step-by-step Configuration of Read-Scale Always On Availability Group for Disaster Recovery we’ve seen how you can leverage read-scale Availability Groups as a disaster recovery strategy. Because the goal is disaster recovery, no cluster resource manager like a Windows Server Failover Cluster (WSFC) is configured. The architecture diagram for configuring read-scale Availability Groups as a disaster recovery strategy is shown below.

If you want to leverage your existing read-scale Availability Groups for reporting and analytics workloads, you need to add another replica in the same location as your primary replica. It doesn’t make sense to have your reporting and analytical applications in your production data center while your data source is in the disaster recovery data center. Both your applications and the data source need to be in the same data center to eliminate application performance caused by latency due to network roundtrips. The architecture diagram for configuring read-scale Availability Groups as a disaster recovery strategy and offloading reporting and analytics workloads is shown below.

In the example diagram, three SQL Server instances will be used for the read-scale Availability Group. The primary replica (TDPRD031) is in the production data center together with a secondary replica (TDPRD032) that will be used to offload reporting and analytical workloads. Another secondary replica (TDDR031) is in the disaster recovery data center configured in asynchronous replication mode.
To configure a read-scale Availability Group for offloading reporting and analytical workloads,
Step #1: Add another replica in the existing Availability Group
To add another replica to an existing read-scale Availability Groups,
Enable the SQL Server Always On Availability Groups feature on the new SQL Server instance
- Open SQL Server Configuration Manager.
- Select SQL Server Services, double-click the SQL Server (MSSQLSERVER) service to open the Properties dialog box.
- Click the Always On Availability Groups tab and check the Enable Always On Availability Groups checkbox and click OK. This will prompt you to restart the SQL Server service.

- Open SQL Server Management Studio. From within Object Explorer, expand the Always On High Availability node, the Availability Groups node, and, then the name of your read-scale Availability Group.
- Right-click the Availability Replicas and select Add Replica. This opens the Add Replica to Availability Group dialog box.

- In the Connect to Existing Secondary Replicas dialog box, click the Connect … button. This will prompt you to provide the credentials to connect to the existing replica. Click Connect. Then, click Next.

- In the Specify Replicas dialog box,
- In the Replicas tab, click the Add Replica button to add the SQL Server instance that you want to configure as a new replica. Since this will be used for offloading reporting and analytical workloads and not for high availability, the Availability Mode is set to Asynchronous commit. Do not configure the Readable Secondary column just yet. This is just to add another replica to the read-scale Availability Group.

- In the Endpoints tab, review the Availability Group endpoints and make sure that the replicas can communicate with each other via the endpoints.

NOTE: Do not configure the Availability Group listener just yet. This will be done in the section Step #2: Configure an Always On Availability Groups Listener Name.
- In the Select Initial Data Synchronization dialog box, you can choose to either use the Automatic Seeding feature, the usual Full database and log backup option, Join only option, or Skip the initial data synchronization option. This example uses Automatic Seeding since the databases are relatively small. Refer to this tip for more information about Automatic Seeding. Click Next.

- In the Validation dialog box, make sure that all checks return successful results. Ignore the warning regarding the listener configuration. Click Next.

- In the Summary dialog box, verify that all the configuration settings are correct. Click Finish to add another replica to the read-scale Availability Group.

- Click Close after the wizard completes.

Make sure that the replicas and databases are healthy before proceeding to the next step.

It can be tempting to configure the Availability Group listener name and the Readable Secondary option when you’re adding another Availability Group replica. Avoid the temptation to do so. The more complex an architecture is, the more confusing it will be to troubleshoot an issue, in case you experience one. A good change management practice is to introduce one change at a time, making sure that the change is working properly before introducing another one. This is especially true when what you are changing is already deployed in production. In this example, make sure that the read-scale Availability Group is properly configured before moving on to the next change.
Step #2: Configure an Always On Availability Groups Listener Name
In a high availability configuration, the Availability Group listener name automatically redirects client applications to the primary replica upon failover. That’s because a cluster resource manager like WSFC takes care of automatic failover of the Availability Group together with the listener name. Client applications connecting to the listener name will always be redirected to whichever SQL Server instance is running as the primary replica.
The Availability Group listener name gets created as a client access point/network name resource in the WSFC. The client access point/network name resource is a floating virtual network name with a corresponding virtual IP address that moves with the Availability Group. Also, the WSFC creates the corresponding virtual computer object in Active Directory as well as the equivalent DNS record.
Since this is not a high availability configuration, there is no point in having an Availability Group listener name. If the primary replica becomes unavailable, you need to manually failover the Availability Group to any of the available secondary replicas. This also means manually redirecting client applications to the new primary replica.
However, an Availability Group listener name is required in order to offload reporting and analytical workloads using read-only routing. The Availability Group listener name created for a read-scale Availability Groups is unlike the one used for high availability. In a read-scale Availability Group, the Availability Group listener name will use the IP address and port number of the current primary replica instead of a virtual IP address.
- Open SQL Server Management Studio. From within Object Explorer, expand the Always On High Availability node, the Availability Groups node, and, then the name of your read-scale Availability Group.
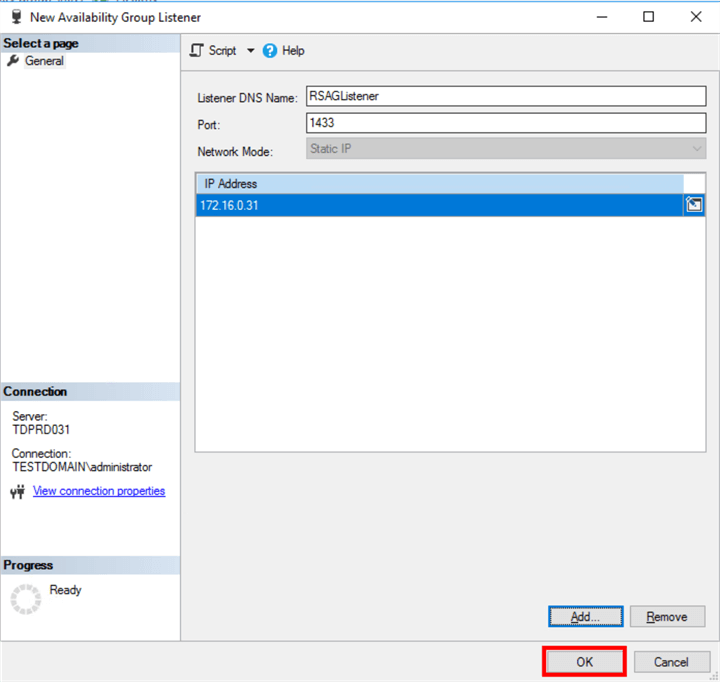
- Right-click the Availability Group Listeners and select Add Listener... This opens the New Availability Group Listener dialog box.

- In the Listener DNS Name: field, provide the network name you want to use to access the Availability Group.
- In the Port: field, provide the port number of the SQL Server instance running as a primary replica.
- Click the Add button.

- In the Add IP Address dialog box, provide the IP address and the subnet mask of the primary replica. Click Oakton close the dialog box.

- Click OK to create the Availability Group listener name.
While the Availability Group listener name has been created, it only exists in the context of the primary replica. No client application will be able to connect to the read-scale Availability Group unless they can find it on the network. This is unlike an Availability Group running in a WSFC where a corresponding DNS record is automatically created for you via Active Directory-integrated DNS zones. In order to do so, you (or your DNS server administrator) would need to create a corresponding record on your DNS to point to the primary replica.
Step #3: Configure a DNS alias to point to the Always On Availability Groups Listener Name
This step needs to be done by an administrator who has permissions to create records on your DNS server. The screenshot below shows how the Availability Group listener name is associated with the SQL Server instance running as primary replica using a DNS alias on a Microsoft DNS server.


Run a simple ping test to validate if the DNS alias properly resolves to the hostname of the primary replica.

Step #4: Enable Readable Secondary in the Read-Scale Always On Availability Groups Replicas
Now that the infrastructure is ready, proceed to configure readable secondary on the replicas in the read-scale Availability Groups. Before you do, make sure you have the appropriate SQL Server license for every readable secondary replica in your read-scale Availability Group.
- Open SQL Server Management Studio. From within Object Explorer, expand the Always On High Availability node, the Availability Groups node, and, then the name of your read-scale Availability Group.
- Right-click the read-scale Availability Group and select Properties.

- In the General tab, under the Readable Secondary column, select Read-intent only for all replicas in the production data center. Click OK.

Alternatively, you can use the T-SQL script below to set the Readable Secondary property of the replicas in the production data center to read-intent only.
USE [master] GO ALTER AVAILABILITY GROUP [ReadScale-AG] MODIFY REPLICA ON N'TDPRD031' WITH(SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY)) GO USE [master] GO ALTER AVAILABILITY GROUP [ReadScale-AG] MODIFY REPLICA ON N'TDPRD032' WITH(SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY)) GO
If you’re wondering why only the replicas in the production data center are configured, that’s because you want to prevent reporting and analytics applications from connecting to the disaster recovery data center when they’re running on the production data center. You need to plan your disaster recovery strategy in case the entire production data center becomes unavailable.
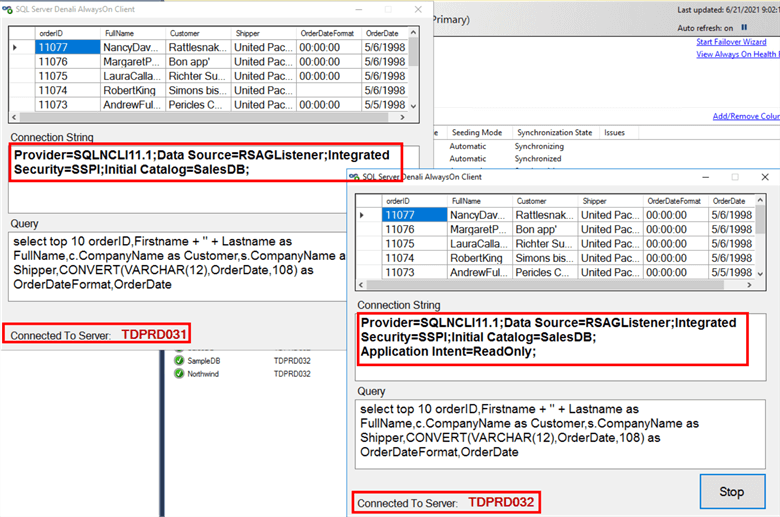
Test this configuration by running your reporting and analytics applications against the secondary replica. Be sure to add the connection string parameter Application Intent=ReadOnly in your applications.

Note that this already works just by adding the connection string parameter Application Intent=ReadOnly in your reporting and analytics applications. The challenge here is when you manually failover your read-scale Availability Group from your current primary replica to another, for example, from TDPRD031 to TDPRD032. You don’t want to keep modifying your application connection string every time you initiate a manual failover of your read-scale Availability Group. Imagine having to change hundreds of client applications’ connection string values. This is where the Availability Group listener name comes in. But since the Availability Group listener name points to the current primary replica, you want to configure the read-scale Availability Group to properly redirect reporting and analytical applications to the current secondary replica. Changing the Availability Group listener name and the DNS alias is much easier than modifying your applications’ connection string.
Step #5: Configure Read-Only Routing in the Read-Scale Always On Availability Groups Replicas
To allow redirection of reporting and analytical workloads to the secondary replica using the Availability Group listener name, you need to configure:
- A read-only routing URL. A read-only routing URL is the entry point of an application to connect to a readable secondary replica. It contains the system address and the port number that identifies the replica when acting as a readable secondary. This is the endpoint that reporting and analytical applications will connect to on the readable secondary replicas when they have the Application Intent=ReadOnly connection string parameter.
- A read-only routing list. A read-only routing list is a list of readable secondary replicas where the reporting and analytical applications will be redirected to. Since using the Availability Group listener name will automatically connect to the primary replica, the read-only routing list will tell client applications to go to the secondary replicas instead.
To configure the read-only routing URL,
- Open SQL Server Management Studio. From within Object Explorer, expand the Always On High Availability node, the Availability Groups node, and, then the name of your read-scale Availability Group.
- Right-click the read-scale Availability Group and select Properties.
- In the Read-Only Routing tab,
- under the section Read-only routing summary, in the Read-Only Routing URL column, enter the TCP endpoint address of the corresponding secondary replica in your production data center. Typically, this is in the form TCP://fully_qualified_domain_name:port number. Do this for all readable secondary replicas first before creating a read-only routing list.
- under the section Read-only routing list for: replica_name, select all replicas under the Available Replicas list and click Add. This will add the readable secondary replicas to the Read-only Routing List column.

- Click OK to define the read-only routing URL and read-only routing list.
Alternatively, you can use the T-SQL script below to configure the read-only routing lists and read-only routing URLs for the readable secondary replicas. The script is formatted for readability. I try not to use Read-Only Routing tab of the Availability Group properties dialog box because of the non-intuitive design of the user interface.
USE [master] GO --SET read-only routing URL when replica is running as readable secondary ALTER AVAILABILITY GROUP [ReadScale-AG] MODIFY REPLICA ON N'TDPRD031' WITH ( SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://TDPRD031.TESTDOMAIN.COM:1433') ) GO --SET read-only routing list when replica is running as primary ALTER AVAILABILITY GROUP [ReadScale-AG] MODIFY REPLICA ON N'TDPRD031' WITH ( PRIMARY_ROLE ( READ_ONLY_ROUTING_LIST =((N'TDPRD031',N'TDPRD032')) ) ) GO USE [master] GO --SET read-only routing URL when replica is running as readable secondary ALTER AVAILABILITY GROUP [ReadScale-AG] MODIFY REPLICA ON N'TDPRD032' WITH ( SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://TDPRD032.TESTDOMAIN.COM:1433') ) GO --SET read-only routing list when replica is running as primary ALTER AVAILABILITY GROUP [ReadScale-AG] MODIFY REPLICA ON N'TDPRD032' WITH ( PRIMARY_ROLE ( READ_ONLY_ROUTING_LIST =((N'TDPRD031',N'TDPRD032')) ) ) GO
You can test how the configuration works by running your reporting and analytical applications, connecting to the Availability Group listener name, and adding the Application Intent=ReadOnly connection string parameter. As shown in the screenshot below, applications will connect to the primary replica by default if you do not add the Application Intent=ReadOnly connection string parameter.
Keep in mind, since this is not a high availability solution, you need to have a disaster recovery strategy for when the primary replica becomes unavailable and the read-scale Availability Group needs to be manually failed over to the secondary replica. Also, should the entire production data center becomes unavailable, you need to configure the secondary replica in the disaster recovery data center to be both a primary replica and a readable secondary replica.
Next Steps
- Read the Microsoft documentation
- Read more on the following topics:

Edwin M. Sarmiento is the Managing Director of 15C, a consulting and training company that specializes on designing, implementing and supporting SQL Server infrastructures. He is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures running on the Microsoft server technology stack ranging from Active Directory to SharePoint and anything in between. He is very passionate about technology but has interests in music, professional and organizational development, and leadership and management matters when not working with databases. Edwin lives up to his primary mission statement: “To help people and organizations grow and develop their full potential.”
- MSSQLTips Awards: Champion Award (100+ tips) – 2017 | Author of the Year Contender – 2020, 2017

bugeye,
The client app is configured to connect to the DNS alias (RSAGListener) that points to the Availability Group primary replica (TDPRD031).
how did you get the query boxes to test which server your connecting to?
Just testing this feature and found the fatal flaw. A database cannot be a member of both a Failover AG and Read Scale AG. In short its a choice with SQL Enterprise….for High Availability AG or Read Scale AG not both. To expand slightly you have Core DatabaseA and youre requirement is to provide HA for the database, therefore you build a Always on Cluster and Add the database to an AG….tied to the Cluster Service. Instant Recovery. However a 2ndry requirement is to provide timely reporting. and you are not wishing users to use the Secondary Node…(Reasons are many) …. So you come across RSAG….alas you cant add the HA database to the RSAG as its already in AG….. therefore requiring MS Transaction replication to another Database or other means to create a 2nd Reporting Database to run along side but as part of the RSAG…. this somewhat defeats the point… as MS replication is invasive. and a pain… hey ho nice idea M$ come back to me when Databases can be in more than 1 AG and not requiring 2ndrys of the original AG.
The read-scale Availability Groups feature is only available in Enterprise Edition
Hi Edwin, thanks for sharing this article, but there is no mention of what version of SQL Server and what Edition is used in this scenario,
I used SQL server 2016 Standard Edition, can I implement this?