Problem
Many companies have a good percentage their information technology assets located in a local data center managed by their own team of experts or outsourced to a service provider that specializes in providing infrastructure. So far, we have explored how to work with Azure Data Factory sources and targets that are born in the cloud. This is a major limitation since most of the data assets reside in a local data center. How can with work with on-premises data sources using Azure Data Factory?
Solution
By default, the pipeline program executed by Azure Data Factory runs on computing resources in the cloud. This is called the “Auto Resolve Integration Runtime”. However, we can create our virtual machine and install the “Self-Hosted Integration Runtime” engine to bridge the gap between the cloud and the on-premises data center.
Background
The development environment created in the previous articles will be extended to support a Hybrid ELT design. There are a couple gotcha’s when setting up this design pattern. These issues and resolutions will be pointed out throughout our journey. Finally, multiple parameters were passed to the pipeline program to make it dynamic. However, the data movement within a system might flow between various sources and targets such as: MS SQL to raw zone, raw zone to refined zone, refined zone to Azure SQL DB. This means the number of parameters will increase to handle all these patterns. To reduce the management of multiple parameters, we will talk about how to use a single JSON object to pass the correct information to the given pipeline program.
Architectural Overview
To bridge the gap between on premises and in cloud, a virtual machine must have the self-hosted integration runtime (SHIR) installed and configured to work with a given Azure Data Factory service. The image below was taken from this MSDN article. To summarize the article, once the SHIR is registered with ADF, it looks for jobs to be processed from the movement services queue. If multiple SHIR’s are connected to a given ADF service for redundancy or throughput, the first machine to grab the message processes the job. This encompasses reading from the source system and writing to the target system in the cloud. While most people are pushing data to the cloud, the opposite can occur if needed. By default, the architecture is secure since messages and data are sent using HTTPS over the public internet. For extra security, a virtual network (V-NET) created on top of an Express Route or Point-To-Point VPN can route the packets thru a secure channel. It might be prudent to join the Virtual Machine to the Active Directory domain to alleviate credential issues in the future.

Now that we have a good understanding of the architecture, let us install and configure the self-hosted integration runtime in the next section.
Self-Hosted Integration Runtime
The purpose of this section is to give the reader an overview of how to install and configure the self-hosted integration runtime. Only key screen shots are shown in the steps below to guide you during your journey. Please navigate to the manage toolbox (menu) and select the integration runtimes under the connections tab. We can see the default “Auto Resolve Integration Runtime” is ready for any jobs or debug sessions we submit. Click the new button to start a new install.
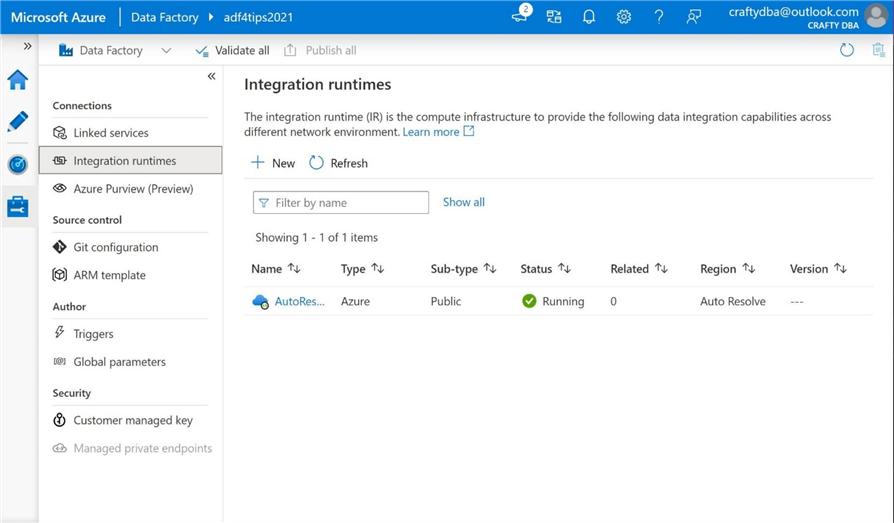
Some companies are running legacy SSIS packages using a different version of the runtime. Please select the Azure Self Hosted option to continue.

For some reason, another menu asks you to qualify the type of runtime setup. Again, please choose the self-hosted option and click continue.
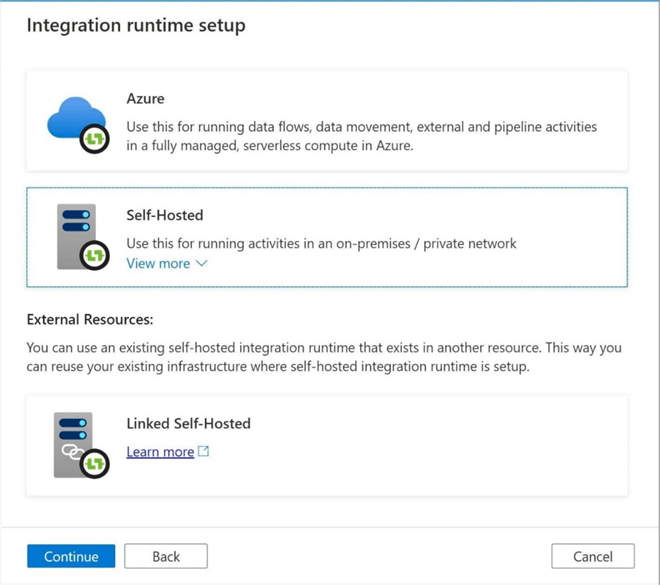
I always use a manual setup since other components are usually required to configure the SHIR software on the virtual machine. It is very import to grab either key 1 or key 2 and store this information in notepad.exe for later use. Please note that I gave the service a name of SHIR-01.
The image below shows the temporary directory with a bunch of files. For some reason, the download bundle from Microsoft has the latest two versions of the program and a release notes document. Spoiler alert, we will need two additional components if we want to write SPARK file formats in Azure. We will talk about why Java 8.x and the Visual C++ install are required.

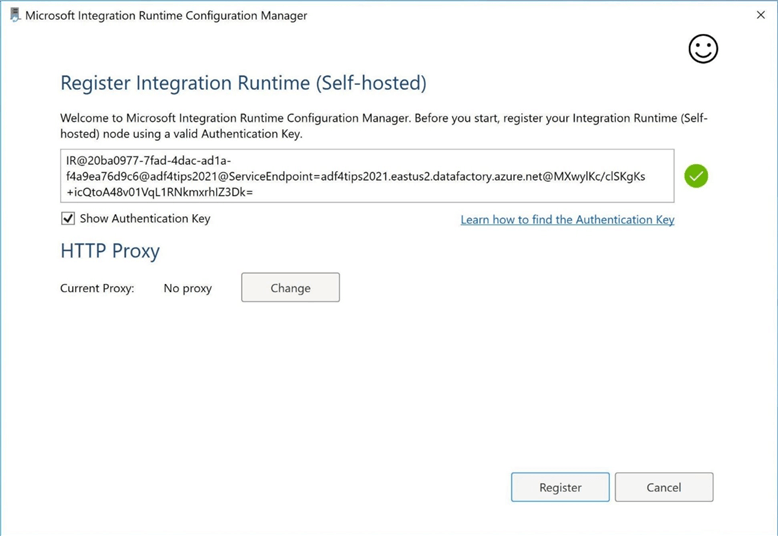
Please run the install program for the self-hosted integration runtime. At some point, you will be prompted to enter an authentication key. Please choose either key 1 or key 2 in the notepad file to complete the authentication.
I want to demonstrate how to transfer data from simulated on premises Microsoft SQL Server 2019 to Azure Data Lake Storage as a parquet file format in the raw zone.
To accomplish this task, I created a virtual machine named vm4sql19. To make life easy, I am going to install the SHIR software on the same server as the database engine. However, if there was some type of workgroup or domain in which another virtual machine could RDP to vm4sql19, then the software could be installed on that machine.
To recap, you do not need to install the SHIR software on your local on-premises SQL Server database. Just a virtual machine that is part of the domain and has access to the database.
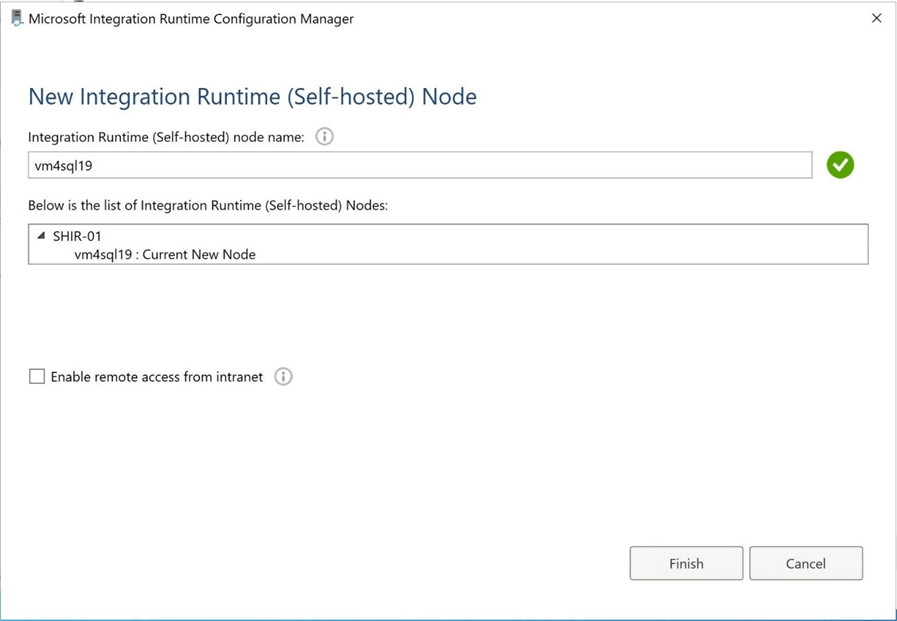
The above image shows the connection from the virtual machine was success. The below image shows that Azure Data Factory recognizes SHIR-01 as a functional self-hosted integration runtime.
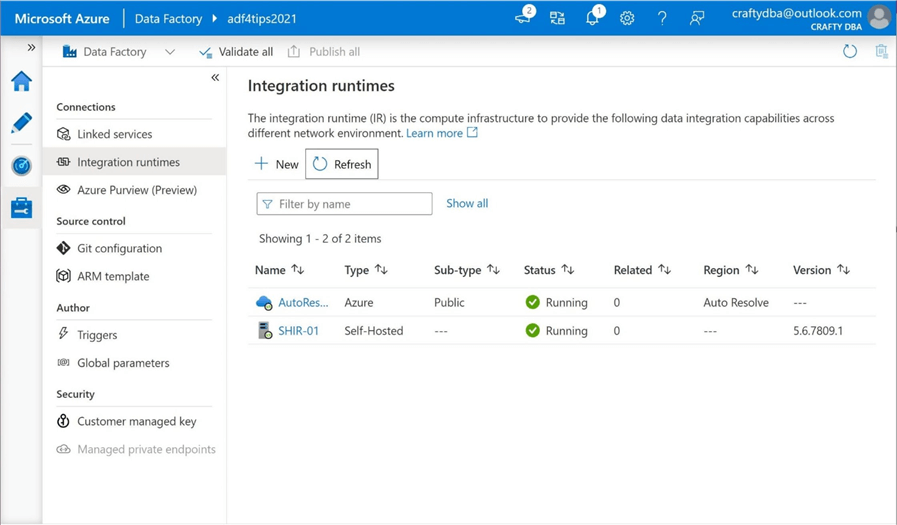
The self-hosted integration runtime allows a system design to bridge the gap between on premise and in cloud. Just remember that the computing power is now the CPUs on the virtual machine. To run more jobs, just scale the size of the virtual machine. To have redundancy and more processing power, add another virtual machine (node) to the name. There is a limit of 4 virtual machines to a given name.
Hybrid Dataset
To access a dataset which is not in Azure, we must use the self-hosted integration runtime named SHIR-01in the linked service declaration. Let us define a new linked service now. Please select SQL Server as the data store.

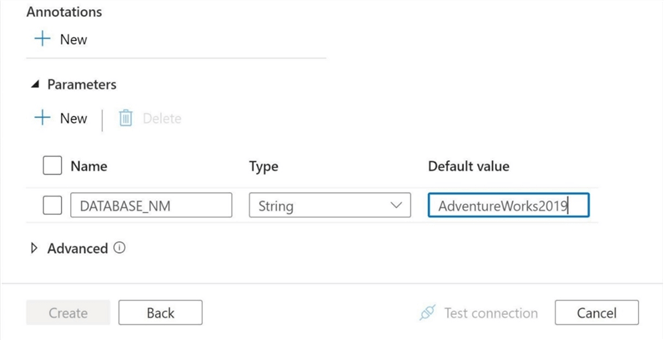
To date, I have talked about parameterizing pipelines and datasets. We can also parameterize linked services. This makes sense when a given source/target server has one or more database(s) that you want to grab data from. The image below shows the parameter named DATABASE_NM is pointing to the AdventureWorks2019 database.
Please fill in the following blanks with the correct information: integration runtime, server name, database name, authentication type, username and user password. Use the parameter for database name so that it is dynamic in nature. The last step is to test the connection named LS_MSSQL_VM42019. As we can see in the image below, we have had a successful test.

Hardcoding the password makes it difficult to rotate the password on a scheduled basis to prevent hackers. To make the security team happy at your company, I suggest you put key information like this into a key vault. The image below shows a linked service named LS_AKVS_SYSTEM_SECRETS has been defined to store our secrets.

The image below shows that both the username and the user password have been stored in the key vault for both the virtual machine and the SQL Server database.

If we try to modify the linked service named LS_MSSQL_VM42019 to pull the password from the key vault, we receive the following error. The managed identity for Azure Data Factory does not have an access policy that allows it to list and read secrets from the key vault. That can be easily fixed by a simple task in the Azure Portal.

Please navigate to the Azure Key Vault object. Go to the Access Policy menu under settings. Click add new policy. Please select the name of the Azure Data Factory managed identity, adf4tips2021, and give it full access to secrets. If you choose, we only need to list and read secrets. So, the total number of rights can be reduced further. Hit the save button to finish the task.

If we go back to the linked service and retest the connection, we can see a success. This means our linked service is pulling the password from key vault during runtime. This will make the rotation of the password very easy.

It is important that the connection to the integration runtime is changed from the azure default to the self-hosted one that we created. When possible, use parameters to allow greater flexibility with linked services, data sets and pipelines.
Hybrid Pipeline
It is time to revisit our dynamic pipeline from a previous article that supports multiple destination file formats. We want to change the source from Azure SQL database to Microsoft SQL database. Since the database is on premises (simulated), we want to use our new self-hosted integration runtime. I am using the Big Adventure tables from Adam Mechanic in the AdventureWorks2019 database. Also, we want to bring over the 10 other tables from the AdventureWorks2019LT database. The image below shows the new source dataset called DS_MSSQL_DATABASE_QUERY.

Unfortunately, the above definition will not solve our programming needs. While the linked service is parameterized, the data set is not parameterized. This is a key gotcha. We want to dynamically change the database name at the pipeline level. Therefore, we need to define another parameter at the data set level. I choose to keep the parameter names the same. The data set parameter is passed to the linked service at runtime.
I am re-using the DS_ADLS2_FILE_TYPE_PARQUET data set in this solution. No changes are required since we are writing a parquet file to the data lake. I did create a new pipeline that uses the switch activity to support multiple output file types. The name of this pipeline program is PL_CPY_VM4SQL19_TABLE_2_ADLS_FILE.

If we execute the pipeline program, we obtain the following error. Please see the paragraph on how to configure a self-hosted integration runtime virtual machine to support parquet files. In a nutshell, you need the Java Runtime Engine – 64 Bit JRE 8, the Microsoft Visual C++ 2010 redistributable and the JAVA_HOME environment variable correctly defined. A reboot of the virtual machine will harden any changes you make to the environment. I can write a Harvard Business Case on the number of clients that do not follow these simple steps.

To fix this runtime error, please log into the Virtual Machine and install the 64 Bit JRE version 8. The image shows the completed install of the runtime engine. Do not forget to put Java in the PATH environment variable for testing. Also, please define the JAVA_HOME environment variable.

The last program to install is the Microsoft Visual C++ 2010 runtime. Please see the prior screen shot of the c:\temp directory that shows the names and versions of the executables I used to configure the virtual machine.

I leave the execution of the pipeline program a task for you to perform. However, I know that if the steps were followed correctly a parquet file with appear in the raw zone of the Azure Data Lake Storage.
Child Pipeline
A better way to pass multiple parameters to an Azure Data Factory pipeline program is to use a JSON object. I choose to name my parameter after what it does, pass meta data to a pipeline program. The image below shows how we end up with only one pipeline parameter which is an object instead of multiple parameters that are strings or integers.

We can use the following JSON objects to write out the address table in each of the file different file formats.
{ "DATABASE_NM": "adventureworkslt2019", "SCHEMA_NM": "saleslt", "TABLE_NM": "address", "ZONE_NM": "bronze", "FILE_TYPE": "del", "FILE_EXT": "csv", "DEL_CHAR": "," }
{ "DATABASE_NM": "adventureworkslt2019", "SCHEMA_NM": "saleslt", "TABLE_NM": "address", "ZONE_NM": "bronze", "FILE_TYPE": "avro", "FILE_EXT": "avro", "DEL_CHAR": "" }
{ "DATABASE_NM": "adventureworkslt2019", "SCHEMA_NM": "saleslt", "TABLE_NM": "address", "ZONE_NM": "bronze", "FILE_TYPE": "json", "FILE_EXT": "json", "DEL_CHAR": "" }
{ "DATABASE_NM": "adventureworkslt2019", "SCHEMA_NM": "saleslt", "TABLE_NM": "address", "ZONE_NM": "bronze", "FILE_TYPE": "parquet", "FILE_EXT": "parquet", "DEL_CHAR": "" }
{ "DATABASE_NM": "adventureworkslt2019", "SCHEMA_NM": "saleslt", "TABLE_NM": "address", "ZONE_NM": "bronze", "FILE_TYPE": "orc", "FILE_EXT": "orc", "DEL_CHAR": "" }
One might try to reference the object directly using the following expression. The text box below shows the expression of the TSQL to pull the data from the source table.
@concat('select * from ', pipeline().parameters.META_DATA.SCHEMA_NM, '.', pipeline().parameters.META_DATA.TABLE_NM)
However, this will result in an error if the PL_CPY_VM4SQL19_TABLE_2_ADLS_FILE child pipeline is called from the parent pipeline called PL_SKD_SRC_RDBMS_2_ADLS_RAW. If we look at the JSON passed from the parent to the child, we can see that a nested structure is now being used and the data is escaped.

We can fix this issue by converting the variable to a string and then to a json format before selecting the element we want. The code below will now work for both the child as well as the parent pipeline program.
@concat('select * from ', json(string(pipeline().parameters.META_DATA)).SCHEMA_NM, '.', json(string(pipeline().parameters.META_DATA)).TABLE_NM)
Again, the purpose of this program is to take table data from either Adventure Works database and write it as files in the raw zone of the data lake. We will have to go ahead and change both the source/target entries for each copy command to support all five file types. We will work on the delimited (DEL) format first.

Since the Big Adventure works tables have a lot of records, I have decided to increase the timeout value for the copy activity to 30 minutes.
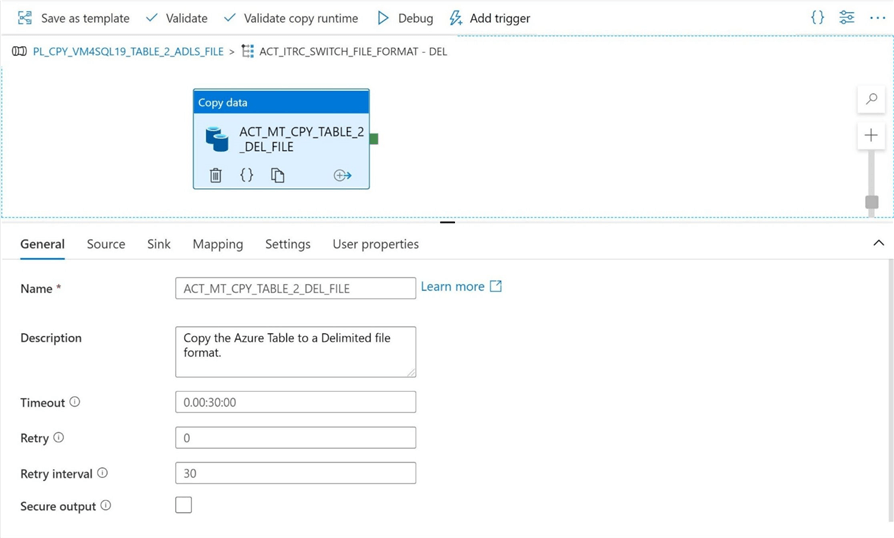
For the source, make sure both the database name for the dataset and the query are updated with the correct expressions.

For the target, make sure the directory name, the file name and the delimiter parameters are using the updated expressions.

If you completed the changes correctly, we can execute the unit test for the delimited file format and obtain a successful execution.

The next step is to repeat the process for the remaining 4 file types. The image below shows all file types successfully unit tested for the address table.

We can see that meta data driven pipelines are more useful than hard coded ones. As we add more child pipeline programs to our toolbox, the number of parameters will increase. To reduce the management of multiple parameters, we will want to use a single JSON object to pass the correct information to the given pipeline program.
Parent Pipeline
The main goal of our ELT solution is to move data from simulated on-premise Microsoft SQL Server tables to parquet files in the raw zone of the Azure Data Lake. Previously, we moved the tables from the AdventureWorksLT database. We want to add two Big Adventure tables as sources to the data lake. The image below shows the final program that performs a full copy of the table data to the parquet files.

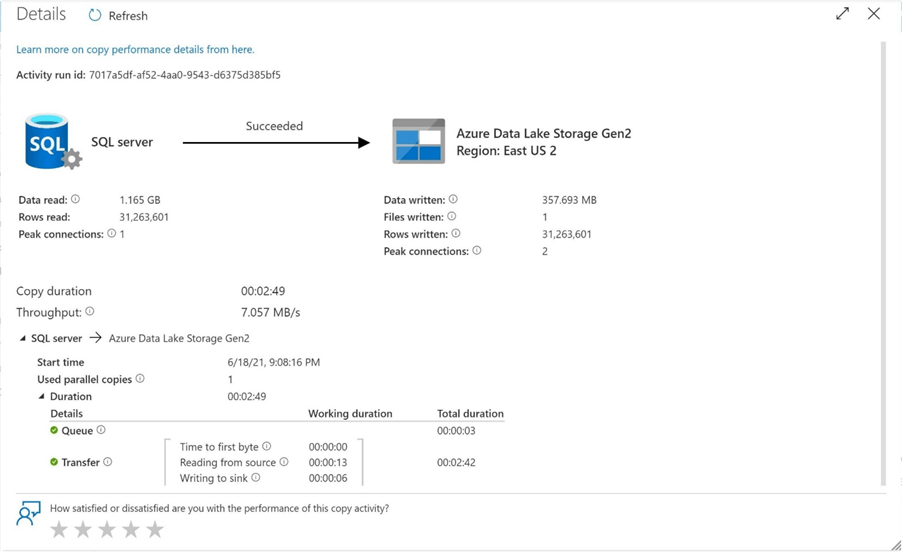
Let us take a quick look at the big adventure tables. We can see that the product table has 25K rows and the transaction table has 31M rows.

The transaction table will take the longest time to transfer. The image below shows the copy activity taking 2 minutes and 49 seconds to complete.
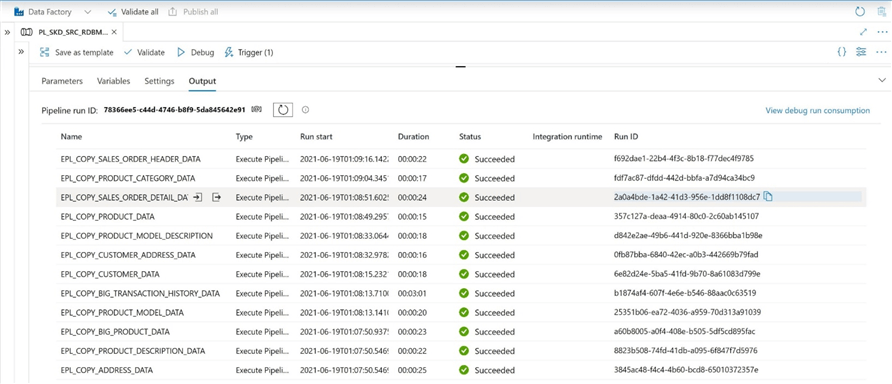
Looking at the final output from our debug execution, we can see that all pipelines except one completed in 25 seconds or less.
I will continue this journey of learning this summer by expanding on lessons taught so far. I moved any previous pipelines and datasets to a directory called beta.
One observation that was made from this final integration test is that large files make take significant time to transfer. Right now, we are playing with a test dataset that has millions of records. Some of my clients have datasets that have billions of records. Therefore, if an error occurs, we do not want to reprocess the whole file which may take several hours. A better solution is to partition the large data source in N jobs. If one job fails, we only have to pull 1/N of the data from the source table to the target data lake.
Summary
Today, we want to expand our previous dynamic pipeline to allow for datasets that are on premises. Many companies still have a large majority of their data assets located in local data centers. The self-hosted integration runtime is a key component of a hybrid data architecture. However, it is important to install additional libraries if hive file types are being used in the data lake design. I suggest using the parquet file format when possible since it is the building block of delta tables.
Many Data Factory linked services allow for the use of secrets from an Azure Key Vault. I like using key vaults in my design when the customer does not want to use a Managed Identity. Furthermore, I might not see a client for several months but will have no problem using the system as a developer once access to the key vault is granted. To-recap todays lesson, the managed identity from Azure Data Factory must be given at least READ and LIST rights to retrieve the secrets for the linked service.
Previously, multiple single purpose parameters were passed to the pipeline program to allow for different execution patterns. This is the key idea behind a meta data driven design. However, as we add more child pipeline programs to our toolbox to solve more problems, we can see that the number of parameters will increase. Therefore, it is important to use a more complex data type to pass the parameters. At its core, Azure Data Factory passes information from one pipeline to another using JSON. Therefore, the JSON object type is an ideal choice for our meta data.
The previous program was retrofitted to use a single parameter using a complex data type instead of multiple parameters that use simple data types. During unit testing of the final pipeline, we noticed that the execution time of the “big transaction” table was ten times more than the normal execution time. In the real world, the failure of full load process might result in a re-execution of the program that might take hours to execute. There must be a way to reduce the risk of loading all the records again. A better way to process large files is to partition the table in N segments. This will allow for the parallel execution of the jobs and reduce the risk of re-processing an extremely large number of records.
Today was our third adventure in advanced ADF programming. Please stay tuned for more exciting articles to come this summer. Enclosed is Azure Resource Management (ARM) template export of all the Azure Data Factory objects that were created today.
Next Steps
- Partitioning source data tables for faster transfer times.
- Preventing schema drift with the tabular translator mapping.
- Using incremental loads to decrease daily processing time of large data sources.
- Custom execution, error, and catalog logging with Azure Data Factory.
- Creating a meta data driven framework for Azure Data Factory
- How to scale parallel processing with Azure Data Factory

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023


Dear reader, the focus of this article is how to use the self hosted integration runtime to read from on premises and write to the cloud, namely a data lake. ADLS is more secure due to two security layers, RBAC and ACLs. I’m sure the copy and other activities can fulfill your business problem. Sincerely John
azure data factory i have different types of files available(.txt,.xml,.csv) in blob storage copy to blob or azure sql database