Problem
In my previous articles, Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2 and Load Data Lake files into Azure Synapse Analytics Using Azure Data Factory, I demonstrated how to 1) fully load an Azure Data Lake Storage Gen2 from a SQL Database and then 2) fully load Azure Synapse DW from the Data Lake Storage Gen2 parquet files using Azure Data Factory’s Copy Activity.
Additionally, this E-L-T process was driven by a meta-data approach by using pipeline parameters populated in a SQL table. While this is a useful E-L-T method, how can we advance this process to address how to 1) incrementally load Azure Data Lake Storage from a SQL source and 2) Update and Insert (Upsert) the incremental records into an Azure Synapse DW destination?
Solution
In this article, we will explore the inbuilt Upsert feature of Azure Data Factory’s Mapping Data flows to update and insert data from Azure Data Lake Storage Gen2 parquet files into Azure Synapse DW. It is important to note that Mapping Data flows does not currently support on-premises data sources and sinks, therefore this demonstration will utilize an Azure SQL Database as the source dataset.
Additionally, we will use a custom method of incrementally populating Data Lake Storage gen2 with parquet files based on the Created Date within the Azure SQL Database. This article assumes that you are familiar with my previous articles which demonstrate a meta-data driven E-T-L approach using Azure Data Factory.
Create a Parameter Table
Let’s begin the process by creating a pipeline_parameter table in an Azure SQL Database. This table will contain the parameter values that will be configured to control the ADF pipeline.
In particular, we will be interested in the following columns for the incremental and upsert process:
- upsert_key_column: This is the key column that must be used by mapping data flows for the upsert process. It is typically an ID column.
- incremental_watermark_value: This must be populated with the source SQL table’s value to drive the incremental process. This is typically either a primary key id or created/last updated date column. It can be updated by a stored procedure.
- incremental_watermark_column: This is simply the column name of for the value populated in the incremental_watermark_value column. This is typically either a primary key id or created/last updated date column. It can be updated by a stored procedure.
- process_type: This must be set to incremental for ADF to know which records within this table are incrementals.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_parameter]( [PARAMETER_ID] [int] IDENTITY(1,1) NOT NULL, [server_name] [nvarchar](500) NULL, [src_type] [nvarchar](500) NULL, [src_schema] [nvarchar](500) NULL, [src_db] [nvarchar](500) NULL, [src_name] [nvarchar](500) NULL, [dst_type] [nvarchar](500) NULL, [dst_name] [nvarchar](500) NULL, [include_pipeline_flag] [nvarchar](500) NULL, [partition_field] [nvarchar](500) NULL, [process_type] [nvarchar](500) NULL, [priority_lane] [nvarchar](500) NULL, [pipeline_date] [nvarchar](500) NULL, [pipeline_status] [nvarchar](500) NULL, [load_synapse] [nvarchar](500) NULL, [load_frequency] [nvarchar](500) NULL, [dst_folder] [nvarchar](500) NULL, [file_type] [nvarchar](500) NULL, [lake_dst_folder] [nvarchar](500) NULL, [spark_flag] [nvarchar](500) NULL, [dst_schema] [nvarchar](500) NULL, [distribution_type] [nvarchar](500) NULL, [load_sqldw_etl_pipeline_date] [datetime] NULL, [load_sqldw_etl_pipeline_status] [nvarchar](500) NULL, [load_sqldw_curated_pipeline_date] [datetime] NULL, [load_sqldw_curated_pipeline_status] [nvarchar](500) NULL, [load_delta_pipeline_date] [datetime] NULL, [load_delta_pipeline_status] [nvarchar](500) NULL, [upsert_key_column] [nvarchar](500) NULL, [incremental_watermark_column] [nvarchar](500) NULL, [incremental_watermark_value] [datetime] NULL, PRIMARY KEY CLUSTERED ( [PARAMETER_ID] ASC )WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO
Create a Source Query for the ADF Pipeline
Now that we have created our pipeline_parameter. Let’s write a custom SQL query that will be used as the source of the ADF pipeline.
Notice the addition of a SQLCommand and WhereValue in the query below which could be used to dynamically create a SQL statement and where clause based on whether the process type is full or incremental. For the purposes of this demo, we will only apply a filter for the incrementals, but the query demonstrates the flexibility to incorporate full loads into the same source query.
select
src_schema,
src_db,
src_name,
dst_schema,
dst_type,
dst_name,
dst_folder,
process_type,
file_type,
load_synapse,
distribution_type,
upsert_key_column,
incremental_watermark_column,
case
when process_type = 'FULL' then 'select * from ' + src_schema + '.' + src_name + ' where 1 = '
when process_type = 'Incremental' then 'select * from ' + src_schema + '.' + src_name + ' where ' + incremental_watermark_column + ' > '
end as SQLCommand,
case
when process_type = 'FULL' then '1'
when process_type = 'incremental' then cast(isnull(incremental_watermark_value,'yyyy-MM-dd') as varchar(50))
end as WhereValue,
dst_folder + '/' + dst_name+ '/' + file_type+ '/' + format(getdate(),'yyyy-MM-dd') as FolderName,
dst_name +'.' + file_type as FileName
from
dbo.pipeline_parameter
where load_synapse = 1
AND process_type = 'incremental'
Here is the result of the query after populating the pipeline_parameter with one incremental record that we want to run through the ADF pipeline.
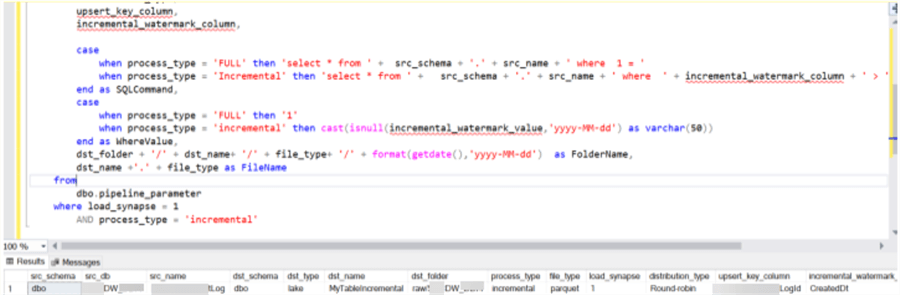
Add the ADF Datasets
Next, lets head over to ADF and create the following datasets.
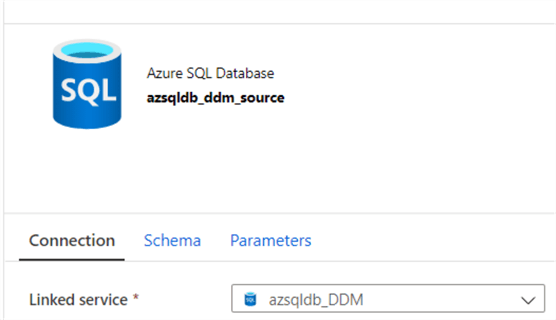
Azure SQL Database
We’ll need an Azure SQL Database source dataset.
Azure Data Lake Storage Gen2 – Parquet
We will also need an Azure Data Lake Storage Gen2 dataset that we can use within mapping data flows to create the parquet files.

Also add the following parameters to the parquet configuration section.

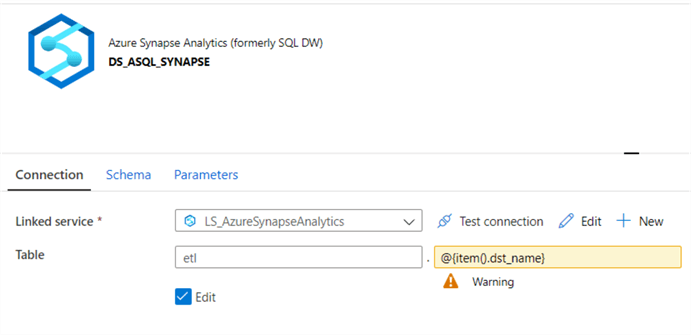
Azure Synapse Analytics – DW
Finally, we will need an Azure Synapse DW destination dataset.
Create the ADF Pipeline
Now that we have created the required datasets, let’s begin configuring the ADF pipeline activities.
Lookup – Get-Tables
Let’s begin with a look up to get the tables needed for the ADF pipeline. Here is where we will add the query that was created in the previous steps.

ForEach – Copy-Each-Table
Also, configure the Foreach loop settings as follows.

Mapping Data Flow – SQL to Lake Incremental
Now we can get started with building the mapping data flows for the incremental loads from the source Azure SQL Database to the sink Data Lake Store Gen2 parquet folders and files.
The FolderName and FileName were created in the source ADLS parquet dataset and used as a source in the mapping data flow.

The parameters contain the SQLCommand, WhereValue, and FileName.

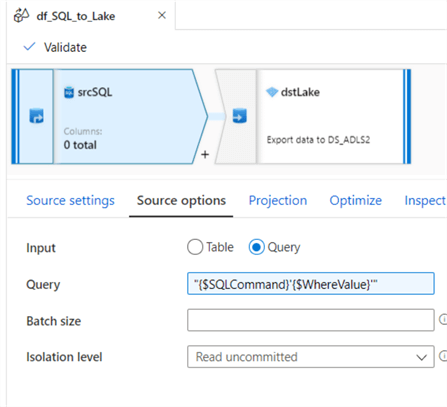
The source settings of the mapping data flow are configured as follows:

The source options of the data flow are configured as follows and uses the string interpolation expression feature. For more on building expressions with mapping data flows, read: Build expressions in mapping data flow.
Next, lets configure the destination sink of the mapping data flow as follows:

The settings will indicate the single file output FileName.
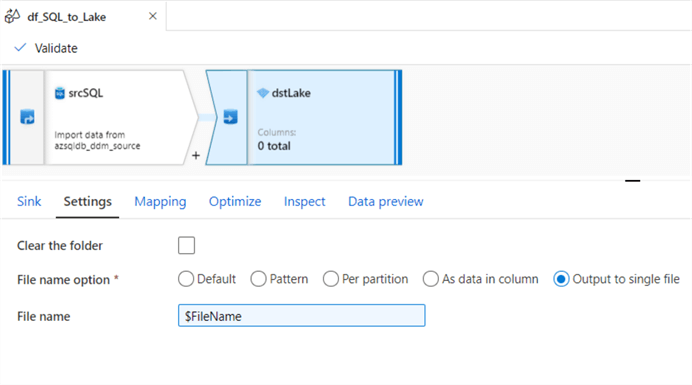
And we’ll used single partitioning in the optimize tab.

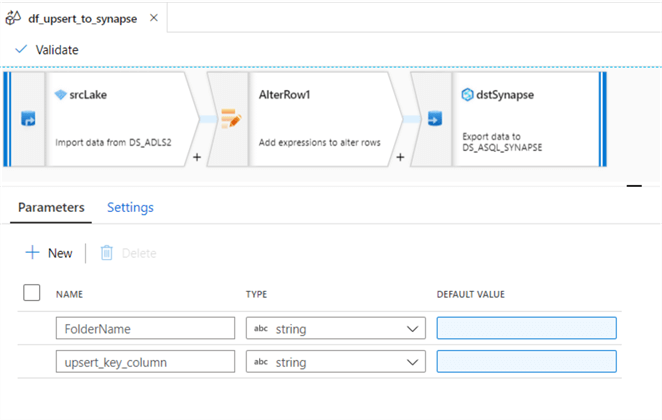
By clicking on the blank space of the mapping data flow canvas, the mapping data flow parameters tab will appear. Add the following parameters.
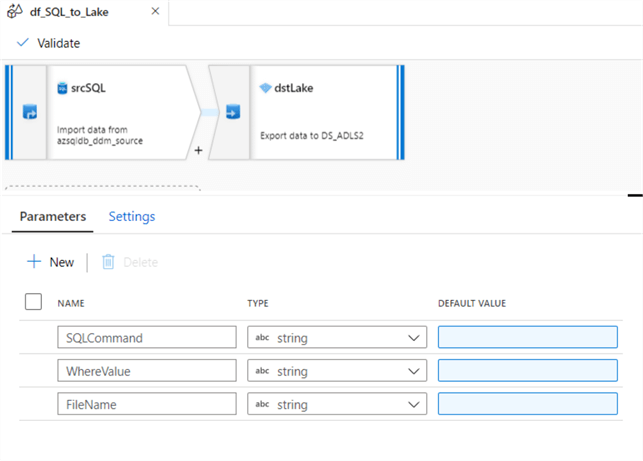
Mapping Data Flow – Incremental Upsert from Lake to Synapse
Now that we’ve created and configured the SQL to Lake Incremental mapping data flow pipeline, its time to create and configure the incremental upsert from lake to synapse pipeline.
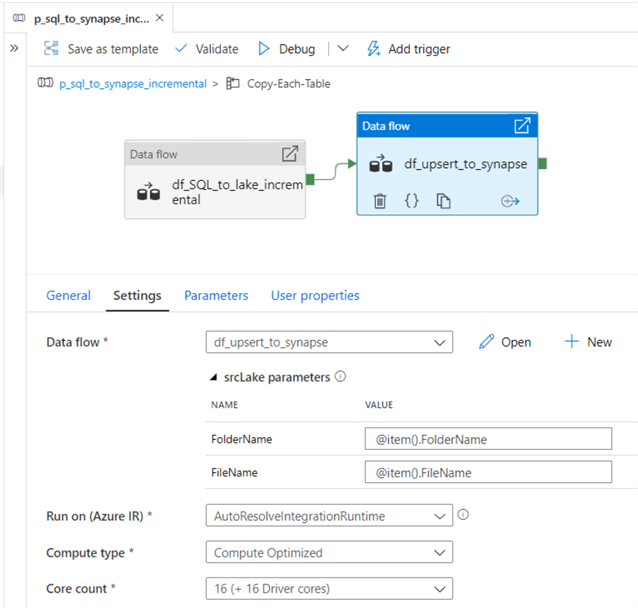
Ensure to configure the following data flow parameters.
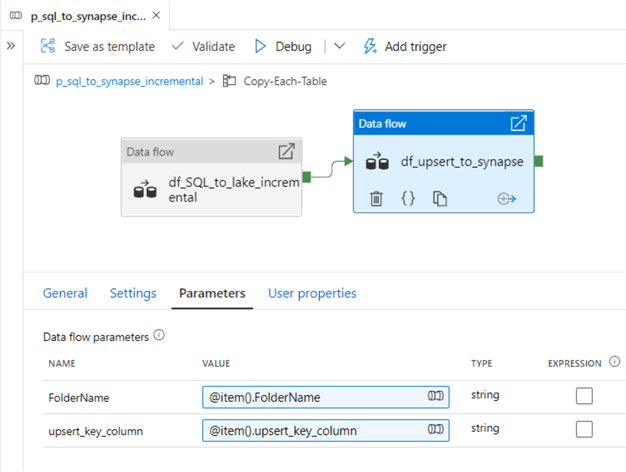
This data flow will contain the following three activities.
Begin by configuring the settings of the lake source as follows:
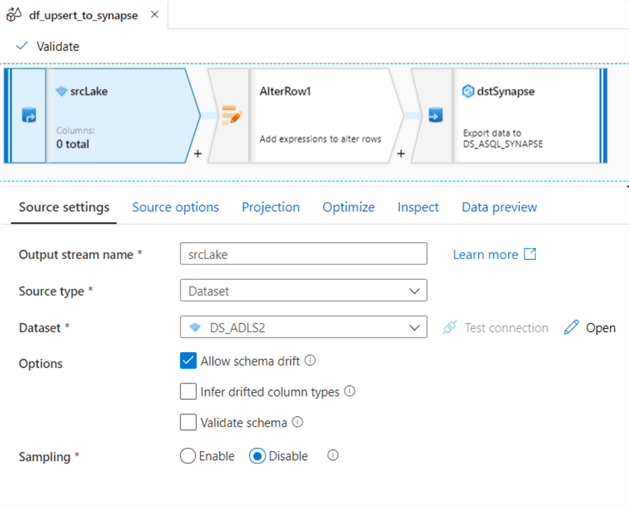
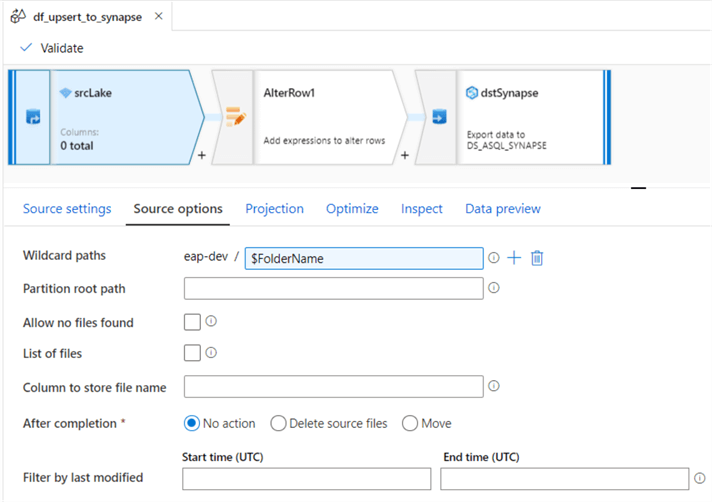
Next, ensure that the source options tab contains the parameterized FolderName.
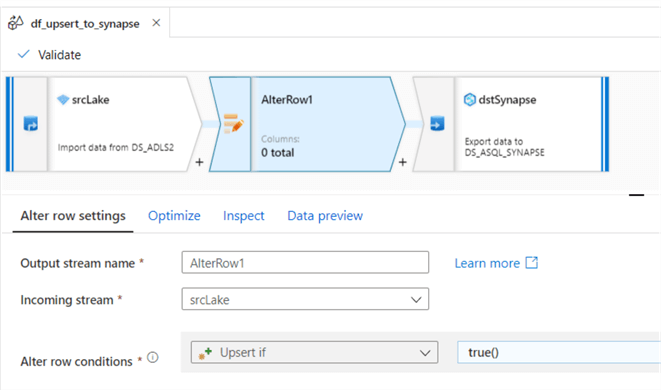
Add an AlterRow transform activity and add an Upsert if row condition to equal true().
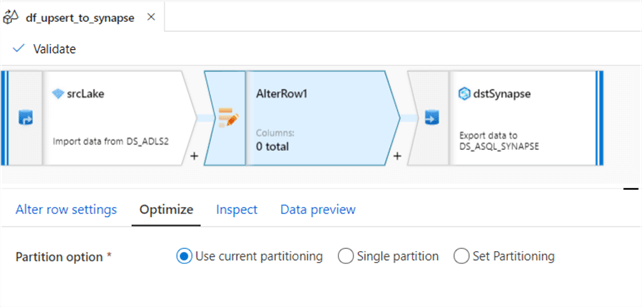
I used current partitioning within the optimize tab but there may be opportunities to explore setting the partitioning for big data workloads and to improve performance.
Finally, configure the destination Synapse dataset.
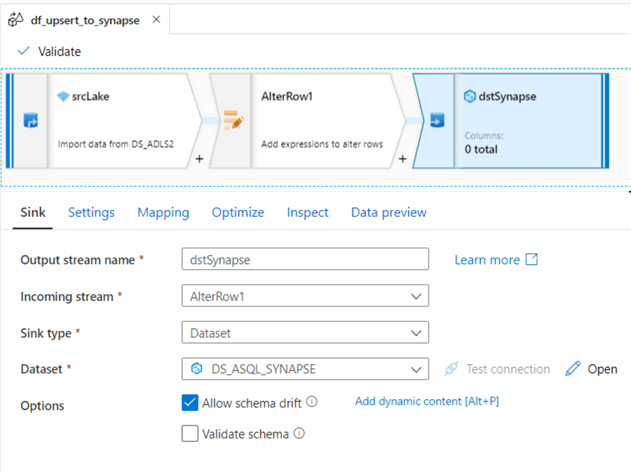
Within the settings tab, choose ‘Allow Upsert’ for the update method and add the upsert_key_column that we created and populated in the pipeline parameter table. I have chosen to not ‘Enable Staging’ for this demo but this may be a good option for performance optimization purposes.

Finally, ensure that the mapping data flow parameters contain the FolderName and upsert_key_column. To get to these parameters, remember to click into the white space of the mapping data flow canvas.
Run the ADF Pipeline, Test & Verify the Results
Now that we have created the ADF pipeline, lets run it to test and verify the results.
Verify Incremental SQL to Synapse Pipeline Results
After running this pipeline, we can see that the end-to-end pipeline succeeded and copied over one table since we only had one record in the pipeline_parameter table.
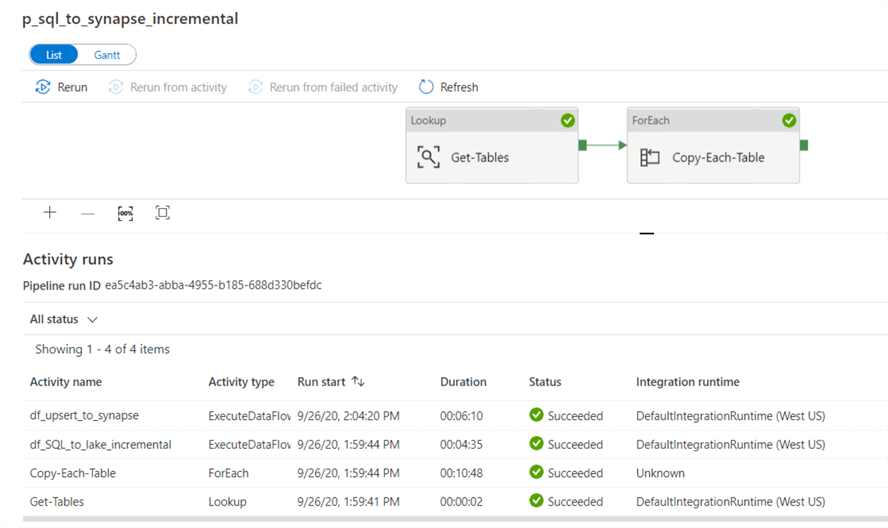
Verify Incremental SQL to Lake ADF Pipeline Results
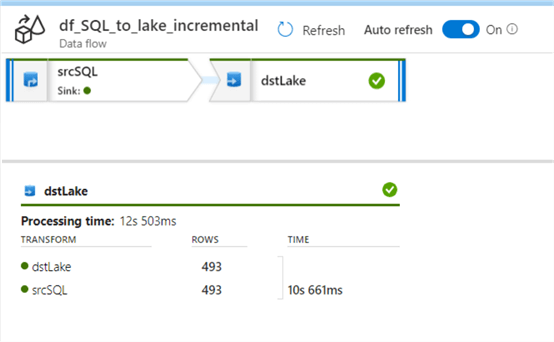
The pipeline copied 493 rows from the source Azure SQL Database table to a parquet file in ADLS2.
Verify Upsert Incremental Lake to Synapse ADF Pipeline Results
The incremental upsert from ADLS copied over 493 rows to Synapse.
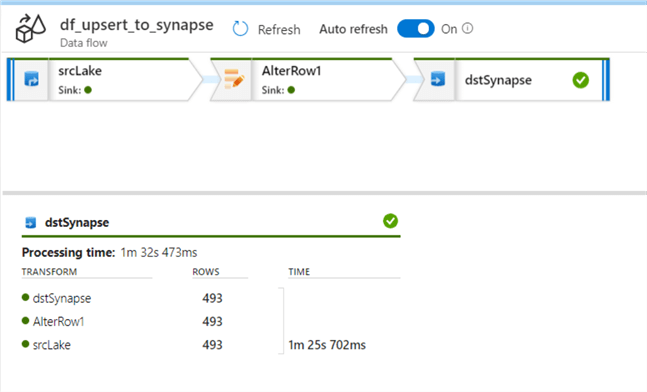
Verify Source SQL Record Count
The reason we have 493 rows in because the source contains 493 rows with a created date greater than April 1, 2020 and since this was our incremental_watermark_value defined in the pipeline_parameter table, that is how many records the ADF pipeline is expected to incrementally load.

Verify Lake Folder & Parquet File Path
We can also verify that ADLS folders along with a parquet file has been created.

Verify Destination Synapse Record Count
Finally, when we run a SQL count statement on the destination Synapse DW table, we can also confirm that it contains 493 records which confirms that the incremental pipeline worked as expected.
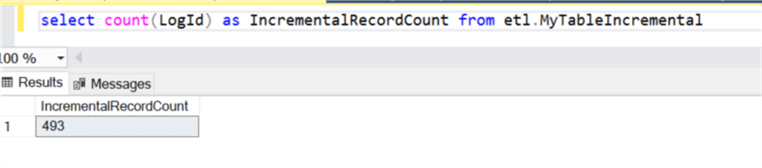
Insert a Source SQL Record
Now that we have confirmed that the incremental sql to synapse pipeline worked as expected, let’s also verify that the insert portion of the upsert command works as expected by adding an additional record to the source SQL table where created date is greater than April 1, 2020.
After adding the record and running a count, we can see that the query now returns 494 records rather than 493.

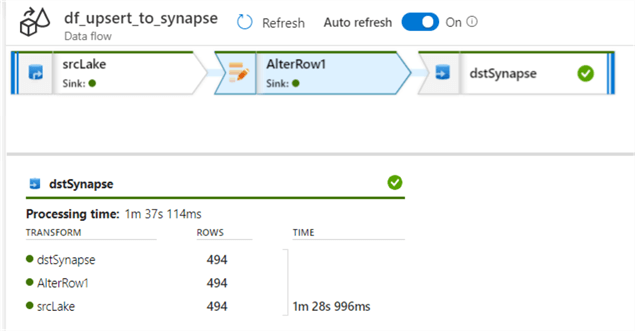
Verify Incremental SQL to Lake ADF Pipeline Results
Once again, when we run the pipeline, we can see the new pipeline log results return a count of 494 from SQL to Lake.

Verify Upsert Incremental Lake to Synapse ADF Pipeline Results
Also, we can see the new pipeline log results return a count of 494 from Lake to Synapse.
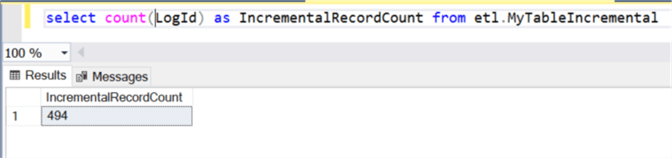
Verify Destination Synapse Record Count
Finally, the destination Synapse DW Table also contains 494 records, which confirms that the insert worked as expected.
Update a Source SQL Record
Let’s run one final test to ensure that the Update command of the mapping data flow Upsert works as expected. For this test, I’ve updated the table to set the FacilityId to equal 100 where the created date is greater than April 1, 2020. This updated two rows in the source SQL table.

Verify Destination Synapse Record Count
As expected, the destination Synapse DW table currently has no records with FacilityID = 100.
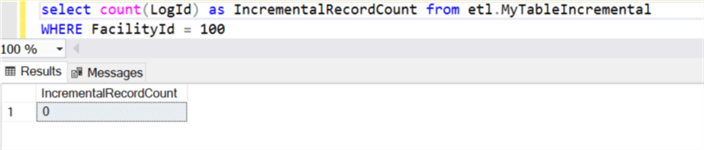
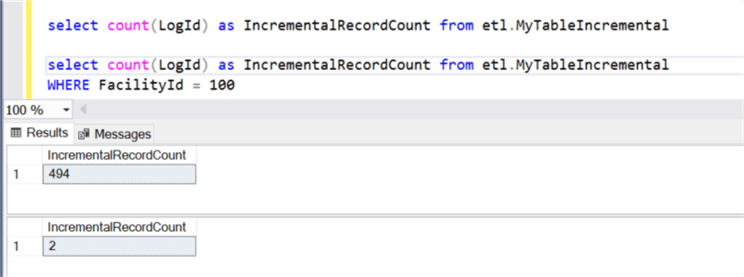
After running the pipeline again, we can verify that the destination Synapse DW table still contains 494 rows and has two records that have been updated with a FacilityId of 100. This finally confirms that both the update and insert commands along with incremental loads work as expected from the Source SQL table to ADLS and finally to Synapse DW.
Next Steps
- For more information on creating parameters in mapping data flows, read Parameterizing mapping data flows.
- For more information on integrating mapping data flows with your data warehouse, read my article: Azure Data Factory Mapping Data Flow for Datawarehouse ETL.
- For more information on using mapping data flows for Big data lake aggregations, read my article: Azure Data Factory Mapping Data Flows for Big Data Lake Aggregations and Transformations.
- For more information on an Incremental ADF ETL process, read: Incrementally load data from Azure SQL Database to Azure Blob storage using the Azure portal.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


Thanks! that’s an extensive and useful article.
I would like to ask you about updating the watermark value in the parameters table. How would you do it if you have multiple source tables?
BR. Paul
Hello, I receive the same error … doesn’t say a lot …
Don’t you get this error
Operation on target Data flow1 failed: {“StatusCode”:”DF-Executor-InvalidOutputColumns”,”Message”:”Job failed due to reason: The result has 0 output columns. Please ensure at least one column is mapped”,”Details”:””}
How this error has been handled in your case?
Thanks!