Problem
In my previous article, Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2, I demonstrated how to create a dynamic, parameterized, and meta-data driven process to fully load data from a On-Premises SQL Servers to Azure Data Lake Storage Gen2. Next, I am interested in fully loading the parquet snappy compressed data files from ADLS gen2 into Azure Synapse DW. One of my previous articles discusses the COPY INTO statement syntax and how it can be used to load data into Synapse DW.
What other options are available for loading data into Azure Synapse DW from Azure Data Lake Storage Gen2 using Azure Data Factory?
Solution
Azure Data Factory’s Copy activity as a sink allows for three different copy methods for loading data into Azure Synapse Analytics. In this article, I will explore the three methods: Polybase, Copy Command(preview) and Bulk insert using a dynamic pipeline parameterized process that I have outlined in my previous article.
Pre-requisites
Read and implement the steps outlined in my three previous articles:
- Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2
- Logging Azure Data Factory Pipeline Audit Data
- COPY INTO Azure Synapse Analytics from Azure Data Lake Store gen2
Create the Datasets
As a starting point, I will need to create a source dataset for my ADLS2 Snappy Parquet files and a sink dataset for Azure Synapse DW.
DS_ADLS2_PARQUET_SNAPPY_AZVM_SYNAPSE
I’ll start by creating my source ADLS2 Dataset with parameterized paths. Note that I have pipeline_date in the source field. This column is driven by the pipeline_date field in the pipeline_parameter table that I created in my previous article Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2 and then populated in my next article, Logging Azure Data Factory Pipeline Audit Data. Basically, this pipeline_date column contains the max folder date, which is valuable in this process since there may be multiple folders and we want to be able to load the latest modified folder.

I’ll also add the parameters that I’ll need as follows:

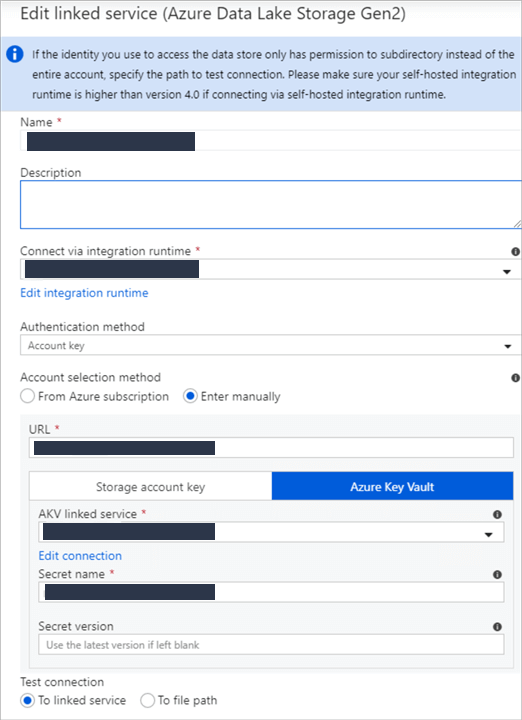
The linked service details are below. Azure Key Vault is being used to store the credential secrets. This will be relevant in the later sections when we begin to run the pipelines and notice any authentication errors.
DS_ADLS2_PARQUET_SNAPPY_AZVM_MI_SYNAPSE
The difference with this dataset compared to the last one is that this linked service connection does not use Azure Key Vault. I’ll use this to test and switch between the Key Vault connection and non-Key Vault connection when I notice errors later.

Similar to the previous dataset, add the parameters here:

The linked service details are below. Azure Key Vault is not being used here. Again, this will be relevant in the later sections when we begin to run the pipelines and notice any authentication errors.

DS_ASQLDW
The sink connection will be to my Azure Synapse DW. I am using parameters to specify my schema and table name. This is a good feature when we need the for each loop to create multiple tables using the same sink dataset.

Create the Pipeline
Now that my datasets have been created, I’ll create a new pipeline and then add a Lookup connected to a ForEach loop.

Based on my previous article where I set up the pipeline parameter table, my lookup will get a list of tables that will need to be loaded to Azure Synapse. Note that currently this is specified by WHERE load_synapse =1.

SELECT [server_name] ,[src_type] ,[src_schema] ,[src_db] ,[src_name] ,[dst_type] ,[dst_name] ,[include_pipeline_flag] ,[partition_field] ,[process_type] ,[priority_lane] ,[pipeline_date] ,[pipeline_status] ,[dst_folder] ,[file_type] FROM [dbo].[pipeline_parameter] WHERE load_synapse = 1
Within the settings of the ForEach loop, I’ll add the output value of the Lookup. Remember to leave the ‘Sequential’ box unchecked to ensure multiple tables will process in parallel. The default ‘Batch count’ if left blank is 50.

I’ll also add one copy activity to the ForEach activity. Click the pencil icon to view the Copy activity.

The source is set to DS_ADLS2_PARQUET_SNAPPY_AZVM_SYNAPSE, which uses an Azure Key Vault in the linked service connection.
I have added the dynamic parameters that I’ll need. Note that the parameters were defined in the dataset.

Finally, I will choose my DS_ASQLDW dataset as my sink and will select ‘Bulk Insert’ with an ‘Auto create table’ option ‘enabled’.

Based on the current configurations of the pipeline, since it is driven by the pipeline_parameter table, when I add (n) number of tables/records to the pipeline parameter table and set the load_synapse flag to = 1, then the pipeline will execute and load all tables to Azure Synapse in parallel based on the copy method that I select.
Choose the Copy Method
There are three options for the sink copy method. PolyBase, Copy command (preview) and Bulk insert are all options that I will demonstrate in this section.
Bulk Insert
See BULK INSERT (-Transact-SQL) for more detail on the BULK INSERT Syntax.
Within the Sink of the Copy activity, set the copy method to BULK INSERT.
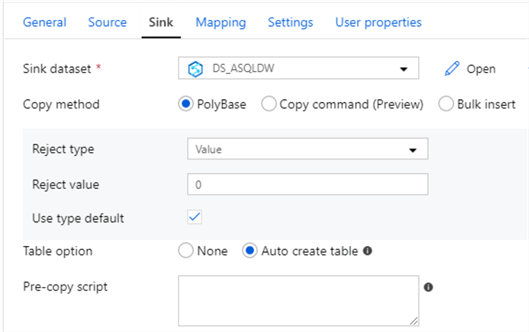
‘Auto create table’ automatically creates the table if it does not exist using the schema from the source file. This isn’t supported when sink specifies stored procedure or copy activity is equipped with the staging settings. For my scenario, the source file is a parquet snappy compressed file that does not contain incompatible data types such as VARCHAR(MAX) so there should be no issues with the ‘Auto Create Table’ option.
Note that the Pre-copy script will run before the table is created so in a scenario using ‘Auto create table’ when the table does not exist, run it without the pre-copy script first to prevent errors then add the pre-copy script back once the tables have been created for on-going full loads.
If the default Auto Create Table option does not meet the distribution needs for custom distributions based on tables, then there is an ‘Add dynamic content’ that can be leveraged to use a distribution method specified in the pipeline parameter table per table.
TRUNCATE TABLE @{item().src_schema}.@{item().dst_name}

After running the pipeline, it succeeded using the BULK INSERT copy method.

Below are the details of the Bulk Insert Copy pipeline status.

After querying the Synapse table, I can confirm there are the same number of rows in the table.

The Bulk Insert method also works for an On-premise SQL Server as the source with Azure Synapse being the sink.
PolyBase
For more detail on PolyBase, read What is PolyBase?
Select PolyBase to test this copy method.
See Copy and transform data in Azure Synapse Analytics (formerly Azure SQL Data Warehouse) by using Azure Data Factory for more detail on the additional polybase options.
As a pre-requisite for Managed Identity Credentials, see the ‘Managed identities for Azure resource authentication’ section of the above article to provision Azure AD and grant the data factory full access to the database.
For more detail on verifying the access, review the following queries on Synapse DW:
select * from sys.database_scoped_credentials select * from sys.database_role_members select * from sys.database_principals
Also, when external tables, data sources, and file formats need to be created, the following queries can help with verifying that the required objects have been created:
select * from sys.external_tables select * from sys.external_data_sources select * from sys.external_file_formats
After configuring my pipeline and running it, the pipeline failed with the following error:
"ErrorCode=FailedDbOperation,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Error happened when loading data into SQL Data Warehouse.,Source=Microsoft.DataTransfer.ClientLibrary,''Type=System.Data.SqlClient.SqlException,Message=External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist - Unexpected error encountered checking whether directory exists or not: AbfsRestOperationException: Operation failed: \"This request is not authorized to perform this operation.\", 403, HEAD, https://lake.dfs.core.windows.net/lake//?upn=false&action=getAccessControl&timeout=90',Source=.Net SqlClient Data Provider,SqlErrorNumber=105019,Class=16,ErrorCode=-2146232060,State=1,Errors=[{Class=16,Number=105019,State=1,Message=External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist - Unexpected error encountered checking whether directory exists or not: AbfsRestOperationException: Operation failed: \"This request is not authorized to perform this operation.\", 403, HEAD, https://lake.dfs.core.windows.net/lake//?upn=false&action=getAccessControl&timeout=90',},],'",
After researching the error, the reason is because the original Azure Data Lake Storage linked service from source dataset DS_ADLS2_PARQUET_SNAPPY_AZVM_SYNAPSE is using Azure Key Vault to store authentication credentials, which is an un-supported managed identity authentication method at this time for using PolyBase and Copy command.
After changing the source dataset to DS_ADLS2_PARQUET_SNAPPY_AZVM_MI_SYNAPSE which no longer uses Azure Key Vault, the pipeline succeeded using the polybase copy method.

Copy command (preview)
For more detail on the copy command, read COPY (Transact-SQL) (preview).
Copy command will function similar to Polybase so the permissions needed for polybase will be more than sufficient for the copy command as well. For more information on COPY INTO, see my article on COPY INTO Azure Synapse Analytics from Azure Data Lake Store gen2. The article covers details on permissions, use cases and the SQL syntax for COPY INTO.

Similar to the Polybase copy method using Azure Key Vault, I received a slightly different error message:
ErrorCode=UserErrorSqlDWCopyCommandError,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=SQL DW Copy Command operation failed with error 'Not able to validate external location because The remote server returned an error: (403) Forbidden.',Source=Microsoft.DataTransfer.ClientLibrary,''Type=System.Data.SqlClient.SqlException,Message=Not able to validate external location because The remote server returned an error: (403) Forbidden.,Source=.Net SqlClient Data Provider,SqlErrorNumber=105215,Class=16,ErrorCode=-2146232060,State=1,Errors=[{Class=16,Number=105215,State=1,Message=Not able to validate external location because The remote server returned an error: (403) Forbidden.,},],'", "failureType": "UserError", "target": "Copy data1", "details": []
After changing to the linked service that does not use Azure Key Vault, the pipeline succeeded.

In this article, I created source Azure Data Lake Storage Gen2 datasets and a sink Azure Synapse Analytics dataset along with an Azure Data Factory pipeline driven by a parameter table to load snappy compressed parquet files into Azure Synapse using 3 copy methods: BULK INSERT, PolyBase, and Copy Command (preview).
Next Steps
- This article, Managed identity for Data Factory, helps you understand what is managed identity for Data Factory (formerly known as Managed Service Identity/MSI) and how it works.
- For recommendations and performance optimizations for loading data into Azure SQL Data Warehouse, see: Best practices for loading data into Azure SQL Data Warehouse.
- Look into another practical example of Loading Data into SQL DW using CTAS: Tutorial: Load New York Taxicab data to Azure SQL Data Warehouse.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019

