By: Aaron Bertrand | Comments (4) | Related: > TSQL
Problem
A short time ago a colleague had an issue with a Microsoft SQL Server stored procedure. They were using our recommended approach for batching updates, but there was a small problem with their code that led to the procedure "running forever." I think we’ve all made a mistake like this at one point or another; here’s how I try to avoid the situation altogether.
Solution
To start this tutorial, let's have a very simple setup - a table with 100 SKUs and their prices in the following example:
CREATE TABLE dbo.Prices
(
sku int PRIMARY KEY,
price decimal(12,2)
); INSERT dbo.Prices(sku, price)
SELECT TOP (100) ROW_NUMBER() OVER (ORDER BY @@SPID), 10
FROM sys.all_columns;
GO
Now, imagine we get a batch of 35 SKUs with new prices from some external source with the following SQL statements:
CREATE TABLE #batch
(
i int IDENTITY(1,1),
sku int,
new_price decimal(12,2)
); INSERT #batch(sku, new_price)
SELECT TOP (35) ROW_NUMBER() OVER (ORDER BY @@SPID), 20
FROM sys.all_columns;-- FROM <some_external_pricing_source>;
Our T-SQL development guidelines say to use your judgment to batch those updates n rows at a time, and let's say in this case we've decided our batch size should be 10. Hardly optimal, but this is just for the sake of a demo. The colleague's code looked like this (please DO NOT run this simple example in SSMS):
DECLARE @BatchSize int = 10, @current_row int = 1; WHILE (1=1)
BEGIN
;WITH batch AS
(
SELECT TOP (@BatchSize) sku, new_price
FROM #batch
WHERE i BETWEEN @current_row AND (@current_row + @BatchSize - 1)
)
UPDATE p SET p.price = batch.new_price
FROM dbo.Prices AS p
INNER JOIN #batch AS batch
ON p.sku = batch.sku; IF @@ROWCOUNT = 0
BREAK; SET @current_row += @BatchSize;
END
They wondered why this procedure ran forever and they had to kill it. Can you
spot it? If not, don't worry, I didn't spot it at first either. Let's
put a PRINT statement right after
BEGIN (a luxury they didn't have, to be fair,
because their application was calling the procedure):
WHILE (1=1)
BEGIN
PRINT 'Processing ' + RTRIM(@current_row) + ' - ' + RTRIM(@current_row + @BatchSize - 1);
Again, don't run this code, just trust me that it did indeed run forever, and the output was:
Processing 1 - 10 Processing 11 - 20 Processing 21 - 30 Processing 31 - 40 Processing 41 - 50 ... Processing 2021 - 2030 Processing 2031 - 2040 ... Processing 600071 - 600080 Processing 600081 - 600090 ...
Killing sessions is fun when the server is downstairs, remote admin connections are disabled, and you have pretty much brought the machine to its knees. Again, don't run the code above; do as I say, not as I do!
Anyway, the problem is right here:
INNER JOIN #batch AS batch
They'd set up a CTE to slice the new price data into multiple batches, but
then completely ignored that CTE and joined instead to the source table. Therefore,
every time through the loop, they were updating all 35 rows, and since they never
got to the "end" of the batch, the BREAK;
never tripped, and it just kept going, and going, and going...
The simple fix is to just join directly to the CTE and remove the reference to the #temp table:
INNER JOIN batch
...but did I mention...
I don't like the WHILE (1=1) pattern
Intentionally creating an infinite loop is risky, and it is all too easy to crush a server with a single misstep. This particular form is also wasteful, because you always have to perform one more iteration of the loop (which might be a lot more complex than the sample above) in order to achieve the "zero rowcount" condition.
I would much rather have something predictable, accurate, and with one less opportunity to be a footgun. This pattern isn't all that different, and certainly isn't less complex, but it has some failsafes built in to prevent any kind of infinite loop. Instead of waiting for the zero rowcount condition, I check in advance how many iterations I should expect given the batch size and the total number of rows in the table. Then the loop just increments a simple counter by 1 until it reaches the expected number. If I've miscalculated anywhere, the failsafe saves me from a true runaway query, stopping at some reasonable number of iterations (again, use your best judgment here).
DECLARE @BatchSize int = 10,
@ExpectedIterations int,
@MaxIterationsFailsafe int = 1000,
@CurrentLoop int = 1; SELECT @ExpectedIterations = (COUNT(*) - 1) / @BatchSize + 1 FROM #batch; WHILE (@CurrentLoop <= @ExpectedIterations)
BEGIN
PRINT 'Processing rows ' + RTRIM((@CurrentLoop - 1) * @BatchSize + 1)
+ ' - ' + RTRIM(@CurrentLoop * @BatchSize) + ' ...'; UPDATE p SET p.price = batch.new_price
FROM dbo.Prices AS p
INNER JOIN #batch AS batch
ON p.sku = batch.sku
AND batch.i >= (@CurrentLoop - 1) * @BatchSize + 1
AND batch.i <= (@CurrentLoop * @BatchSize); PRINT '... ' + RTRIM(@@ROWCOUNT) + ' rows affected.'; /* easily the most important section: */
IF @CurrentLoop >= @MaxIterationsFailsafe
BREAK; /* maybe raise an exception here, or after the loop */ SET @CurrentLoop += 1; /* please don't forget this one */
END
Output:
Processing rows 1 - 10 ... ... 10 rows affected. Processing rows 11 - 20 ... ... 10 rows affected. Processing rows 21 - 30 ... ... 10 rows affected. Processing rows 31 - 40 ... ... 5 rows affected.
Note that, in this case, the CTE does nothing to simplify or optimize; both plans are identical:
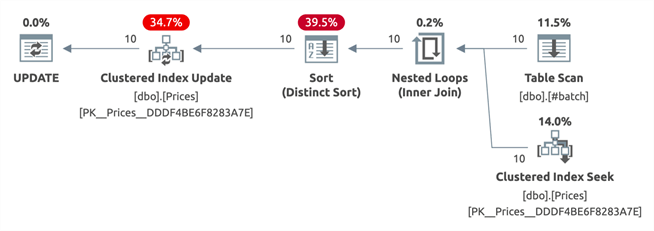
Separating filtering logic into CTEs may make the query more readable and may
have performance impact in more complex cases, though, so don't assume it isn't
worth trying or keeping that pattern. The important change here is not the UPDATE syntax; it's that we're using multiple
methods to avoid an infinite loop, while still properly handling an unknown number
of iterations.
Conclusion
Anyone can create a typo and cause an infinite loop, and usually these are easy to detect the first time you run it. Using more defensive programming approaches can at least reduce the risk of this happening in production, if not eliminate it entirely.
Next Steps
While it’s unlikely you have existing infinite loops that haven’t already been addressed, it can’t hurt to make a plan to review any batching code you have and try to implement coding conventions to avoid this type of issue for new development. In the meantime, see these tips and other resources involving loops in SQL Server:
- SQL Server Loop through Table Rows without Cursor
- Optimize Large SQL Server Insert, Update and Delete Processes by Using Batches
- Bad Habits to Kick : Thinking a WHILE loop isn't a CURSOR






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
