Problem
PAGELATCH_EX waits can be a common problem as many SQL Server database schemas use monotonically increasing columns, specifically IDENTITY typed columns, as a clustered index for their primary key. You can read more on this use case in this tip on Minimizing PAGELATCH_EX waits in SQL Server 2019. While that tip focuses on INSERT operations you could also come across similar contention on UPDATEs to other columns in your table that are monotonically increasing. A good example of this would be the rowversion SQL Server column type which many people use to track changes to rows in a table. In this tip we will look at some different options that should hopefully reduce these PAGELATCH_EX waits specifically as they relate to UPDATE statements.
Solution
At its root, the problem is basically the same as the INSERT contention issue, many concurrent processes trying to access the same page in memory. One difference with UPDATEs though, and specifically as it relates to a rowversion typed column (or any other monotonically increasing column that is indexed), is we have to ensure that any changes that we make do not have a negative impact on the processes that are retrieving the data after the fact or at least the tradeoff in performance is acceptable.
For example, let’s look at the case where we have a rowversion column tracking changes in a large table (in the following example will use a smaller table to keep things simple) and we have multiple processes updating rows in this table from different places. Similarly, there are multiple processes pulling the changes from this table at the same time. In this case there are many ways that we could reduce the contention on the last index page but at what cost to the SELECT performance. Throughout the rest of this tutorial, we will test out different options for reducing this contention and then you can decide which option is best for your particular situation.
Test Setup
To follow along with each of the below scenarios you will need to have a SQL Server 2019 (15.0.2000.5) instance running with the AdventureWorks2019 sample database installed. In addition to that you will need to add a rowversion typed column to the [Production].[ProductInventory] table which can be done with the following T-SQL.
ALTER TABLE [Production].[ProductInventory] ADD UpdVersion rowversion;
You will also need to create a lookup table which will be used as part of our stress tool that we will use to simulate UPDATE activity against our table. Here is the T-SQL to create and load that table.
SELECT [ProductID],[LocationID] INTO [AdventureWorks2019].[Production].[TipLookup]
FROM [AdventureWorks2019].[Production].[ProductInventory];
Finally, you will need to download and install the ostress tool which can be downloaded as part of the Microsoft® Database Experimentation Assistant 2.6.
Once the above steps are complete you can test out the ostress utility by running the following from a command prompt. Note: I created a SQL user with username=testuser and password=testuser but you can use any account that has the appropriate permissions in your AdventureWorks2019 database. The other settings with this utility configure it to use 200 concurrent connections each processing the query 10000 times during the stress run.
ostress -S"localhost" -Utestuser -P"testuser" -dAdventureWorks2019 -Q"UPDATE P SET Shelf=Shelf FROM [AdventureWorks2019].[Production].[ProductInventory] P INNER JOIN (SELECT TOP 1 [ProductID],[LocationID] FROM [AdventureWorks2019].[Production].[TipLookup] (NOLOCK) ORDER BY NEWID()) P2 ON P.[ProductID] = P2.[ProductID] AND P.[LocationID] = P2.[LocationID]" -n200 -r10000 -q
Once the above command is running you can check your table and make sure you are seeing updates to the rowversion column using the following T-SQL.
SELECT TOP 20 *
FROM [AdventureWorks2019].[Production].[ProductInventory]
ORDER BY [UpdVersion] DESC;
Important Note: It is important that between each call to the ostress utility that you reset the SQL Server wait statistics as these statistics are cumulative. This can be done using the following T-SQL. Before resetting the statistics, you can use the query from this link to get a summary of the wait statistics from each stress run.
DBCC SQLPERF ('sys.dm_os_wait_stats', CLEAR);
Base Case – Normal Index
In most environments (before you run into any performance issues and decide to make changes) this column that we have created to track row changes would most likely have had a normal index created on it to help with query performance. Here is the T-SQL to create this index and update the table statistics.
CREATE NONCLUSTERED INDEX [IX_ProductInventory_UpdVersion]
ON [Production].[ProductInventory] ([UpdVersion] ASC);
UPDATE STATISTICS [Production].[ProductInventory];
With this index in place, we can now run the ostress utility using the same command from the test setup section to simulate multiple concurrent sessions updating our table. In this case the utility ran for a total elapsed time of 00:11:56.346 with the following wait statistics. You can see from the chart below that we encountered quite a few PAGELATCH_EX waits trying to modify the last index page in memory for this index. We also have some other waits around this same object but for the purpose of this tip we can just focus on the PAGELATCH_EX waits.
| WaitType | Wait_S | Resource_S | Signal_S | WaitCount | Percentage | AvgWait_S | AvgRes_S | AvgSig_S |
|---|---|---|---|---|---|---|---|---|
| LATCH_SH | 39659.96 | 37839.93 | 1820.04 | 3477579 | 35.30 | 0.0114 | 0.0109 | 0.0005 |
| PAGELATCH_EX | 37509.52 | 37073.76 | 435.75 | 2953807 | 33.38 | 0.0127 | 0.0126 | 0.0001 |
| LATCH_EX | 18818.58 | 18662.97 | 155.61 | 731270 | 16.75 | 0.0257 | 0.0255 | 0.0002 |
Now that we know how our UPDATE performs let's take a look at how a query that would SELECT the last 20 rows performs (assuming the application last queried UpdVersion= 0x000000000233389F). The T-SQL for this query is below. Note: I included the FORCESEEK hint as in most cases we would be dealing with a much larger table and the index would be chosen by the optimizer, in this case it isn’t due to the size of the table. Also, in order to get the IO and TIME statistics you must run “SET STATISTICS IO ON” and “SET STATISTICS TIME ON” before running your query.
SELECT *
FROM [Production].[ProductInventory]
WHERE [UpdVersion] > 0x000000000233389F
OPTION (TABLE HINT( Production.ProductInventory, FORCESEEK));
Looking at the EXPLAIN plan output and the query time statistics we can see that querying any row changes will be very fast.

CPU time = 0 ms, elapsed time = 0 ms.
(20 rows affected)
Table ‘ProductInventory’. Scan count 1, logical reads 42, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Before we move on the first option for removing the contention, we need to remove the index that we added for this baseline test. This can be done with the following T-SQL.
DROP INDEX [Production].[ProductInventory].[IX_ProductInventory_UpdVersion];
Option 1 – Reverse Index
One option for reducing the PAGELATCH_EX contention around this hot spot is to create a reverse index on the column. Reversing the index means that we will no longer be consistently adding new entries to the end of the index as the table is updated. Instead, the updates will be spread across the entire b-tree structure. To add a reverse index, we first need to add a computed column and then we can add the index on this new column. Here is the T-SQL for both of these operations. Note: Other column types would require less conversions when reversing so keep this in mind when testing your own use cases.
ALTER TABLE [AdventureWorks2019].[Production].[ProductInventory]
ADD [UpdVersionRev] AS REVERSE(CONVERT(VARCHAR(16),CONVERT(BINARY(8),[UpdVersion]),2));
CREATE NONCLUSTERED INDEX [IX_ProductInventory_UpdVersionRev]
ON [Production].[ProductInventory] ([UpdVersionRev] ASC);
UPDATE STATISTICS [Production].[ProductInventory];
Let’s again run the ostress utility using the same command as above. In this case the utility ran for a total elapsed time of 00:05:26.212 which is a little more than twice as fast as first example. You can also see from the chart below that we now have reduced the total duration of the PAGELATCH_EX waits considerably. From ~37000s to ~3400s.
| WaitType | Wait_S | Resource_S | Signal_S | WaitCount | Percentage | AvgWait_S | AvgRes_S | AvgSig_S |
|---|---|---|---|---|---|---|---|---|
| PAGELATCH_EX | 3493.18 | 3163.08 | 330.10 | 535202 | 27.00 | 0.0065 | 0.0059 | 0.0006 |
So now that we have reduced the waits considerably let’s see how our SELECT performs. Since we are now reversing the UpdVersion column we also need to do this when we are querying the table. The T-SQL for this command is below.
SELECT *
FROM [Production].[ProductInventory]
WHERE CONVERT(BINARY(8),REVERSE([UpdVersionRev]),2) > 0x00000000014068EC;
As you can see from EXPLAIN plan and statistics this means we can no longer use the index that we had added and the optimizer needs to do a clustered index scan. Even though on this relatively small table this doesn’t have much impact on query duration, this will cause performance to become worse based on the size of the table which makes having the index almost useless.

CPU time = 0 ms, elapsed time = 1 ms.
(20 rows affected)
Table ‘ProductInventory’. Scan count 1, logical reads 15, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Before we move on to the next option let’s remove the index and computed column that we added for this test. This can be done with the following T-SQL.
DROP INDEX [Production].[ProductInventory].[IX_ProductInventory_UpdVersionRev];
ALTER TABLE [Production].[ProductInventory] DROP COLUMN [UpdVersionRev];
Option 2 – Normal Index using OPTIMIZE_FOR_SEQUENTIAL_KEY
Another option for reducing PAGELATCH_EX waits is a new in SQL Server 2019 index option called OPTIMIZE_FOR_SEQUENTIAL_KEY. This index option aims to control which threads are granted access to these latches and favor threads that will require shorter access to the latch in the hopes of increasing throughput. More detail on this can be found in the following article: Behind the scenes on optimize for sequential key. One important note to take away from the article is that you might see an increase in BTREE_INSERT_FLOW_CONTROL waits but this is expected and even with these new waits you should still see better overall throughput.
Let’s create the same index we had in our original test but this time we will add the OPTIMIZE_FOR_SEQUENTIAL_KEY option. The T-SQL to create this index is as follows.
CREATE NONCLUSTERED INDEX [IX_ProductInventory_UpdVersionOptSeqKey]
ON [Production].[ProductInventory] ([UpdVersion] ASC)
WITH (OPTIMIZE_FOR_SEQUENTIAL_KEY = ON);
UPDATE STATISTICS [Production].[ProductInventory];
After running our ostress utility again we see that this time we get a total elapsed time of 00:06:38.498. Not quite as good as the reverse index case but much better throughput than the original case which was 00:11:56.346. As mentioned in the article, if we look at the wait statistics, we do indeed see these BTREE_INSERT_FLOW_CONTROL waits now. Even though our PAGELATCH_EX wait count is similar to the original case the total wait time is way down and as already mentioned above our throughput is much better.
| WaitType | Wait_S | Resource_S | Signal_S | WaitCount | Percentage | AvgWait_S | AvgRes_S | AvgSig_S |
|---|---|---|---|---|---|---|---|---|
| BTREE_INSERT_FLOW_CONTROL | 44213.84 | 44054.22 | 159.63 | 1992472 | 67.51 | 0.0222 | 0.0221 | 0.0001 |
| PAGELATCH_EX | 5780.47 | 5392.02 | 388.46 | 2769911 | 8.83 | 0.0021 | 0.0019 | 0.0001 |
I would assume since the OPTIMIZE_FOR_SEQUENTIAL_KEY index option only effects how the index is accessed for updates that our SELECT performance should stay the same as the original case but let’s confirm this using the T-SQL below.
SELECT *
FROM [Production].[ProductInventory]
WHERE [UpdVersion] > 0x00000000017E1095
OPTION (TABLE HINT( Production.ProductInventory, FORCESEEK));
We can see from the EXPLAIN plan that this query is again using an index seek and will be very fast regardless of the table size.
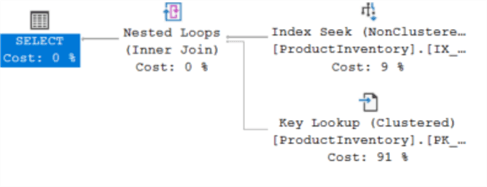
CPU time = 0 ms, elapsed time = 0 ms.
(20 rows affected)
Table ‘ProductInventory’. Scan count 1, logical reads 42, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Before we move on to our final option let’s remove the index that we added for this test. This can be done with the following T-SQL.
DROP INDEX [Production].[ProductInventory].[IX_ProductInventory_UpdVersionOptSeqKey];
Option 3 – Sharded Index
For our final option we will test an idea that is popular in distributed database systems and create a sharded index to try to reduce the contention. There are two options when implementing this option. First you can create a dummy column by which you will shard the index or in this case, since we already have the [LocationID] column in the table, we can just use that to create our sharded index. Here is the T-SQL to create this index and update the table statistics.
CREATE NONCLUSTERED INDEX [IX_ProductInventory_UpdVersionShard]
ON [Production].[ProductInventory] ([LocationID] ASC, [UpdVersion] ASC)
UPDATE STATISTICS [Production].[ProductInventory];
After running the ostress utility for this last option we see a total elapsed time of 00:05:43.240 which is right between options 1 and 2. Looking at the wait statistics below though we do still see PAGELATCH_EX waits but although they are high, they are most likely spread out across the index structure due to the sharding so we still see really good overall throughput.
| WaitType | Wait_S | Resource_S | Signal_S | WaitCount | Percentage | AvgWait_S | AvgRes_S | AvgSig_S |
|---|---|---|---|---|---|---|---|---|
| PAGELATCH_EX | 34362.75 | 33603.33 | 759.43 | 2382839 | 63.63 | 0.0144 | 0.0141 | 0.0003 |
| LCK_M_U | 10145.36 | 10081.81 | 63.55 | 242085 | 18.79 | 0.0419 | 0.0416 | 0.0003 |
For this case our SELECT query will also have to change slightly since, for the index to be used, we will have to include the [LocationID] column in the WHERE clause. If using a dummy column, you could actually be a bit smarter about passing a value for the column but in this case we will just add a greater than zero condition and use an index hint to force the optimizer to use our index.
SELECT *
FROM [Production].[ProductInventory]
WHERE [LocationID] > 0 AND [UpdVersion] > 0x0000000001D74F27
OPTION (TABLE HINT( Production.ProductInventory, FORCESEEK));
If we look at the EXPLAIN plan and query timing we can see that this query using the sharded index performs pretty much the same as our original use case.

CPU time = 0 ms, elapsed time = 0 ms.
(20 rows affected)
Table ‘ProductInventory’. Scan count 1, logical reads 49, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
As we did for our other test cases let’s remove this index, we added so we leave the schema in the same state it was before we started. We can also drop the column that we added in the setup section. Here is the T-SQL required to do these steps.
DROP INDEX [Production].[ProductInventory].[IX_ProductInventory_UpdVersionShard];
ALTER TABLE [Production].[ProductInventory] DROP COLUMN UpdVersion;
Summary
Looking at each of the options above we can see that each option does provide benefits with respect to the PAGELATCH_EX waits but also could have some drawbacks in either performance or complexity or version in which the option is available. The table below tries to summarize these options and make it easier to choose what would be most appropriate for your particular use case.
| Option | Duration | PAGELATCH_EX waits (count / duration) | SELECT performance effected | Requires schema change | SQL Version |
|---|---|---|---|---|---|
| Base | 00:11:56.346 | 37509.52 / 2953807 | No | No | All |
| 1 | 00:05:26.212 | 3493.18 / 535202 | Yes | Yes | 2008 |
| 2 | 00:06:38.498 | 5780.47 / 2769911 | No | Yes *just index option | 2019 |
| 3 | 00:05:43.240 | 34362.75 / 2382839 | No | Yes | All |
Next Steps
- Read more tips on locking and latches
- Read more on Minimizing PAGELATCH_EX waits in SQL Server 2019

Ben Snaidero has been a Database Administrator for just over 10 years. Starting out working mainly with Oracle he got into SQL Server in 2005 and has worked primarily with SQL Server for the last 3 years. His main focus with both Oracle and SQL Server is in the area of performance tuning.
- MSSQLTips Awards: Achiever (75+ tips) – 2018 | Author of the Year Contender – 2016-2017


