Problem
A few years ago, I used a natively compiled stored procedure to fetch data from a memory-optimized table in a production environment. I thought natively compiled modules were faster than traditional ones for fetching records from a table. After a few days, I realized the procedure was not fast enough. I compared the natively compiled stored procedure to a traditional one and found that it is not faster. Why? I will explain in this article.
Solution
First, I would like to explain the advantages of the native compiled modules. According to Microsoft documentation, a natively compiled stored procedure is a way to access data and execute queries more quickly than traditional T-SQL. Since T-SQL is a CPU-expensive programming language and a simple query requires many CPU instructions to execute, Microsoft introduced natively compiled modules to reduce this overhead. When we create a natively compiled stored procedure, SQL Server converts the access logic into C code and stores it in a DLL. Native CPU instructions are instructions that the CPU can run without any interpretation. The main overhead of traditional T-SQL is related to interpretation. So, theoretically, a natively compiled stored procedure is faster than the traditional one. However, it wasn’ faster in my case. There are two key points to know:
- The only supported join type in natively compiled stored procedures is the nested loop.
- Natively compiled code does not support parallelism and always has serial execution plans.
A serial execution plan and a nested loop join operator are suitable for retrieving data from a small OLTP system. One of the main features of OLTP systems is their small size. While using the above two features in a natively compiled stored procedure seems efficient, these days, many OLTP systems store large numbers of records, say 50 million records per day. It is worth noting that, in an OLTP system, we usually do not run complex queries. But, sometimes, you need to run a complex query in an OLTP system. In some situations, running queries in a parallel execution mode can speed up the data extraction process from an OLTP system. To demonstrate, I will set up a few tests to compare the execution plan of two types of stored procedures.
Set Up Test Environment
I will use the AdventureWorks database and add an in-memory optimized filegroup.
Use master
GO
Alter Database AdventureWorks2019 ADD Filegroup FG_Inmom Contains Memory_Optimized_Data
Alter Database AdventureWorks2019 ADD File (Name = F_Inmom, FileName = N'D:\Data\F_Inmom') To FileGroup FG_Inmom<br />GO
The following command alters the database compatibility level to 160 (SQL Server 2022):
Alter Database AdventureWorks2019 Set Compatibility_Level = 160
GO
I will create two memory-optimized tables and populate them with a set of data:
Drop Table If Exists [dbo].[SalesOrderHeader_InMemory]
Drop Table If Exists [dbo].[SalesOrderDetail_InMemory]
GO
CREATE TABLE [dbo].[SalesOrderHeader_InMemory]
(
[SalesOrderID] [int] NOT NULL,
[CustomerID] [int] NOT NULL,
[TaxAmt] [money] NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DueDate] [datetime] NOT NULL,
[Freight] [money] NOT NULL,
[SubTotal] [money] NOT NULL,
CONSTRAINT [PK_SalesOrderHeader_InMemory] PRIMARY KEY NonClustered
(
[SalesOrderID] ASC
)
) With (Memory_optimized = On, Durability = Schema_and_data)
GO
CREATE TABLE [dbo].[SalesOrderDetail_InMemory]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[ProductID] [int] NOT NULL,
[OrderQty] [smallint] NOT NULL,
CONSTRAINT [PK_SalesOrderDetail_InMemory] PRIMARY KEY NONCLUSTERED
(
[SalesOrderID] ASC,
[SalesOrderDetailID] ASC
)
) WITH (Memory_optimized = On, Durability = Schema_and_data)
GO
Insert Into [dbo].[SalesOrderHeader_InMemory]
Select
[SalesOrderID],
[CustomerID],
[TaxAmt],
[OrderDate],
[DueDate],
[Freight],
[SubTotal]
From sales.SalesOrderHeader
GO
Insert Into [dbo].[SalesOrderDetail_InMemory]
Select
[SalesOrderID],
[SalesOrderDetailID],
[UnitPrice],
[ProductID],
[OrderQty]
From sales.SalesOrderDetail
GO
I will create two stored procedures: one natively compiled and one traditional.
CREATE Or Alter PROCEDURE USP_NativeCompile
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english'
)
Select soh.SalesOrderID,
soh.CustomerID,
soh.OrderDate,
soh.DueDate,
soh.Freight,
sod.UnitPrice,
soh.SubTotal,
soh.TaxAmt
From dbo.SalesOrderHeader_InMemory soh
Inner Join dbo.SalesOrderDetail_InMemory sod
On sod.SalesOrderID = soh.SalesOrderID
Order By UnitPrice Desc
END
GO
Create Or Alter Procedure USP_Regular
AS
Select soh.SalesOrderID,
soh.CustomerID,
soh.OrderDate,
soh.DueDate,
soh.Freight,
sod.UnitPrice,
soh.SubTotal,
soh.TaxAmt
From SalesOrderHeader_InMemory soh
Inner Join SalesOrderDetail_InMemory sod
On sod.SalesOrderID = soh.SalesOrderID
Order By UnitPrice Desc
GO
To view the actual execution plan, press Ctrl + M and then execute the following procedure:
Exec USP_NativeCompile
GO
As illustrated in the image below, the natively compiled stored procedure was executed in serial mode, and there is no parallelism icon in the execution plan. Adding an ORDER BY clause to our query caused the execution plan to include a sort operator. This is expensive, so running the query in parallel may be faster. You can see the query execution time on the computed scalar operator, which is 865 milliseconds.
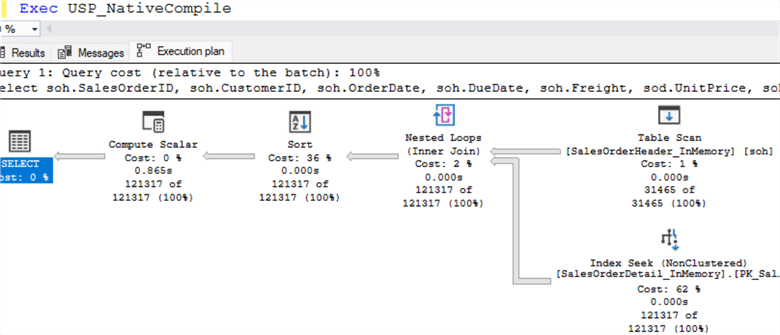
The image below (zoomed in section of above image) illustrates that SQL Server utilized a nested loop join operator:

The query optimizer scanned the ‘SalesOrderHeader’ table, which has nearly 31,000 records. Also, it used a non-clustered index seek operator to fetch data from the ‘SalesOrderDetail’ table that retrieves almost 121,000 records. The query optimizer used a nested loop join operator to find matching records.
Next, you will see that the query optimizer uses the hash match operator and executes the query in parallel execution mode when we use a traditional stored procedure to fetch data from memory-optimized tables. I will execute the traditional procedure:
Exec USP_Regular
GO
Take note of the parallelism operator highlighted in the execution plan:

You can see the time on the parallelism icon is 199 milliseconds.
The following image shows that SQL Server used eight logical CPU cores to run the procedure:

The image below (part of the above execution plan) illustrates the utilization of a hash match join operator by SQL Server. The optimizer found that using a hash match is faster than a nested loop in our scenario.

Summary
Microsoft says that a natively compiled stored procedure is a quicker way to access data and is more efficient at executing queries than interpreting (traditional) T-SQL. However, there are cases where they may experience slower execution times. This article compares the actual execution plans for a natively compiled and a traditional procedure to help readers choose between these two procedures. In conclusion, every choice must be tested and measured beforehand.
Next Steps
- SQL Server In Memory OLTP Tips
- SQL Server Stored Procedure Native Compilation Advisor
- Migrate to Natively Compiled SQL Server Stored Procedures for Hekaton

Mehdi Ghapanvari is an SQL Server database administrator with 6+ years of experience. His main area of expertise is improving database performance. He is skilled at managing high-performance servers that can handle several terabytes of data and hundreds of queries per second, ensuring their availability and reliability. To enhance the performance of the database, he has implemented various performance-tuning techniques, including query optimization and index tuning. He has also developed backup and recovery strategies to protect critical data in case of disasters. Mehdi currently manages the SQL Server databases for a large organization. Mehdi is actively seeking new opportunities to apply his expertise and contribute to impactful projects. You can reach him at SQLDBA.Mehdi@Gmail.com.
- MSSQLTips Awards: Rookie of the Year – 2023
- MSSQLTips Trendsetter Award: 2026


