Problem
A previous tip discussed how to deploy changes to Azure SQL database using GitHub Actions and the basic aspects of integrating database object creation into CI/CD pipelines with sql-action.
This tip will demonstrate more complex scenarios and best practices for automating SQL deployments.
Solution
As discussed in Part 1, we used GitHub Actions to trigger events after a commit to one, many, or all branches in the repository. This tip goes a step further to show more advanced scenarios, as well as an introduction to post-deployment scripts.
For prerequisites and how to set up a GitHub Action with sql-action, please see the previous tip in this series.
Setting Up the Environment
We will use the same GitHub repository from the previous tip:

This already has some .sql files we can use and a database project file. We will also be using the same Azure SQL Database for the examples.
Specify Files/Folders for the Action to Trigger
Most real-world repositories have code for multiple sections of your architecture, such as individual folders for the frontend, backend, IaC, and database objects.
How can we trigger the action only when files are added to a specific folder, like dbobjects?
First, let’s make some changes to the repository. Create other folders to have everything organized, then move everything to the dbobjects folder:

The next step is to locate the action file github\workflows\sql-workflow.yml.
Update the file content with the following:
on:
push:
paths:
- 'Dbobjects/**'
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: azure/sql-action@v2.2.1
with:
connection-string: ${{ secrets.AZURE_SQL_CONNECTION_STRING }}
path: './Dbobjects/Database.sqlproj'
action: 'publish'
Explaining the Changes
- At the top of the code, we add the paths: configuration and specify the folder path where we want the action to trigger if there is any commit that involves files on that location.
- We update the database project file location so the changes can be properly tracked.

Now, let’s try to make sure it works as expected.
First, we try a commit in the Dbobjects folder. Add a new table:

If we check the actions, we can see that it triggers properly:

The log says that the table (among other pending changes we have) was created successfully:

And the object is properly created:

Now, let’s try to commit a file outside the folder; the action must not trigger this time:

We perform the commit and push:

When we check the job logs, we can see that no sql actions were triggered:
Other T-SQL Commands
We have given examples of adding tables and updating columns, but what happens with more complex changes? Let’s discuss a few examples.
Users and Logins
If we create logins, since Azure SQL database logins can only be created from the MASTER database, and USE db is not allowed, you must first create the login manually and then include the create statement again in the file so it can be properly tracked by the database project.
Note: This is just an example. You should never store plaintext passwords in your code. It is preferred to use AD logins or secrets to store passwords.

We can see that the user is properly created. Notice that even when we included the CREATE LOGIN command, it was never executed; it is only included so the database project can detect it and create the user.

What if we add a role to that user? We add it to the end. Remember that for multiple statements, you must include the GO reserved word after each sentence.

If we check the action log, we see that the role was granted to the user:

Additional Table Commands
It is possible to add/update/remove indexes, constraints, statistics, and additional settings to a table. It can be added to the same file that creates the table. At the end, it needs to include GO after each sentence.
For this example, we will add data row compression and a non-clustered index:
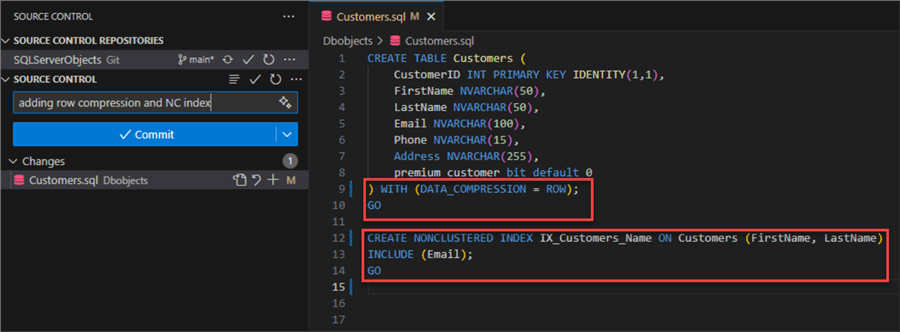
If we check the log, the table is altered even when specifying only the CREATE TABLE command.

And do not worry; no drop command was issued, so we never lose any data:

What if we want to drop the index or remove the compression? Just comment it out or remove the code for it:

Changes were dropped, and we can validate that no data was lost.

Table Relationship
This depends on the order in which the objects were created, usually in alphabetical order, so we can end up with errors where the object still does not exist. Please keep this in mind when creating references, or you can add them after the initial tables have been created using post-deployment scripts, as we will see in the next example.

When the relationships are created, remember that deployment could fail if the table still does not exist while other referenced tables are not yet created.

DML Operations
We have to use post-deployment scripts to modify the .sqlproj file and add this code after the PropertyGroup tag:
<ItemGroup>
<PostDeploy Include="Script.PostDeployment.sql" />
</ItemGroup>
The Script.PostDeployment.sql is the file for post-deployment operations, the .sqlproj file should look like this:

Then, we can specify DML commands, cleanup scripts, or any other business logic we need to run after deployment:

The log does not show the execution log for this script, so we must manually check the table:

Notice that this script executes every time a deployment is made. So, if you do not want duplicate records, you must add some validations to make sure the data does not exist on the table or truncate the table first, making sure the records you specify are added every time.
Next Steps
- GitHub Actions documentation.
- You can check sql-action repo and documentation.
- You can read the documentation on how sql projects actually work and how we can optimize scripts so we don’t lose valuable data.
- This action can work with other actions configured on your repository to allow chaining multiple action files, such as validations or IaC deployments.

Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years of experience working in large environments.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2019 | Rookie of the Year – 2018
