Overview
Writing SELECT statements is exactly the same in Snowflake as in any other database. In fact, if you have been writing T-SQL for some time you’ll have no problems adjusting to the SQL dialect of Snowflake, since they have much overlap and you will be able to query Snowflake data quickly.
Explanation
In this part of the tutorial, I use the StackOverflow sample database, which can be downloaded as XML files. The advantage is the size of the database is big enough to run some heavy queries and the data itself is realistic. If you’re interested, there are back-ups specific for SQL Server.
Query Snowflake Data
Let’s start with this query:
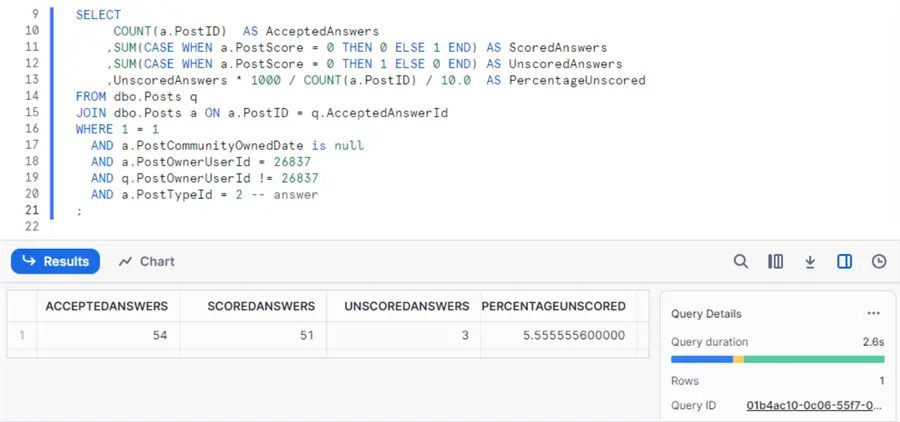
SELECT
COUNT(a.PostID) AS AcceptedAnswers
,SUM(CASE WHEN a.PostScore = 0 THEN 0 ELSE 1 END) AS ScoredAnswers
,SUM(CASE WHEN a.PostScore = 0 THEN 1 ELSE 0 END) AS UnscoredAnswers
,UnscoredAnswers * 1000 / COUNT(a.PostID) / 10.0 AS PercentageUnscored
FROM dbo.Posts q
JOIN dbo.Posts a ON a.PostID = q.AcceptedAnswerId
WHERE 1 = 1
AND a.PostCommunityOwnedDate is null
AND a.PostOwnerUserId = 26837
AND q.PostOwnerUserId != 26837
AND a.PostTypeId = 2 -- answer
;The Posts table holds about 41 million rows and is 20GB in size. On an extra small warehouse (make sure to read the part of the tutorial about warehouses) this query runs for about 3 to 4 seconds.
Scale Warehouse Size
Now let’s scale the warehouse up to size medium.
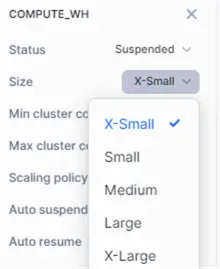
Scaling the warehouse takes a couple of seconds. Now, before we run our query again, we need to disable caching, which can be done with the following statement:
ALTER SESSION SET USE_CACHED_RESULT = FALSE;When we run the same query again, we can see the results are returned significantly faster (typically around 0.5 to 1.5 seconds):

Scaling Snowflake Warehouses
This brings us the one of the main advantages of Snowflake: scaling warehouses is super-fast and transparent for the end user. A bigger warehouse will finish queries faster than smaller warehouses most of the time. The reverse correlation between warehouse size and query duration is not 100% linear, but generally you can expect that if you double the warehouse size, the execution time is roughly halved. Of course, this stops at some point in time, there will always be some bottleneck, like I/O for example, that cannot be mitigated by just throwing more processing power at it.
The great part of having a faster query because of a bigger warehouse is that you pay about the same amount of money. Suppose you have a long running query of 10 minutes in a small warehouse (2 credits per hour). This means you pay 10/60 * 2 credits or ⅓ of a credit. Suppose you run the same query on a medium warehouse (4 credits per hour) and the query finishes in 5 minutes. The calculation now becomes: 5/60 * 4 credits, which is again ⅓ of a credit!
It makes sense to test out how big of a warehouse you’ll use to run your data pipelines. You can scale up and your queries go faster, meaning your ETL window gets smaller for the same amount of money. At some point this trend will stop and you will have found your optimal warehouse size. Keep in mind you pay for the amount of time a warehouse is running, not for the number of queries, so take advantage of parallelism as much as you can.
Performance Tuning
Performance is great out of the box, but if a query is still slow, you do not have many options unfortunately. There are no indexes you can create on a table. Your options are:
- Scale up the warehouse. If it doesn’t help, you need to resort to one of the other options.
- Re-write your query. Maybe you did an inefficient join or perhaps you can use window functions to speed things up.
- Split up the query in multiple parts and store each intermediate result in a (temporary) table. This is sometimes the only option if the query plan becomes too complex for Snowflake to handle.
- You can also change the clustering of a table. Typically used for larger tables (over 1 TB) but it might also help for smaller tables. This option should be your last resort.
Additional Information
- If you don’t have the Stack Overflow database, you can write your own query on the provided sample databases in Snowflake. The tables in the TPCH_SF1000 schema in the Snowflake_Sample_Database database are up to 160GB in size, so you can use those for performance testing.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025