By: Aaron Bertrand | Comments (7) | Related: > Query Plans
Problem
In some shops developers are quite inconsistent in how they write their T-SQL. Formatting styles differ, from whitespace and indenting, to upper- or lower-case keywords, to the use of schema and properly cased object and column names. When dealing with ad hoc SQL, since entries in the plan cache are case- and whitespace-sensitive, these inconsistencies can be quite problematic, leading to inefficient use of the plan cache (sometimes referred to as "plan cache bloat"). Check out this tip to minimize the SQL Server plan cache bloat.
Solution
There are a few things that you can do to minimize plan cache bloat. But first let's show a few examples where slight differences in queries can lead to multiple versions of the plan for what is essentially the exact same query. First let's set up a database with a couple of user objects, and a login with a default schema other than dbo:
USE [master]; GO CREATE LOGIN login_a WITH password = 'a', CHECK_POLICY = OFF; GO CREATE DATABASE CacheTest; GO USE CacheTest; GO CREATE SCHEMA schema_a AUTHORIZATION dbo; GO CREATE USER user_a FROM LOGIN login_a WITH DEFAULT_SCHEMA = schema_a; GO GRANT SELECT ON SCHEMA::dbo TO user_a; GO SELECT * INTO dbo.columns FROM sys.all_columns; ALTER TABLE dbo.columns ADD CONSTRAINT PK_c PRIMARY KEY([object_id], [column_id]); SELECT * INTO dbo.objects FROM sys.all_objects; ALTER TABLE dbo.objects ADD CONSTRAINT PK_o PRIMARY KEY([object_id]); GO
Now, let's run a few queries against our user objects. We'll change up the spacing and case, and make sure to leave the schema prefix off for one query. Note that I am using comments and batch separators to clarify how these queries are different and to ensure that they are considered separately by the engine:
-- standard join query with 2-space indents: GO SELECT o.name FROM dbo.columnlist AS c INNER JOIN dbo.objectlist AS o ON c.[object_id] = o.[object_id]; GO -- this one is identical but leaves out schema prefix: GO SELECT o.name FROM columnlist AS c INNER JOIN objectlist AS o ON c.[object_id] = o.[object_id]; GO -- this one uses tabs instead of two-space indents: GO SELECT o.name FROM dbo.columnlist AS c INNER JOIN dbo.objectlist AS o ON c.[object_id] = o.[object_id]; GO -- this one uses lower-case for all keywords: GO select o.name from dbo.columnlist as c inner join dbo.objectlist as o on c.[object_id] = o.[object_id]; GO -- and this one uses different case for the object names: GO SELECT o.name FROM dbo.ColumnList AS c INNER JOIN dbo.ObjectList AS o ON c.[object_id] = o.[object_id]; GO
Now, if we check the plans that have been collected using sys.dm_exec_cached_plans:
SELECT
p.plan_handle,
p.cacheobjtype,
bucket = p.bucketid,
used = p.usecounts,
b = size_in_bytes,
t.[text]
FROM sys.dm_exec_cached_plans AS p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t
WHERE t.[dbid] = DB_ID('CacheTest')
AND t.[text] NOT LIKE '%cached_plans%' -- to prevent this query from showing up
AND t.[text] LIKE '%list%';
We can see that there are 5 different entries, each stored in their own bucket, and each taking up just under 50kb in the plan cache:

Further to this, if we connect to the database using the login login_a, and run the query without the explicit schema references:
-- run this as login_a, whose user_a has a different default schema: GO SELECT o.name FROM columnlist AS c INNER JOIN objectlist AS o ON c.[object_id] = o.[object_id]; GO
Then run our query against dm_exec_cached_plans again, we have another plan that has been cached:
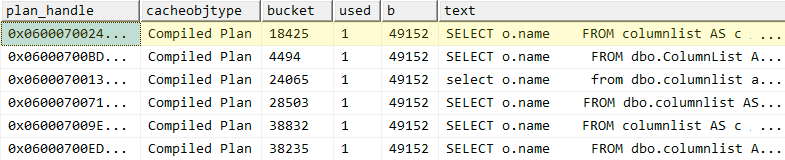
On a busy system, this can mean that some of these plans might get pushed out of the cache, and have to be recompiled - even though a perfectly valid plan already exists. For plans that end up only being used once, you can offset this significantly by using the Optimize for Ad Hoc Workloads setting. In this case the plan won't be fully cached until the exact same batch is executed a second time. So testing that option and clearing the buffers/cache:
EXEC sp_configure 'show advanced options', 1; RECONFIGURE WITH OVERRIDE; EXEC sp_configure 'optimize for ad hoc workloads', 1; RECONFIGURE WITH OVERRIDE; EXEC sp_configure 'show advanced options', 0; RECONFIGURE WITH OVERRIDE; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS;
If you run the first set of five queries again, the output of the query against sys.dm_exec_cached_plans will be slightly different:

Notice that we no longer have a Compiled Plan but rather a Compiled Plan Stub, and that the size it takes to represent this stub in the plan cache is much smaller. If you run the queries again, the results will be similar to above. But you will still see these different queries yielding different plans.
On the plus side, SQL Server 2008 added the use of a query plan hash. This makes it possible to identify when you have the same query that is being represented by different plans, and should show an opportunity to consolidate those plans by re-writing them at their source (or eliminating almost duplicate queries by creating a view or stored procedure). You can identify different plans with the same query plan hash using the following query:
;WITH h AS
(
SELECT query_plan_hash
FROM sys.dm_exec_query_stats
GROUP BY query_plan_hash
HAVING COUNT(*) > 1
)
SELECT t.[text],p.plan_handle
FROM h INNER JOIN sys.dm_exec_query_stats AS s
ON s.query_plan_hash = h.query_plan_hash
INNER JOIN sys.dm_exec_cached_plans AS p
ON s.plan_handle = p.plan_handle
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t
WHERE t.[dbid] = DB_ID('your_db_name');
Conclusion
If you have different people contributing T-SQL queries to your codebase, encourage coding practices that will minimize plan cache usage, such as:
- use consistent indenting, carriage returns and spacing
- use consistent case for keywords
- use the correct case for object and column names (let IntelliSense do this work for you)
- always include the schema when referencing objects
- centralize code in stored procedures or views to avoid having different versions of the same query
Next Steps
- Review your plan cache to see if you have a high number of similar queries taking up the cache
- Implement and follow coding conventions
- Consolidate your ad hoc SQL into views or stored procedures
- Review the following tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
