By: Arshad Ali | Comments (10) | Related: > In Memory OLTP
Problem
Microsoft is releasing SQL Server 2014 with a new set of In-Memory OLTP features to significantly improve the OLTP performance and reduce the processing time for servers with a large amount of memory and multi-core processors. But how is this functionality different from the DBCC PINTABLE command? What are the design principles for this feature? How does the data get stored in this new type of table? How is In-Memory OLTP different from the existing SQL Server disk based tables? How does it all work? Check out this tip to learn more.
Solution
In-Memory OLTP is a new feature in SQL Server 2014 which significantly improves the OLTP workload and reduces the time required for processing. The project code name of this feature is Hekaton (a Greek word) which means hundred or hundredfold; although this new feature does not improve performance to that extent, it improves overall performance significantly. The performance gains depend on the hardware infrastructure you have and how you are writing your queries. With this feature, SQL Server 2014 is well positioned to take full advantage of the changing hardware trends and modern application requirements.
SQL Server was traditionally designed to have data stored on disk for persistence and bring data in memory when needed for serving query requests. The main reason for this architecture was to minimize the requirement for main memory, because it was traditionally quite expensive. Now with the declining hardware prices we can buy servers with much more memory and multi core CPUs. The core objective of this new feature to is utilize the changing hardware trends. Based on early results, Hekaton utilizes today's hardware and improves the performance several fold in comparison to traditional disk based tables.
The In-memory OLTP features are a new database engine component, which is fully integrated into SQL Server and runs side by side with the traditional database engine. It allows you to declare a table to be stored in main memory (i.e. memory optimized table) so that your OLTP workload can access this memory resident data faster.
For memory optimized tables, all the data is already stored in the memory and unlike disk based tables. With Hekaton pages don't need to be brought into buffer pool or cache. For data persistence of these memory optimized tables, this new engine creates a set of checkpoint files on the filestream filegroup that keeps track of changes to the data in an append only mode and uses it during recovery\restore processes.
Are SQL Server 2014 memory optimized tables the same as the DBCC PINTABLE command?
There is a myth that In-memory OLTP and DBCC PINTABLE are same feature, but there is no truth in this statement. These are two different features and are based on two different architectures. DBCC PINTABLE is now a deprecated feature of SQL Server because of its potential highly unwanted side-effects.
When you marked a table to be pinned using the DBCC PINTABLE command, SQL Server didn't flush the pages brought into memory of that table, because they were marked as pinned pages. When new pages needed to be read, SQL Server would use more memory to accommodate the request. The side-effect of this architecture, with a large table, is that it could fill up the entire buffer cache and not leave enough cache to serve other requests adequately. Further, even with pinned tables, there was a cost of bringing the pages into memory the first time when referenced, which was no different than any other disk based table for the first read. Pinned tables also required the same level of latching, locking and logging with the same index structures as traditional disk based tables.
Conversely, the In-memory OLTP architecture is a separate component of the database engine which allows you to create memory optimized tables. These memory optimized tables have a completely different data and index structure. No locking or latching is required when you access these tables, hence the minimal waiting time due to no locking or blocking. Also, there are no data pages, index pages or buffer pool for memory optimized tables. Data for the memory optimized table gets stored in the memory in a completely different structure, please refer to the next section of this tip to understand this new row structure.
SQL Server 2014 In-Memory OLTP High Level Architecture
The SQL Server Development team had four architectural design principles for In-Memory OLTP tables:
- Built-in to SQL Server for a hybrid and integrated experience - The idea behind this principal was to integrate the In-memory OLTP engine in the main SQL Server engine. Users will have an hybrid architecture combining the best of both of architectures allowing users to create both traditional disk based tables as well as the newly introduced memory optimized tables in the same database. This integrated approach gives users the same manageability, administration and development experience. Further it allows for the writing of integrated queries combining both disk based tables as well as memory optimized tables. Finally the integration allows users to have integrated high availability (i.e. AlwaysOn) and backup\restore options.
- Optimize for main memory data access - As we are witnessing the steady decline in memory prices, the second principal was to leverage large amounts of memory as much as possible. By storing data and index structure of the memory optimized tables in memory only, the memory optimized tables don't use the buffer pool or B-tree structure for indexes. This new architecture uses stream based storage for data persistence on disk.
- Accelerate business logic processing - The idea behind this principal is to compile T-SQL to machine\native code via a C code generator and use aggressive optimization during compile time with the Microsoft's Visual C/C++ compiler. Once compiled, invoking a procedure is just a DDL entry-point and it achieves much of the performance by executing compiled stored procedures. Remember, the cost of interpreted T-SQL stored procedures and their query plans is also quite significant. For an OLTP workload the primary goal is to support efficient execution of compile-once-and-execute-many-times workloads as opposed to optimizing the execution of ad hoc queries.
- Provide frictionless scale-up - The idea behind this principal was to provide high concurrency to support a multi-user environment without blocking (remember blocking implies context switches which are very expensive) and better utilize the multi-core processors. Memory optimized tables use multiversion optimistic concurrency control with full ACID support and it does not require a lock manager because it uses a lock\latch\spinlock free algorithm. This principle is based around optimistic concurrency control where the engine is optimized around transactions that don't conflict with each other. Multi-versioning eliminates many potential conflicts between transactions and the rest (and very few of them) are handled by rolling back one of the conflicting transactions rather than blocking.
If you look at the below architecture, you will notice there are certain areas which remain same for accessing memory optimized tables vs. disk based tables. For example the client connects to the TDS handler and Session Management module irrespective of whether he\she wants to access a memory optimized table or disk based table. The same is true when call a natively compiled stored procedures or interpreted T-SQL stored procedure. And then there are certain changes about how memory optimized tables are created, stored, managed and accessed. Further, Query Interop allows interpreted T-SQL queries and stored procedures to access memory optimized tables.
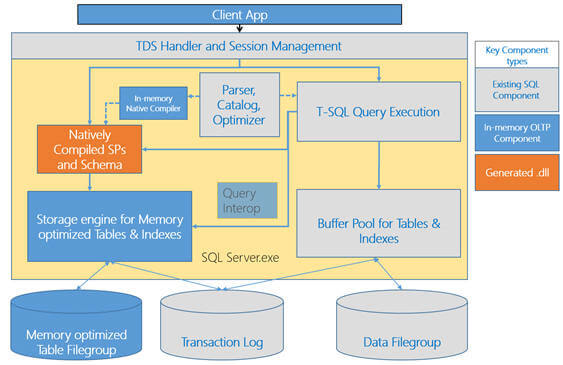
The In-memory native compiler takes an abstract tree representation of a T-SQL stored procedure defined as a native stored procedure. This representation includes the queries within the stored procedure, in addition to the table and index metadata then compiles the procedure into native\machine code. This code is designed to execute against tables and indexes managed by the storage engine for memory optimized tables.
The In-memory storage engine manages user data and indexes of the memory optimized tables. It provides transactional operations on tables of records, hash and range indexes on the tables, and base mechanisms for storage, check pointing, recovery and high-availability. For a durable (more on durability in next part of this tip series) table, it writes data to filestream based filegroup on disk so that it can recover in case a server crashes. It also logs its updates to the SQL Server database transaction log along with the log records for disk based tables. It uses SQL Server file streams for storing checkpoint files which are used, to recover memory optimized tables automatically when a database is recovered or restored.
Other than these items, as I said In-memory OLTP is fully integrated into the existing SQL Server database engine. Hekaton leverages a number of services already available in SQL Server, for example:
- Meta data about memory optimized tables are stored in the SQL Server catalogs
- A transaction can access and update data in both memory optimized and disk based tables
- If you have setup a AlwaysOn availability group then memory optimized tables will fail over in the same manner as disk based tables
SQL Server 2014 Data Storage
Memory optimized tables have a completely new row format for storage of row data in memory and the structure of the row is optimized for memory residency and access. Unlike, disk based tables for which data gets stored in the data or index pages, memory optimized tables do not have any page containers. As I said before, In-memory OLTP uses multi-version for data changes, which means the payload does not get updated in place, but rather rows are versioned on each data change.

With Hekaton, every row has a begin timestamp and an end timestamp, which determines the row's version, validity and visibility. The begin timestamp indicates the transaction that inserted the row whereas the end timestamp indicates the transaction which actually deleted the row. A value of infinity for the end timestamp indicates the row has not been deleted and it is the latest version. Updating a row is a combination of deleting an existing record and inserting a new record. For a read operation - only record versions whose valid time overlaps the read time will be visible to the read, all other versions are ignored. Different version of the record will always have non-overlapping time validity and hence at most only one version of the record will be visible to the read operation. Having said that, the begin timestamp and end timestamp values determine, which other transactions will be able to see this row.
As I said, In-memory OLTP uses multi-version for concurrency, it means for a given row there could be many versioned rows depending how many times the particular record gets updated. The In-memory OLTP engine has a background, non-blocking, co-operative, garbage collection system which removes versions of a record which are no longer visible to any active transaction. This is important to avoid filling up memory.
Keep in mind, all the memory optimized tables are fully stored in memory and hence you need to make sure you have enough memory available. One recommendation is 2 times the data size. You will also need to verify you have enough memory for buffer pools for your disk based tables. If you don't have enough memory then your transactions will start failing or if you are recovering\restoring, this operation will fail if you don't have enough space to accommodate all the data of the memory optimized tables. Please note, you don't need physical memory to accommodate the entire database, which could be in terabytes, but you need to accommodate all your memory optimized tables, which should not be more than 256 GB in size.
Next Steps
- Review the following resources:
- Architectural Overview of SQL Server 2014's In-Memory OLTP Technology blog.
- Hekaton: SQL Server's Memory-Optimized OLTP Engine research paper.
- Kalen Delaney's white paper on In-memory OLTP.
- Overcoming storage speed limitations with Memory-Optimized Tables for SQL Server
- Workaround for lack of support for constraints on SQL Server Memory-Optimized Tables
- Migrate to Natively Compiled SQL Server Stored Procedures for Hekaton
- Updating statistics for Memory-Optimized tables in SQL Server
- My previous tips






About the author
 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
