Problem
In-Memory OLTP is a new feature in SQL Server 2014 for OLTP workloads to significantly improve performance and reduce processing time when you have a plentiful amount of memory and numerous multi-core processors. But how does someone get started using this feature? What changes need to be made in the database or what scripts need to be run to create memory optimized tables? Also, what are some of the considerations for migration? Check out this tip to learn more.
Solution
In this tip series, I have covered In-Memory OLTP which is a new feature in SQL Server 2014 for OLTP workloads to improve performance. In this tip, I am going to provide scripts and demos to get started with this new feature.
Also, please refer to my previous tips for additional information about this new feature.
- Getting started with the AMR tool for migration to SQL Server In-memory OLTP Tables
- Overview of Applications, Indexes and Limitations for SQL Server 2014 In-Memory OLTP Tables
- SQL Server 2014 In Memory OLTP Durability, Natively Compiled Stored Procedures and Transaction Isolation Level
- SQL Server 2014 In-Memory OLTP Architecture and Data Storage
Creating or altering a SQL Server 2014 database to host a memory optimized table…
For a memory optimized table, all data is stored in memory and hence unlike disk based tables, pages don’t need to be brought into the buffer pool or cache. For data persistence of memory optimized tables, the In-memory OLTP engine creates a set of checkpoint files on a filestream filegroup that keeps track of changes to the data in an append only mode and uses this during recovery and the restore process.
In order to create a memory optimized table, you need to create a database with a filestream filegroup (along with the use of CONTAINS MEMORY_OPTIMIZED_DATA as shown below) or you can alter an existing database to add a filestream filegroup.
As you can see in the script below, I am creating a database with a filestream filegroup and specified two folders (please note I am not specifying the file name, but rather the folder names where the In-memory OLTP engine will store the data for the memory optimized table’s checkpoint files). As I mentioned in my earlier tips, memory optimized tables have a different access pattern than traditional disk based tables. It’s recommended to use SSD (Solid State Drive) or fast SAS drives for the filestream filegroup and to create multiple containers (volumes) to aid in parallel recovery.
USE master
GO
CREATE DATABASE MemoryOptimizedTableDemoDB
ON
PRIMARY(
NAME = [MemoryOptimizedTableDemoDB_data],
FILENAME = ‘c:\data\MemoryOptimizedTableDemoDB_data.mdf’, SIZE = 1024MB
),
FILEGROUP [MemoryOptimizedTableDemoDB_MOTdata] CONTAINS MEMORY_OPTIMIZED_DATA
(
NAME = [MemoryOptimizedTableDemoDB_folder1],
FILENAME = ‘c:\data\MemoryOptimizedTableDemoDB_folder1’
),
(
NAME = [MemoryOptimizedTableDemoDB_folder2],
FILENAME = ‘c:\data\MemoryOptimizedTableDemoDB_folder2’
)
LOG ON (
NAME = [MemoryOptimizedTableDemoDB_log],
FILENAME = ‘C:\log\MemoryOptimizedTableDemoDB_log.ldf’, SIZE = 500MB
);
GO
As I said, you can create memory optimized tables in a new database as well as create memory optimized tables in an existing database although you need to first add a filestream filegroup as shown below. You can also add multiple containers (volumes) to aid in parallel recovery.
ALTER DATABASE MemoryOptimizedTableDemoDB ADD FILEGROUP [MemoryOptimizedTableDemoDB_MOTdata]
CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE MemoryOptimizedTableDemoDB ADD FILE
(
NAME = [MemoryOptimizedTableDemoDB_folder1],
FILENAME = ‘c:\data\MemoryOptimizedTableDemoDB_folder1’
) TO FILEGROUP [MemoryOptimizedTableDemoDB_MOTdata]
GO
ALTER DATABASE MemoryOptimizedTableDemoDB ADD FILE
(
NAME = [MemoryOptimizedTableDemoDB_folder2],
FILENAME = ‘c:\data\MemoryOptimizedTableDemoDB_folder2’
) TO FILEGROUP [MemoryOptimizedTableDemoDB_MOTdata]
GO
These settings can also been seen or changed if you go to the database Properties and look at the Filegroups page:
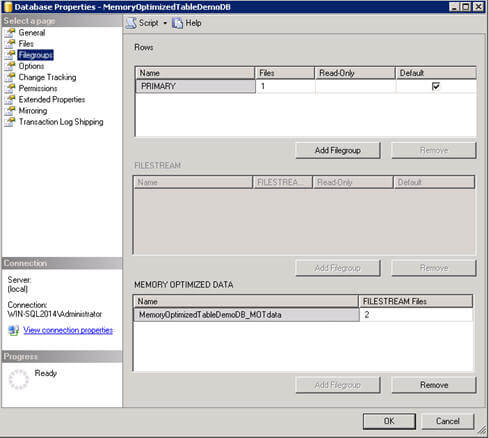
If you try to add additional filestream filegroups, SQL Server throws an exception as shown below. To summarize, you can have one filestream filegroup for memory optimized tables with multiple containers (volumes), but you cannot have multiple filestream filegroups.
Msg 10797, Level 15, State 2, Line 29
Only one MEMORY_OPTIMIZED_DATA filegroup is allowed per database.
Also, all three recovery models (Simple, Bulk-logged and Full) are supported for this database and you can take full and transactional backups, but differential backups are not supported.
Creating a memory optimized table…
Once you have a filestream filegroup available as part of the database, you can start creating memory optimized tables. There are some options to the script that you have to consider when creating memory optimized tables as well as there are some limitations, as discussed in Part 2 of this tip series, which you need to keep in mind.
Here is the sample script for creating a customer table, as you can see there are some additional keywords which I will explain:
CREATE TABLE [Customer](
[CustomerID] INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000),
[Name] NVARCHAR(250) NOT NULL INDEX [IName] HASH WITH (BUCKET_COUNT = 1000000),
[CustomerSince] DATETIME NULL
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);

When you create a memory optimized table, you need to specify the MEMORY_OPTIMIZED = ON clause to differentiate it from traditional disk based tables. You can create both memory optimized tables as well as disk based tables in a single database. The presence of the MEMORY_OPTIMIZED = ON clause tells the In-memory OLTP engine to take care of this table otherwise it is taken care of by the SQL Server database engine.
Memory optimized tables can have up to eight non-clustered indexes (no clustered index) and unlike B-Tree indexes on traditional disk based tables, these indexes don’t duplicate data, but rather just point to the rows in the chain. In-memory OLTP maintains these indexes online and they get created each time during database recovery. Memory optimized tables can have two types of indexes (note: all indexes are covering, it means they include all the columns in the table); the first is a Hash Index (as created with the above table). This is an ideal candidate if you have lots of queries which are going to do equi-joins (using the “=” operator) whereas the second type is a Range index which would be an ideal candidate if you have lots of queries that do a range selection (using “>” or “<” operators). I will talk about each of these index types in my next tip along with different scenarios and examples.
An important point to note with indexes are that they get created when you create the table and there is no way to drop, add or modify the index on the memory optimized table (as you can see above, the secondary index also gets created as part of the table creation). Having said that, you need to do a thorough analysis and proper index planning, based on the workload or queries you will have, before you create the memory optimized table.
With index specification, you also need to specify the BUCKET COUNT. The recommended value for this should be two times the expected number of unique values of that column.
With memory optimized tables you can either specify DURABILITY = SCHEMA_AND_DATA or DURABILITY = SCHEMA_ONLY. With the first option, which is the default, changes to table data are logged in the SQL Server transaction log and data gets stored in a filestream based filegroup. In other words, with this option you are actually instructing the in-memory OLTP engine to persist the data of the table, so that it can be recovered after an unexpected crash or a server restart. And with the later option, changes to the table’s data are not logged or stored on disk for persistence, but rather only the structure or schema of the table is saved as part of the SQL Server meta data. In other words, after a server restart the table will be available, but it will be an empty table.
On a memory optimized table, when you try creating an index on string columns that do not use a BIN2 collation your command will fail with this error message:
Indexes on character columns that do not use a *_BIN2 collation are not supported with indexes on memory optimized tables.
Msg 1750, Level 16, State 0, Line 54
Could not create constraint or index. See previous errors.
So either you need to have the default database collation as *_BIN2 or create the table by specifying the *_BIN2 collation for the string column on which you want to create the index as shown below:
CREATE TABLE [Customer](
[CustomerID] INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000),
[Name] NVARCHAR(250) COLLATE Latin1_General_100_BIN2 NOT NULL INDEX [IName] HASH WITH (BUCKET_COUNT = 1000000),
[CustomerSince] DATETIME NULL
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
You can find more information about collation requirements and considerations for memory optimized tables and natively compiled stored procedures here.
These are the steps which get executed when you create a memory optimized table:

So for example, for the table I created above if I execute the below script I can see the DLL for that table object has been created and loaded as shown below:
SELECT OBJECT_ID(‘Customer’)
SELECT name, description FROM sys.dm_os_loaded_modules
where description = ‘XTP Native DLL’

If you go to the above mentioned folder location, you will notice another folder with the database id (in my case it is 5) and then inside that you can see the DLL created for the table, along with other files like source file, debugger file, output file, etc.

If you peek inside the source file, you can see several methods are available for serialization, deserialization, hash computation, comparison and more.
Creating a natively compiled SQL Server stored procedure…
Although memory optimized tables can be accessed by traditional interpreted T-SQL or stored procedures, the In-memory OLTP engine introduces a new type of stored procedure called a natively compiled stored procedure. As its name implies, these stored procedures are compiled by the Microsoft’s Visual C/C++ compiler to native code via a C code generator. These natively compiled stored procedures can only access memory optimized tables. As these are natively compiled, they provide maximum performance though it has a limited T-SQL surface area (for example, no sub-queries, no outer joins, etc.). You should consider creating natively compiled stored procedures for OLTP type queries or when you want to optimize the performance of critical business logic.
There are certain elements of natively compiled stored procedures which you need to be aware of, for example, the procedure must be marked with the NATIVE_COMPILATION clause. The natively compiled stored procedure must be schema bounded and hence the SCHEMABINDING clause must be used. When these stored procedures are executed it requires an execution context and hence when creating it you need to use the EXECUTE AS clause. The natively compiled stored procedure must be atomic and hence the BEGIN ATOMIC clause along with other session settings needs to be provided.

For the memory optimized table I created above, here is the code to create a natively compiled stored procedure to insert a record into a memory optimized table:
CREATE PROCEDURE [dbo].[uspInsertCustomer] @CustomerID INT, @Name NVARCHAR(250), @CustomerSince DATETIME
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = ‘us_english’)
–Insert statement
INSERT INTO dbo.Customer (CustomerID, Name, CustomerSince) VALUES (@CustomerID, @Name, @CustomerSince)
END
GO
EXECUTE [dbo].[uspInsertCustomer] @CustomerID = 1, @Name = ‘Arshad’, @CustomerSince = ’01/01/2010′
GO
The process flow for creating a natively complied stored procedure is very similar to the process of creating a memory optimized table. When you execute the CREATE PROC DDL command, the query inside it gets optimized (please note, queries get optimized at the time of procedure creation) and C code is generated followed by compilation into native machine code.
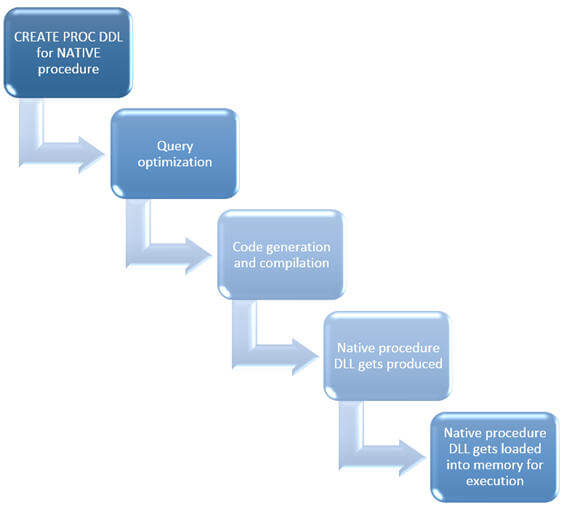
A native compiled procedure DLL is produced after compilation and gets loaded into memory for execution. Just like for a memory optimized table, if you go to the previously mentioned folder location, you will notice another folder with database id (in my case it is 5) and inside that you can see the DLL created for the natively compiled stored procedure we created along with other files like its source file, debugger file, output file, etc.

Please note, although natively compiled stored procedures provide very fast access to data for memory-optimized tables, interpreted Transact-SQL access is recommended for some specific scenarios like ad-hoc queries, reporting queries, during migration to reduce code changes, etc. You can find more information about what is supported and what is not supported when using interpreted T-SQL or stored procedures for memory optimized table here.
Performance check for In-Memory OLTP
In-memory OLTP improves the performance at two stages. First, when you create a memory optimized table the data for this table resides in memory and hence there is no IO when accessing it. Second, you can use natively compiled stored procedures to work with memory optimized tables and since they are natively compiled, they provide maximum performance. Natively compiled stored procedures (compile-once-and-execute-many-times) provide significant gain in performance over traditional interpreted stored procedures.
Here is a script you can execute to do performance improvement testing in your environment. For example, when I executed this script for a 100,000 records in a table with just two columns on my laptop, I can see a performance improvement of ~2.5 times when using a memory optimized table with interpreted T-SQL and ~18.5 times improvement when using a natively compiled stored procedure. You can see my results below:

Migrating Code to In Memory OLTP
SQL Server 2014 introduces a tool called AMR (Analysis, Migration and Reporting) to analyze and decide which tables and stored procedures you can migrate to gain performance by using the In-memory OLTP engine. The AMR tool is built into SQL Server Management Studio to help you evaluate if In-Memory OLTP will improve your database application’s performance. AMR will also indicate how much work you must do to enable In-Memory OLTP in your application. You can find more information about this tool here.
In this section, I am going to talk about how to manage limitations of a memory optimized table when migrating from disk based tables.
As I discussed in earlier tip, there are several limitations when using memory optimized tables, for example you cannot specify a column to be an identity, foreign key constraints are not allowed, check constraints are not allowed, etc. So the question is, what alternatives do we have to overcome these limitations. For example, consider you have an existing disk based table with an identity column and you want to convert it to a memory optimized table. The alternative is to use a sequence object to generate sequential unique numbers and use that number explicitly to insert into the table as you can see below:

Likewise, to overcome foreign key limitations you can use the below validation script before you insert data into transaction table to ensure a customer exists to whom this transaction belongs.

You can find more detail and examples of these alternatives in this tip.
Please note, information and examples shown are based on SQL Server 2014 CTP2 release (you can download it here) and things might change in the RTM release. Please refer to Books Online for updated information.
Next Steps
- Review my related tips on this this topic:
- Getting started with the AMR tool for migration to SQL Server In-memory OLTP Tables
- Overview of Applications, Indexes and Limitations for SQL Server 2014 In-Memory OLTP Tables
- SQL Server 2014 In Memory OLTP Durability, Natively Compiled Stored Procedures and Transaction Isolation Level
- SQL Server 2014 In-Memory OLTP Architecture and Data Storage
- Review Books Online – In-memory OLTP
- Review Collations and Code Pages – for memory optimized tables and natively compiled stored procedures on TechNet.
- Review Workaround for lack of support for constraints on SQL Server Memory-Optimized Tables tip.

Arshad specializes in Database, Data Warehousing and Business Intelligence application design, development and deployment, at enterprise level, with SQL Server, SSIS, SSRS, SSAS, Service Broker, MDS, DQS, SharePoint and PPS. He is a Microsoft Certified IT Professional in Microsoft SQL Server. He also has experience developing applications in VB/ASP/.NET/ASP.NET/C#, and is a Microsoft Certified Application Developer and Solution Developer for the .NET platform in Web/Windows/Enterprise. Arshad has Master’s degrees in Computer Applications and Business Administration in IT.
Disclaimer: Arshad worked for Microsoft and helped people and businesses make better use of technology to realize their full potential. The opinions mentioned in his tips and articles herein are solely his and do not reflect those of his current or previous employers.
- MSSQLTips Awards: Champion (100+ tips) – 2014