By: Aaron Bertrand | Comments (7) | Related: > Triggers
Problem
We all know that triggers can be a performance issue, but since we can have distributed applications with ad hoc SQL queries, and ORMs like Entity Framework, triggers might be our only recourse for enforcing business rules. One of the performance problems with AFTER triggers is that if you want to prevent the action from happening based on some business rule, an AFTER trigger is exactly that - in order to "prevent" the action, you actually have to let it happen, then "undo" it by rolling it back.
Solution
An INSTEAD OF trigger can allow you to check your business rules before performing the action, avoiding the need to log and roll back. This can be much more efficient, particularly if your log file is on a slow disk.
Let's pretend we have a table that stores usernames (and for these tests, we'll make two, one for an AFTER trigger and one for an INSTEAD OF trigger):
CREATE TABLE dbo.UserNames_After ( ID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE ); CREATE TABLE dbo.UserNames_InsteadOf ( ID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE );
And we'll create another table that stores a list of exceptions; usernames we don't want to allow. You can use your imagination here; but given the season, I'll just put one row in this table - a "naughty" word from Elf.
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
INSERT dbo.NaughtyUserNames VALUES('ninny-muggins');
GO
For simplicity, let's assume that either (a) all inserts will be singletons, or (b) when any one row in a multi-row insert violates our business rule, we want to fail all rows.
(Of course, we can't use a subquery in a check constraint, and while we could use a check constraint with a UDF, I've been burned enough to stay away from them - see this post by Alexander Kuznetsov and the comments on this question. An alternative might be a check constraint that hard-codes the list of naughty names, but this can become unmanageable quite quickly, never mind not very practical if you have multiple tables where you want to run this check.)
So, an AFTER trigger might look like this:
CREATE TRIGGER dbo.trUserNames_After
ON dbo.UserNames_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
RAISERROR('You used a naughty name!', 11, 1);
ROLLBACK TRANSACTION;
END
END
GO
Quite simply, if a user attempts to insert the name "ninny-muggins," the transaction will be rolled back and an exception will be raised:
INSERT dbo.UserNames_After(Name) SELECT 'ninny-muggins';
Results:
Msg 50000, Level 11, State 1, Procedure trUserNames_After, Line 62 You used a naughty name! Msg 3609, Level 16, State 1, Line 46 The transaction ended in the trigger. The batch has been aborted.
Of course letting SQL Server raise its own exceptions can be costly (as I've demonstrated before), and performing work only to undo it seems like it could be wasteful. So let's see if we can accomplish the same preventative measures without that extra work, using an INSTEAD OF trigger.
The downside of an INSTEAD OF trigger is that, unlike other platforms that have BEFORE triggers, the trigger actually cancels the statement that fired it. So the trigger code has to still perform the eventual insert, meaning you have to duplicate the insert statement that you have elsewhere in your application (except that now the insert comes from the inserted pseudo-table). With that drawback out of the way, here is what our INSTEAD OF trigger would look like:
CREATE TRIGGER dbo.trUserNames_InsteadOf
ON dbo.UserNames_InsteadOf
INSTEAD OF INSERT
AS
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
INSERT dbo.UserNames_InsteadOf(Name) SELECT Name FROM inserted;
END
ELSE
BEGIN
RAISERROR('You used a naughty name!', 11, 1);
END
END
GO
We still raise an error if a naughty name is used, but there is no reason to perform a ROLLBACK here, since there is nothing to roll back. This allows you to avoid the logging involved with writing to the table in the case where you were only going to roll it back anyway.
Now, how does this affect performance, and the log file? Well, let's say we're going to insert 1000 names into our table, and 10% are going to hit our naughty list. We can generate a set that meets these criteria, run a cursor that tries to insert all of these names one by one, and measure the timing and impact to the log. Demo script:
TRUNCATE TABLE dbo.UserNames_After;
TRUNCATE TABLE dbo.UserNames_InsteadOf;
CHECKPOINT;
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT))/128.0
FROM sys.database_files
WHERE name LIKE '%[_]log';
DECLARE @n NVARCHAR(255), @u UNIQUEIDENTIFIER;
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT TOP (900) name = o.name + '/' + c.name, u = NEWID()
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id]
UNION ALL
SELECT TOP (100) name = 'ninny-muggins', u = NEWID()
FROM sys.all_objects
ORDER BY u;
OPEN c;
FETCH c INTO @n, @u;
SELECT SYSDATETIME();
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
INSERT dbo.UserNames_InsteadOf(name) SELECT @n;
--INSERT dbo.UserNames_After(name) SELECT @n;
END TRY
BEGIN CATCH
PRINT 'Failed';
END CATCH
FETCH c INTO @n, @u;
END
SELECT SYSDATETIME();
CLOSE c; DEALLOCATE c;
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT))/128.0
FROM sys.database_files
WHERE name LIKE '%[_]log';
The results are as follows (and thanks to Greg Robidoux for the free space calculation from this tip):
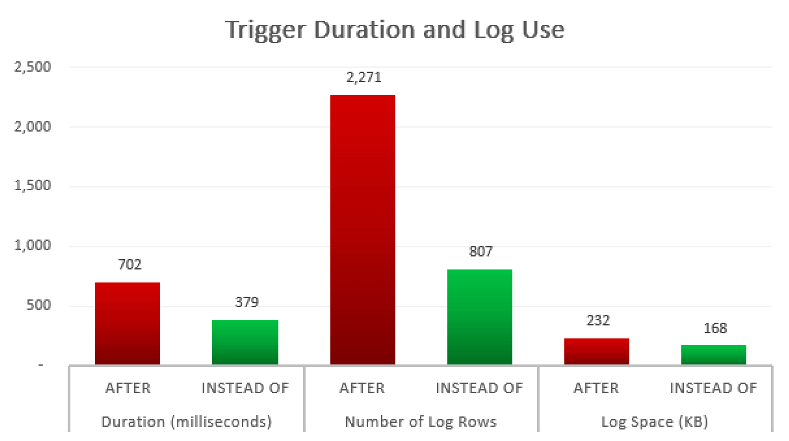
So, clearly we see some benefit all around by preventing an insert and a rollback, even when the failure rate is only 10%. Depending on your set of invalid names, as well as the creativity and volume of your user base, your failure rate may be much higher. It is unlikely you could envision a use case where this approach would be *less* efficient with an INSTEAD OF trigger than an AFTER trigger, so my recommendation is to consider INSTEAD OF triggers for more than just the case where you want the ability to update a view.
Next Steps
- Identify any AFTER triggers in your environment that could be causing unnecessary work in the event of failure.
- Consider changing those triggers to INSTEAD OF triggers.
- Check out the following tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
