By: Tim Wiseman | Comments (5) | Related: 1 | 2 | 3 | > Data Types
Problem
When more than one numeric SQL Server data type may be suitable for a field in a project, which data type should I choose? What implications might the choice of a data type have for storage and performance in SQL Server?
Solution
SQL Server has nine different data types for storing numeric information, but they have differences that may make them more or less suitable for different uses. Clearly, if you need to store a decimal value than the INT data type is inappropriate. Similarly, you would use DECIMAL or NUMERIC, instead of REAL, if you wanted to store an exact value since REAL stores an approximate value.
But there are times when there is more than one data type which could hold the values needed. For instance, BIGINT or DECIMAL with its default values could almost always be used in place of INT. However, there are performance and size reasons to generally prefer the smaller data type. To look at this let us create three tables with 150 million rows and give them primary keys, but no other indexes. One will use INT, the other BIGINT, and the final one will use DECIMAL.
use test
GO
/* Purge any tables that already exist to start fresh*/
if OBJECT_ID('IntTbl', 'U') is not NULL
drop table dbo.IntTbl
if OBJECT_ID('BigIntTbl', 'U') is not NULL
drop table dbo.BigIntTbl
if OBJECT_ID('DecimalTbl', 'U') is not Null
drop table dbo.DecimalTbl
/* Create the tables.
Each table will have three columns, mostly to ensure
the rows are relatively sizable and to magnify the
difference made by the size of the data types to make it easier to see.
The first column will be a direct count up to their number of rows.
The second column will start at the maximum number of rows and go to 0.
The third column will be the first column times two.
Each table will have a primary key and its associated clustered index,
but will have no nonclustered indexes.*/
create table IntTbl
(col1 Int primary key, --No nonclustered IDX, but we'll have a PK
col2 Int,
col3 Int)
create table BigIntTbl
(col1 BigInt primary key,
col2 BigInt,
col3 BigInt)
--Default Decimal, which has a default precision of 18 and scale of 0
create table DecimalTbl
(col1 Decimal primary key,
col2 Decimal,
col3 Decimal)
/* Create a variable to store the maximum number to insert.
Helps ensure all tables have the same number of inserts */
declare @maxValue int
set @maxValue = 150000000 --150 Million
/*Now populate the tables.
The Tablock table hint is used to avoid potential issues with
lock resources.
More one the use of TABLOCK at:
http://timothyawiseman.wordpress.com/2014/05/26/dealing-with-sql-server-lock-resource-errors/
*/
insert into dbo.IntTbl with (TABLOCK) (col1, col2, col3)
select top (@maxValue)
row_number() over (order by s1.name) as col1,
@maxValue - row_number() over (order by s1.name) as col2,
row_number() over (order by s1.name) * 2 as col3
from master.dbo.syscolumns s1,
master.dbo.syscolumns s2
insert into dbo.BigIntTbl with (TABLOCK) (col1, col2, col3)
select top (@maxValue)
row_number() over (order by s1.name) as col1,
@maxValue - row_number() over (order by s1.name) as col2,
row_number() over (order by s1.name) * 2 as col3
from master.dbo.syscolumns s1,
master.dbo.syscolumns s2
insert into dbo.DecimalTbl with (TABLOCK) (col1, col2, col3)
select top (@maxValue)
row_number() over (order by s1.name) as col1,
@maxValue - row_number() over (order by s1.name) as col2,
row_number() over (order by s1.name) * 2 as col3
from master.dbo.syscolumns s1,
master.dbo.syscolumns s2
I set up a Python script to time a number of different possible operations on each of these tables. Each test was run 50 times with the results averaged. For instance, I had the server return a simple row count. In another test, I selected 100 values arbitrarily and then had the server return the rows with those values in the primary key.
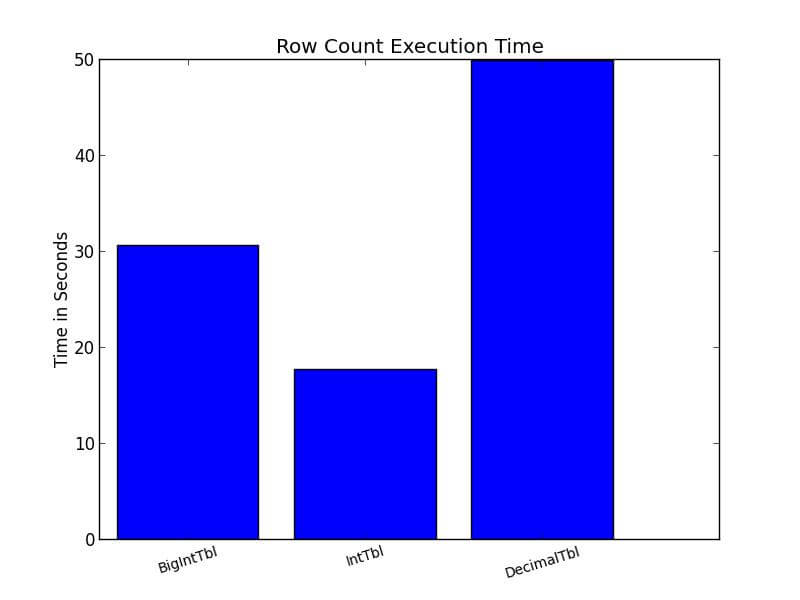
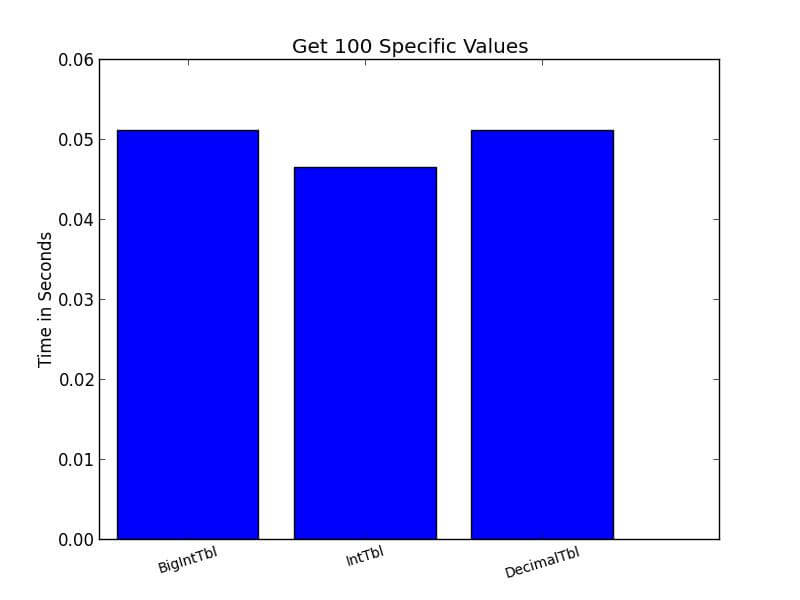
I also ran several other tests that aren't displayed to preserve space. In each of these tests, the table using DECIMAL came out substantially worse than the tables using INT and BIGINT. The picture with INT and BIGINT was much less clear and less consistent. The differences were often small between IntTbl and BigIntTbl. BigIntTbl occasionally outperformed IntTbl. But in most situations, INT came out slightly faster than BIGINT.
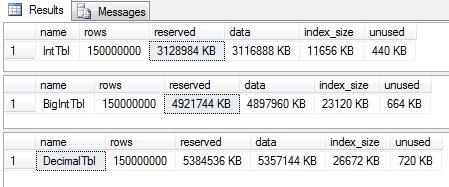
The results on the space used were perfectly clear. We can see this by running sp_spaceused against each of the tables. Although all three tables hold exactly the same data, the BigIntTbl is more than 60% larger than IntTbl, and DecimalTbl is larger still. To be clear, at this point each table has a clustered index, but no nonclustered indexes.
The data types will also have a major impact on the size of any nonclustered indexes we create. If we put a nonclustered index on the second column for each of them using:
CREATE UNIQUE NONCLUSTERED INDEX IntTblIndex ON dbo.IntTbl (col2 ASC) CREATE UNIQUE NONCLUSTERED INDEX BigIntTblIndex ON dbo.BigIntTbl (col2 ASC) CREATE UNIQUE NONCLUSTERED INDEX DecimalTblIndex ON dbo.DecimalTbl (col2 ASC)
We can then use SYS.DM_DB_PARTITION_STATS to get an approximate size for the indexes.
select
i.name,
i.type_desc,
s.used_page_count,
s.used_page_count * 8 as ApproxSizeKb
from
sys.indexes i
inner join sys.dm_db_partition_stats s
on s.object_id = i.object_id and s.index_id = i.index_id
where
i.name in ('IntTblIndex', 'BigIntTblIndex', 'DecimalTblIndex')
Which gives:
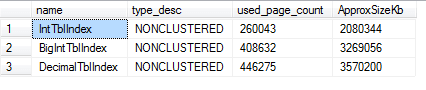
The bigIntTblIndex is more than a third larger than IntTblIndex and DecimalTblIndex is larger still. Their size also affected how long it took to create the indexes. The BigIntTblIndex took nearly a third longer to create than IntTblIndex.
In conclusion, the data type chosen to hold numeric data has substantial impact on the speed of some operations, the space used by the table, and the space used by the indexes. While the data type always needs to accommodate the range of values expected for a field, including possible future growth, noticeable savings in space and execution time can be gained when the smaller, more efficient data type is chosen.
Next Steps
- Robert Sheldon provides a wide array of information about data types and their importance in his article Questions about SQL Server Data Types You were Too Shy to Ask.
- There is more about finding the size of an index at Basit's blog here.
- Ben Snaidero provides an article comparing SQL Server and Oracle data types.
- Check out all SQL Server Data Type Tips.






About the author
 Tim Wiseman is a SQL Server DBA and Python Developer in Las Vegas.
Tim Wiseman is a SQL Server DBA and Python Developer in Las Vegas.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
