Problem
In a previous tip on Installing SQL Server 2008 on a Windows Server 2008 Cluster Part 2, we’ve seen how to install and configure a Windows Server 2008 Failover Cluster in preparation for installing a SQL Server 2008 failover clustered instance. In this fourth part of the series we look at additional PowerShell commands that can be used.
Solution
To continue this series on Installing, Configuring and Managing Windows Server Failover Cluster using PowerShell, let’s explore more PowerShell cmdlets that we can use to perform common troubleshooting tasks. Let’s say that you received an alert from your monitoring tool (I’m assuming that you do have a monitoring tool because it’s a sin not to have one) that your SQL Server failover clustered instance is offline. Since the SQL Server clustered resource resides in a clustered resource group, let’s use the Get-ClusterGroup, the Get-ClusterResource and the Get-ClusterResourceDependency cmdlets to identify which resources in the group is causing our SQL Server resource to be offline (I used the Format-Table cmdlet to display the results properly.)
PS C:\> Get-ClusterGroup "SQL Server (MSSQLSERVER)" | Get-ClusterResource | Get-ClusterResourceDependency

Looking at the results, I know which cluster resource is dependent on what. For example, the SQL Server clustered resource is dependent on G_Drive, F_Drive and SQL Network Name (SQLCLUSTER). Let’s see which of those resources are offline using the Get-ClusterResource cmdlet.
PS C:\> Get-ClusterGroup "SQL Server (MSSQLSERVER)" | Get-ClusterResource

Notice that only the SQL Server Agent (this is dependent on the SQL Server resource) and the SQL Server resources are offline. This means that I can simply bring the SQL Server clustered resource online to bring my SQL Server instance online. We can use the Start-ClusterResource cmdlet for this task.
PS C:\> Start-ClusterResource "SQL Server"

If the cluster resources on which the SQL Server resource depends on – G_Drive, F_Drive and SQL Network Name (SQLCLUSTER) – are offline, the Start-ClusterResource cmdlet will automatically bring them online first before finally bringing the SQL Server cluster resource online. This saves you the hassle of manually bringing them online first before finally bringing the dependent resource online. However, I don’t usually start with the cluster resource that has the most dependencies. In fact, I start with the one with no dependencies. The reason for this is that those with no dependencies may have dependencies outside of the cluster. An example of this is the SQL Server virtual network name resource. While this has no dependencies on any cluster resource, it is dependent on both Active Directory and DNS. A typical SQL Server DBA may not have access to both environments and would have to escalate the issue to the network and system administrators. If I start with the SQL Server Agent resource, I may end up wasting a lot of time and effort trying to fix something that I have no control over.
A word of caution: Avoid the temptation to investigate the root cause while bringing the SQL Server failover clustered instance online. As engineers, we almost always want to solve a particular issue immediately. The goal in every disaster recovery situation is to bring the system back online as quickly as we possibly can to meet our recovery objective. You can leave the investigation and root cause analysis after the SQL Server failover clustered instance is brought online, the applications can connect to the databases and the users are happy.
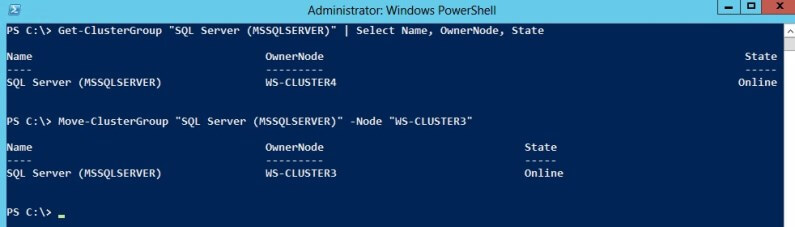
Now that we’ve brought the SQL Server failover clustered instance online, let’s say we want to move the cluster resource group to our preferred node. In this example, the SQL Server cluster resource group is currently owned by WS-CLUSTER4. We can move this to WS-CLUSTER3 by using the Move-ClusterGroup cmdlet.
PS C:\> Move-ClusterGroup "SQL Server (MSSQLSERVER)" -Node "WS-CLUSTER3"
To investigate why the cluster resources have gone offline, we need to look at the contents of the cluster log. Prior to Windows Server 2008, a text file named CLUSTER.LOG was used to store all of the cluster-related events. This file was stored in the %systemroot%\Cluster\ folder. Starting with Windows Server 2008, the cluster-event logs are now handled by Windows Event Tracing (ETW), which is the same logging mechanism used for events running on Windows. This also means that you can now read the cluster log in Windows Event Viewer under Applications and Services -> Microsoft -> Windows -> FailoverClustering. Alternatively, we can use the Get-ClusterLog cmdlet to generate the cluster log and store it as a file. What I really like about this is that you can generate the cluster log even when the Windows Server Failover Cluster creation fails. By default, it will generate the log file for the cluster and store it on the %systemroot%\Cluster\Reports folder.
PS C:\> Get-ClusterLog
You can specify a custom location for the generated cluster log file by using the -Destination parameter.
PS C:\> Get-ClusterLog -Destination F:
My only pet peeve with the cluster log is that the timestamp used in capturing the events are in UTC. This becomes confusing when you’re dealing with cluster nodes in different timezones or dealing with Daylight Savings Time. In the good old days of Windows Server 2003, I have had to perform some time conversions to correlate the cluster log events with those on the Windows Event Log and the SQL Server error log. Good thing that there is the -UseLocalTime parameter when running the Get-ClusterLog cmdlet.
PS C:\> Get-ClusterLog -UseLocalTime
If you feel that you need to evict one of the cluster nodes due to hardware-related issues, you can do so by using the Remove-ClusterNode cmdlet, passing the name of the node that you want to remove from the cluster. You will be prompted for a confirmation to proceed.
PS C:\> Remove-ClusterNode -Name "WS-CLUSTER4"

After fixing the removed node, you can add it back by using the Add-ClusterNode cmdlet. Be sure to run the Test-Cluster cmdlet before adding the node to the cluster as discussed in this previous tip.
PS C:\> Add-ClusterNode -Name "WS-CLUSTER4"
There might be cases when you don’t see the cluster resources in Failover Cluster Manager, but you do see them when you run the Get-ClusterResource cmdlet.

When this happens, I rely on the results of the Windows PowerShell cmdlets to tell me the truth. Besides, if my client applications can connect to my SQL Server instance, I bet it’s still there. I just can’t see it with the GUI. This is where you really need the Windows PowerShell cmdlets that we’ve already covered. What I usually do is move my clustered resource group from one node to another and that makes it appear on the Failover Cluster Manager console.
In this tip, we used Windows PowerShell to perform the following tasks:
- brought a SQL Server clustered resource group online,
- retrieved the cluster error log,
- evicted a node from a cluster and
- added a node to a cluster.
Next Steps
- Review the previous tips on Install SQL Server 2008 on a Windows Server 2008 Cluster Part 1, Part 2, Part 3 and Part 4. This will help you map the Failover Clustering PowerShell cmdlets with their corresponding actions on the Failover Cluster Management console.
- Read Part1, Part2 and Part3 of this series for more PowerShell commands for clusters.

Edwin M. Sarmiento is the Managing Director of 15C, a consulting and training company that specializes on designing, implementing and supporting SQL Server infrastructures. He is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures running on the Microsoft server technology stack ranging from Active Directory to SharePoint and anything in between. He is very passionate about technology but has interests in music, professional and organizational development, and leadership and management matters when not working with databases. Edwin lives up to his primary mission statement: “To help people and organizations grow and develop their full potential.”
- MSSQLTips Awards: Champion Award (100+ tips) – 2017 | Author of the Year Contender – 2020, 2017
