Problem
Sometimes we need to JOIN tables using character data types and creating an index will help performance, but the columns may be too large to create an index due to the index size limitations.
When we create an index on a column which can potentially exceed 900 bytes, we will receive a warning: “Warning! The maximum key length is 900 bytes. The index xxxx has maximum length of xxxx bytes. For some combination of large values, the insert/update operation will fail.”.
Then, when we try to insert data into these columns which exceeds 900 bytes, we will receive the following error: “Operation failed. The index entry of length xxxx bytes for the index exceeds the maximum length of 900 bytes.”.
Obviously creating indexes on such types of columns is not the best decision, however sometimes this is the only option and not having an index can greatly impact performance. This tip aims to explain how we can optimize JOIN operations on tables that use large varchar(nvarchar) type columns in JOIN conditions where creating an index causes the above issues.
Solution
Suppose we have two tables which contain large amounts of data and they should be joined using two columns of NVARCHAR(500) data type. Our task is to monitor the performance and optimize the query. Let’s start by creating a test environment. We will create database TestDB and two tables; TableA and TableB:
USE master GO --Creating the database CREATE DATABASE TestDB GO USE TestDB GO --Creating TableA CREATE TABLE TableA ( ID INT IDENTITY(1,1), Value1 NVARCHAR(500), Value2 NVARCHAR(500) ) --Creating TableB CREATE TABLE TableB ( ID INT IDENTITY(1,1), Value1 NVARCHAR(500), Value2 NVARCHAR(500) )
Now let’s try to create an index on columns “Value1” and “Value2” on table TableA:
--Creating an index on TableA Use TestDB GO CREATE INDEX IX_TableA_Value1_Value2 ON TableA( Value1, Value2 ) GO
The index has been created, however a warning arises:

When we try to insert the data into “Value1” and “Value2” fields, which exceeds 900 bytes, an error will arise:
USE TestDB
GO
--Inserting data into TableA
INSERT INTO TableA(Value1, Value2) SELECT REPLICATE('a', 480), REPLICATE('b', 480)

So based on these issues, this index is not useful, so we will drop it:
--Drop index USE TestDB GO DROP INDEX TableA.IX_TableA_Value1_Value2
Now we will insert sample data into these tables:
USE TestDB
GO
DECLARE @i INT =1
--Inserting data into TableA
--(Value 300000 is used to facilitate testing process,
--please be careful in choosing this value for your server to avoid overloading it)
WHILE (@i <=300000)
BEGIN
INSERT INTO TableA(Value1, Value2)
SELECT CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID()),
CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
SET @i=@i+1
END
--Inserting data into TableB
--(Value 300000 is used to facilitate testing process,
--please be careful in choosing this value for your server to avoid overloading it)
SET @i=1
WHILE (@i <=300000)
BEGIN
INSERT INTO TableB(Value1, Value2)
SELECT CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID()),
CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
+CONVERT(NVARCHAR(36), NEWID())
SET @i=@i+1
END
--Inserting data from TableA to TableB
INSERT INTO TableB(Value1, Value2)
SELECT TOP (3000) Value1, Value2
FROM TableA
We need to find all rows from TableA which have the same values in the "Value1" and "Value2" fields in TableB. Let's execute the query which retrieves the necessary result and monitors performance:
Use TestDB
GO
SELECT a.ID AS A_ID, a.Value1 AS A_Value1, a.Value2 AS A_Value2,
b.ID AS B_ID, b.Value1 AS B_Value1, b.Value2 AS B_Value2
FROM
TableA a
INNER JOIN
TableB b
ON a.Value1=b.Value1 AND a.Value2=b.Value2
It returns 3000 rows from TableA which exists in TableB and takes 1 minute:
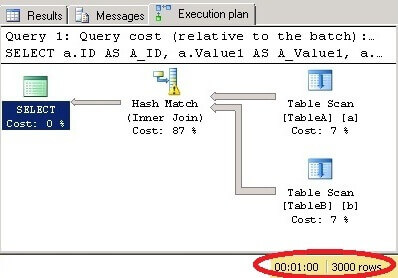
Using CHECKSUM to do joins
To optimize this query we will use the CHECKSUM function. CHECKSUM is a good candidate for creating hash indexes. It receives an expression as a parameter, computes and returns an integer value called CHECKSUM. The expression can be any data type except these ( text, ntext, image, XML, cursor, sql_variant ). Using CHECKSUM is not a guarantee that the checksum values for different expressions will always be different, it is possible it will generate the same CHECKSUM for different expressions, so this fact should be considered.
In our tables we will create a checksum column generated from the values of "Value1" and "Value2" columns:
USE TestDB GO ALTER TABLE TableA ADD chks_Value AS CHECKSUM(Value1, Value2) GO ALTER TABLE TableB ADD chks_Value AS CHECKSUM(Value1, Value2) GO
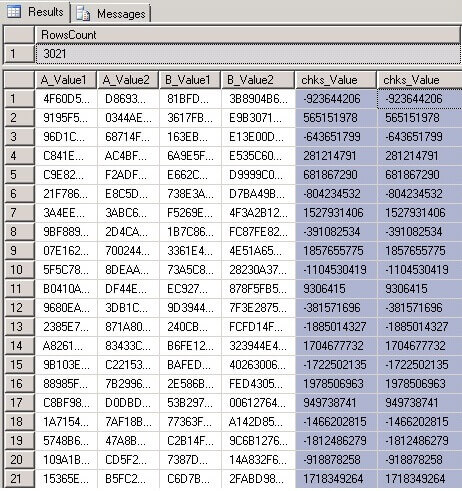
By joining tables in our example using the CHECKSUM columns with the ON clause we will receive 3021 rows instead of 3000, which means that for some values the same checksum was generated. So to eliminate these mismatched records we add some additional checks in the ON clause for the second query below.
USE TestDB
GO
SELECT COUNT(*) AS RowsCount
FROM TableA a
INNER JOIN TableB b
ON a.chks_Value=b.chks_Value
--Selecting rows, where Values are different, but CHECKSUMs are the same
SELECT a.Value1 AS A_Value1, a.Value2 AS A_Value2,
b.Value1 AS B_Value1, b.Value2 AS B_Value2,
a.chks_Value, b.chks_Value
FROM TableA a
INNER JOIN TableB b
ON a.chks_Value=b.chks_Value
AND (a.Value1<>b.Value1 OR a.Value2<>b.Value2)
Adding an index for CHECKSUM column
It is possible to improve performance by creating indexes on the CHECKSUM columns. In our example there is no clustered index on our tables, so we can create clustered indexes on the checksum columns. It should be noted that creating clustered indexes will physically sort the data in the table and as our tables contain larges amount of data, this process may take some time:
USE TestDB GO CREATE CLUSTERED INDEX CIX_TableA_chks_Value ON TableA(chks_Value) GO CREATE CLUSTERED INDEX CIX_TableB_chks_Value ON TableB(chks_Value) GO
To get the desired result, first we need to join the tables using the checksum columns in the join condition, and then choose only the rows from result where "Value1" and "Value2" fields match. To do that we will use a temporary table, to store the staging result, and then we will get the final result from the staging table. This approach is optimal when the estimated row count which is common to TableA and TableB is low compared with the overall count of rows in TableA and TableB. In this case the row count in the staging result will be much less and comparing values of character type will not take as long.
Use TestDB
GO
--Creating staging table, to store data matched with checksum columns
IF OBJECT_ID('tempdb..#tmpStaging') IS NOT NULL
DROP TABLE #tmpStaging
SELECT a.ID AS A_ID, a.Value1 AS A_Value1, a.Value2 AS A_Value2,
b.ID AS B_ID, b.Value1 AS B_Value1, b.Value2 AS B_Value2
INTO #tmpStaging
FROM TableA a
INNER JOIN TableB b
ON a.chks_Value=b.chks_Value
--Final result
SELECT A_ID, A_Value1, A_Value2, B_ID, B_Value1,B_Value2
FROM #tmpStaging
WHERE A_Value1=B_Value1 AND A_Value2=B_Value2
Running this query, we can see performance was improved and it now takes only 30 seconds:
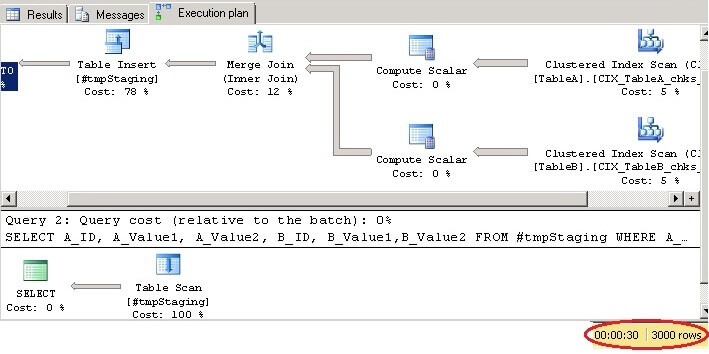
In production environments it is possible that we will not be able to change the structure of tables or sometimes we may need to join large amounts of staging data from different tables. So, to solve this problem we can load the data into temporary tables, then do the necessary modifications (creating checksum column, indexing, etc.), and then use these temporary tables for joining and generating the necessary results.
Also in our example we join tables by comparing values from two columns per table, however in real cases there may be more than two columns per table. In addition, the data in the tables may be much more than in our example. In these cases performance gains using a CHECKSUM column and indexes will be more visible.
Using HASHBYTES instead of CHECKSUM
One of the issues we saw was that duplicate CHECKSUM values were generated for different data values. Another option is to use HASHBYTES instead of CHECKSUM as shown below.
USE TestDB
GO
ALTER TABLE TableA
ADD hash_Value AS HASHBYTES('MD5',ISNULL(Value1,'null')+ISNULL(Value2,'null'))
GO
ALTER TABLE TableB
ADD hash_Value AS HASHBYTES('MD5',ISNULL(Value1,'null')+ISNULL(Value2,'null'))
GO
But there are a few things to note. HASHBYTES is slower than CHECKSUM, however the possibility to generate the same hash for different values are less than with CHECKSUM. Also, the HASHBYTES function returns data type VARBINARY(8000), so creating an index on this column will cause the above mentioned warning that values in the index can exceed the maximum size of the index. Another difference is that HASHBYTES generates NULL when the expression is NULL, so when we work with nullable columns we should consider this fact as well.
Conclusion
Joining tables using columns of character string types in join conditions can cause serious performance problems when the data in tables is very large. As you can see, we can avoid these problems by adding additional columns with data generated using the CHECKSUM function, creating indexes and using these columns when we join tables.
Next Steps
Learn more:

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020