Problem
I have a SQL Server Availability Group (AG) on a Windows Server Failover Cluster (WSFC) with 3 nodes using Node Majority quorum configuration. In an unforeseen circumstance, 2 nodes went completely offline at the same time causing the WSFC to go down.
This caused the AG to go into a Resolving state and all the databases in the AG and the AG Listener to be inaccessible. How can I recover the WSFC cluster node to start without a quorum and later fully re-establish HA for AlwaysOn AG when the 2 nodes are up?
Solution
We can bring up the WSFC on minority elements that are required for a quorum using the forced quorum method.
To outline the solution per the problem description, we will assume our infrastructure configuration as below.

In this scenario, SQLP1 and SQLP3 are unavailable. WSFC goes down and AG is inaccessible. In this situation, when you try to connect to the WSFC from the Failover Cluster Manager, it will give you the error below.

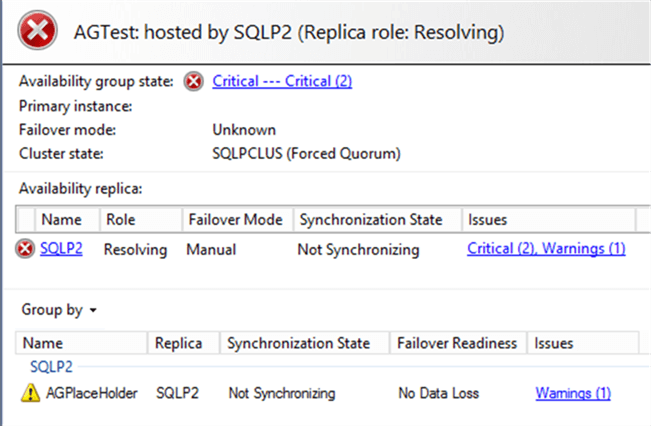
Since SQLP2 is still up and running, you can connect to SQLP2 from SSMS. From here, the AG Dashboard lists SQLP2 in the Availability replica, but AGTest is in a Resolving state, meaning none of the databases in the AG will be accessible.

Recover WSFC using Force Quorum
The recovery steps to bring up the single node SQLP2 for the WSFC and subsequently re-establish HA for the AG can be summarized as per the flow chart below.

Step 1 - Login to SQLP2
All recovery steps and commands can be performed remotely, but typically logging in to the server allows important checks such as making sure the server is actually up and available. Sometimes, a ping command could return a reply, but the Windows Server OS could be completely hung.
In this tip, we will login to server SQLP2 to execute the next step.
Step 2 - Shutdown cluster service
The cluster service on SQLP2 can be shutdown either from the Services Microsoft Management Console or a command prompt. We will use the latter and launch a command prompt running as Administrator to shut down the cluster service.
C:\>Net stop clussvc

Step 3 – Bring up cluster service with Forcequorum
Once the cluster service on SQLP2 is stopped, start up the cluster service again with a force quorum.
C:\>Net start clussvc /forcequorum

Step 4 – Failover AG to SQLP2 with Allow Data Loss
You will now be able to connect to the WSFC using Failover Cluster Manager, but the AG will still be in a Resolving state. This means the AG Listener and AG databases are still inaccessible.
When the WSFC is up, the user databases in the AG will now appear in the AG Dashboard, but in a Not Synchronizing state.
We will need to perform a forced AG failover to the SQL Server replica which is still up and running using the with allow data loss option. This step is still required even when the node was the primary SQL Server replica prior to the disaster.
The T-SQL command below will be executed on SQLP2.
USE master
GO
PRINT @@SERVERNAME
GO
ALTER AVAILABILITY GROUP AGTest FORCE_FAILOVER_ALLOW_DATA_LOSS;
GO

Step 5 – AG should be up and running
Refresh the AG Dashboard and it should now show SQLP2 as Primary and running. This will allow applications to connect to the AG listener and the workload to resume as you would in a normal production environment.

Step 6 – When SQLP1 and SQLP3 is up and running, resume AG data movement
When the 2 servers SQLP1 and SQLP3 are fixed and running, they will re-join the WSFC automatically. As long as AG is not removed from the 2 other SQL Server instances, they will be able to re-join into the AG as well. But all database synchronization for the AG will need to be manually resumed.
Resuming of data movement can be done either from SSMS or T-SQL.

Alternatively, the T-SQL to resume data movement for the AG is as below:
ALTER DATABASE [AGplaceHolder] SET HADR RESUME;<br>GO
Once the data movement is resumed and caught up the AG Dashboard will show the Synchronization State as Synchronized.

These same steps need to be performed on each user database in the AG and on all the secondary replicas to resume the data movement.
Conclusion
This tip shows how you can perform a force quorum to bring up WSFC online on a single alive node. The same steps are applicable to force a quorum in a single-site or multi-site cluster.
Most importantly, be aware that log truncation will be delayed on a given primary database while any of its secondary databases is suspended. Therefore, if the outage period is prolonged, consider removing the failed replica from the AG to avoid running out of disk space due to log truncation delay.
Next Steps
- Perform a Forced Manual Failover of an Availability Group (SQL Server)
- Resume an Availability Database (SQL Server)
- What is SQL Server AlwaysOn?
- Read this tip to understand transaction log truncation delay Long Running Transactions Cause SQL Server Transaction Log to Grow

Simon Liew is an independent SQL Server Consultant in Sydney, Australia. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing.
- MSSQLTips Awards: Trendsetter (25+tips) – 2017 | Author of the Year Contender – 2016, 2017

Simon, looks good, but I have another step
I had the same thing happen to me and I had to force quorum in WSFC and then force fail over of the AG. All my nodes were up and synchronized.
I then wanted to manually fail over the AG from one node to another and found it had the “with data loss” status. When I click on it the message said
The WSFC Cluster is in forced quorum state. Failing over this replica could result in data loss for any transactions that did not reach the replica during quorum loss event.
To resolve the problem I just dropped and recreated the FileWitnessShare and everything went back to normal. What I suspect is my action caused the quorum to be recreate.
Hi Wilner,
Supposed we lose connectivity between two sites HQ and DR and forcefully fail over to the DR site. Now what if the after fail over all the nodes in the HQ comes up together but still we dont have connectivity between the HQ and the DR.
In this scenario wont there be a split brain scenario as the HQ doesn’t know whats going on at the DR and tries to form a quorum and bring the cluster up and we have two writable databases one at the HQ and the other at the DR.
That’s great and efficient Simon.