Problem
Today, many companies are living in a hybrid world in which data resides not only on-premises in a local data center, but in the cloud at a Microsoft Azure data center. There is an increasing need to share data with not only internal resources, but with our customers. How can we keep an on-premises SQL Server database in synch with an Azure SQL database?
Solution
Microsoft SQL Server has supported replication services for almost two decades. Snapshot replication allows a database administrator to keep two databases in synch for a given point in time. Support for push replication from on-premises to an in-cloud Azure SQL database was added in November 2015. See this announcement for details.
Business Problem
This article assumes you know how to create an Azure SQL Server and Azure SQL Database. If you are not familiar with these tasks, please see my earlier tip that goes over these basic steps using PowerShell.
There are many financial companies that invest in the stock market via mutual funds. Our factious company named Big Jon Investments is such a company. They currently track the S&P 500 mutual fund data for the last 12 months in a STOCKS table in the ACTIVE schema. Older data is rolled off monthly to a matching table in the HISTORY schema.
Our task is to replicate the active data from an on-premises SQL Server database to an in-cloud Azure SQL database. Our boss has asked us to work on this proof of concept and report back to him/her with our results.
SQL Database (on-premises)
This article assumes you have SQL Server either installed on a local physical machine, a local virtual machine or a remote Azure virtual machine. I choose to create an Azure virtual machine named sql16tips. If you are not familiar with these tasks, please see my earlier tip that goes over the basic steps using the Azure Portal to deploy a image from the gallery.
At this point, we have a fresh installation of SQL Server on an Azure Virtual machine named sql16tips. I am going to connect to the virtual machine using the Remote Desktop Protocol (RDP). Our first step is to launch SQL Server Management Studio (SSMS) and log into our database server.
I will supply (local) as the server name, jminer as the user name and the correct password as entries in the dialog box. Please see image below for the local login details.

The object explorer is the first place to look for existing databases. We can see from the image below that no user defined databases have been created.
We need to deploy the database schema for the source PORTFOLIO database which is our main OLTP database. Open a new query window and open the T-SQL script named make-iaas-database.sql. Executing this script will create three tables, four indexes and one stored procedure.
This script assumes you have the following directory structure and the database engine has full access to read/write files.

The database engine contains system catalog views that can be used to display information about user defined objects. The T-SQL snippet below displays the schema name, object name, object type and object type description for each object that was not shipped from Microsoft.
--
-- Show user defined objects
--
SELECT
s.name as schema_nm,
o.name as object_nm,
o.type as type_code,
o.type_desc
FROM
sys.objects o
LEFT JOIN sys.schemas s ON o.schema_id = s.schema_id
WHERE
o.is_ms_shipped = 0;
GO
If you successfully executed the script, you should see the following results in the query output window.

Azure Database (in-cloud)
This article assumes you have already created a logical Azure SQL Server named mssqltips17. Click the connect to database server button in SSMS to launch the login dialog box. Supply mssqltips17 as the server name, jminer as the user name and the correct password as entries. See image below for the remote login details.

The object explorer is the one place to look for previously deployed databases. We can see from the image below that no user defined databases have been deployed. We are now connected to both the on-premises and in-cloud databases in SSMS.
We need to create the database schema for the PORTFOLIO database which is our OLAP database. This cloud database will be used by our custom web application for reporting and analytics. Open a new query window connected to our remote database open the T-SQL script named make-paas-database.sql.
Follow the instructions inside the file since two separate connections are needed to complete the task. Upon successful execution, this script will create the new database with one table and one index. Please note that the schema name is now REPORTS which is different from the prior ACTIVE one. Again, the system catalog views can be used to display the objects that were created.

Loading test data
Right now, we have two databases named PORTFOLIO in two different environments. The on-premises database is considered the source or publisher. The in-cloud database is considered the target or subscriber. Replication uses the concept of publishers and subscribers when defining objects.
We need to load data into the publisher database before we continue our proof of concept. Open a new query window connected to the local server and open the T-SQL script named data-set-one.sql. This script will load 12 months of data into the ACTIVE.STOCKS table and display record counts by month using the following T-SQL snippet.
--
-- Show record counts by month
--
SELECT
FORMAT(ST_DATE, 'yyyy-MM') as MONTH_KEY,
COUNT(*) AS TRADING_DAYS
FROM
[ACTIVE].[STOCKS]
GROUP BY
FORMAT(ST_DATE, 'yyyy-MM')
ORDER BY
FORMAT(ST_DATE, 'yyyy-MM')
GO
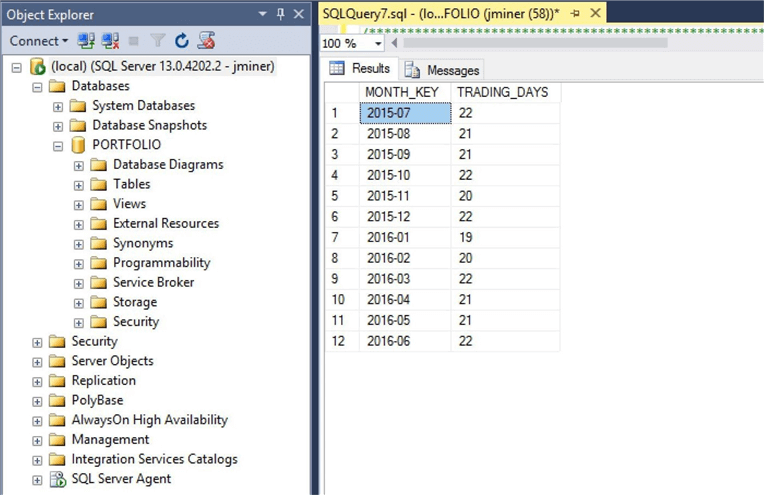
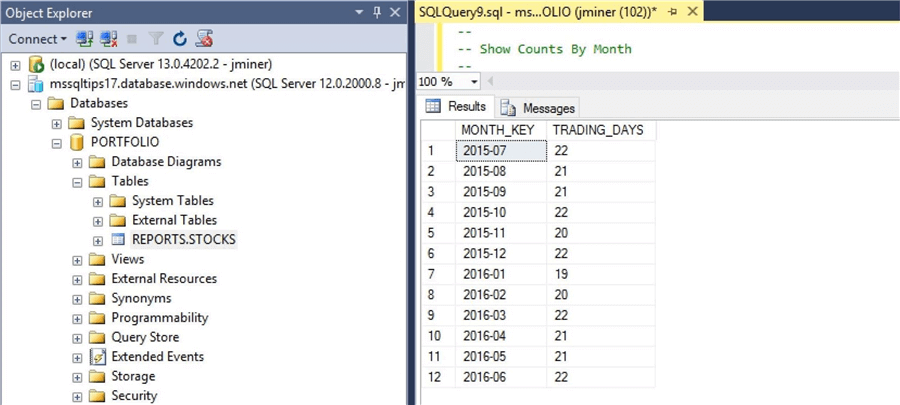
The image below shows the number of trading days per month between July 2015 and June 2016. This investment company has a fiscal year that starts in July and runs to June. The same fiscal year is used at Microsoft to report earnings.
So far, we have been displaying the objects associated with each database using the sys.schema and sys.objects catalog views. However, we are missing details on indexes. The T-SQL code below looks for each user defined table and schema. It shows details of each index by using the sys.indexes catalog view.
--
-- Show indexes & rows for each table
--
SELECT
E.name as [schema_name],
O.Name as [table_name],
I.Name as [index_name],
O.CrDate as [create_date],
I.Rows as [rows_in_table],
CASE I.IndId
WHEN 0 THEN 'HEAP'
WHEN 1 THEN 'CLUSTERED'
ELSE 'OTHER'
END AS [index_type]
FROM
sys.schemas E
INNER JOIN sys.sysobjects O ON E.schema_id = O.uid
INNER JOIN sys.sysindexes I ON O.id = I.id
WHERE
O.type = 'U' and
E.name IN ('ACTIVE', 'HISTORY', 'REPORTS')
ORDER BY
O.Name;
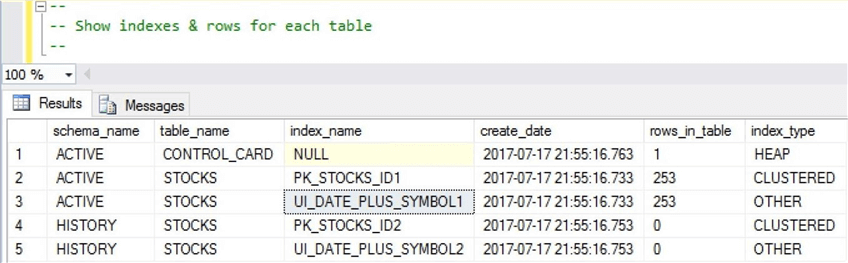
We now see that each table has a unique index in addition to a primary key. The CONTROL_CARD table has no index. Thus, the default index assigned to the table is of type HEAP. We can also see that the ACTIVE.STOCKS table has 253 records.
At this point, we have created both our publisher and subscriber databases. Now we are ready to build our replication objects. Before we begin, let us have a high level chat about the Microsoft SQL Server Snapshot Replication architecture.
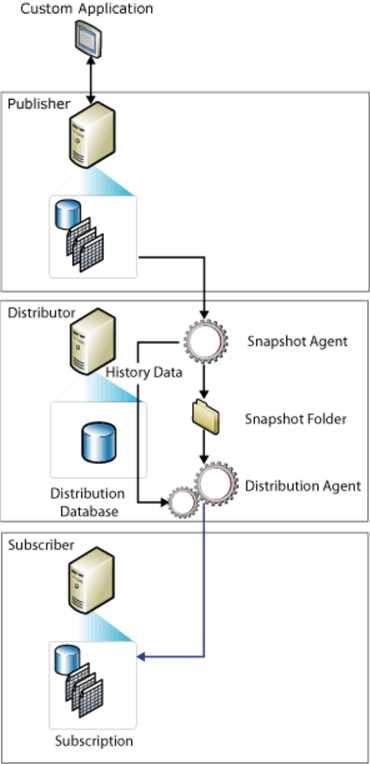
Snapshot replication architecture
Microsoft replication services allows the database administrator to create a snapshot process which synchronizes two databases to a point in time. The cool thing about this service is that not a single line of code needs to be written. If you were designing a snapshot process by hand, a bunch of ETL code would need to be written to accomplish the same feat.
So, how does the snapshot replication process work?
There are three key components to the snapshot process. The distribution database keeps track of actions performed by both the snapshot and distribution agents. These agents are schedule as jobs when you define the publication and subscription respectively.
The snapshot agent creates files for both the schema and data of the selected published articles. These files are saved in the snapshot folder under a directory with the current date and current time of the generation.
The distribution agent can be set to run continuously or periodically. This agent distributes the newly published snapshot to all the subscribers. The corresponding actions that you defined via the wizard are executed on the target database. For instance, you might want to rebuild the table and indexes every time you refresh the subscription. Or, you might want to leave the subscriber schema alone but delete all data from the table before loading the new data.
If you are truly interested in the nitty gritty details of this process, please look at this TECHNET article that does a great job of explaining the actual process. The image below shows a conception process executed by snapshot replication.
Publication Wizard
Microsoft has provided a wizard to help you fill in the blanks when defining a new publication. Navigate to the replication node under the object explorer in SSMS for the local server named sql16tips. Drill into the Local Publications entry. Right click to bring up the actions menu.
Select the new publication option to start the wizard. After choosing an option in each dialog box that is presented, click the next button to continue. Eventually, you will end up will a finish button that will execute all the actions that were selected.

The distribution database will be defined on the local SQL Server named sql16tips.

The SQL Server Agent plays a key part in replication services. The wizard has detected that this service is in manual start mode. It is suggesting that we change this setting to automatic start.

For each article in the publication, the snapshot agent generates schema and data files. The distribution agent reads this information and performs the correct actions to the subscriber. I chose to have the snapshot folder located in my user defined directory structure.

Choose the PORTFOLIO database as the source of our publication data.

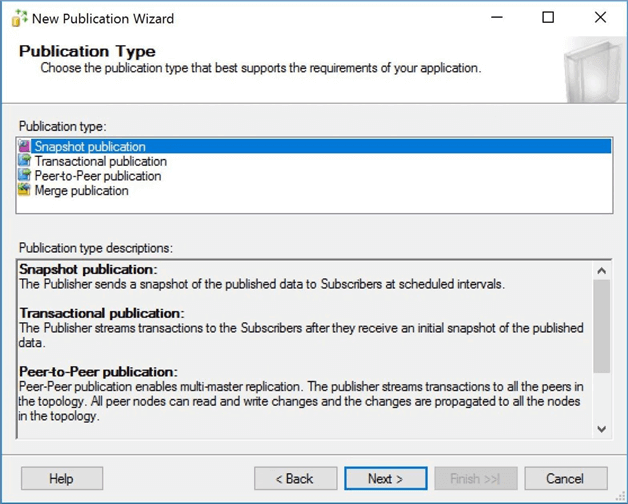
There are four different publication types. Only snapshot and transactional replication are supported with an Azure SQL database as a push subscriber. Today, we are talking about snapshot replication. Choose this option as the publication type.
Select the ACTIVE.STOCKS table as the source article. If we choose a subset of the table columns, we are performing vertical partitioning.

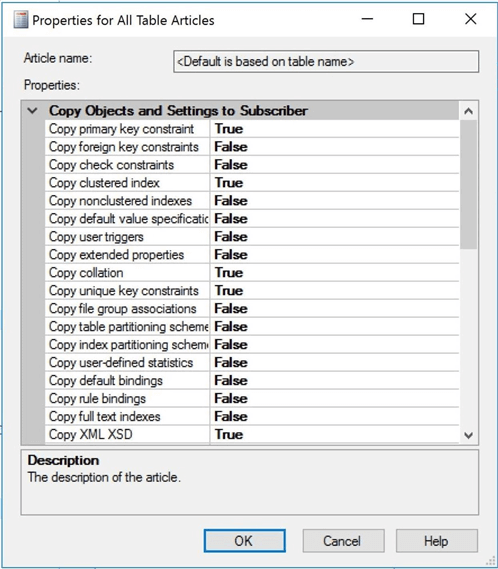
Right click the article to change the table properties. Since our target or subscriber database schema is already created, set the property of each copy option from TRUE to FALSE. The snapshot agent can copy many objects that might be associated with a table; however, we are choosing to not re-invent the wheel each time we synchronize the databases.
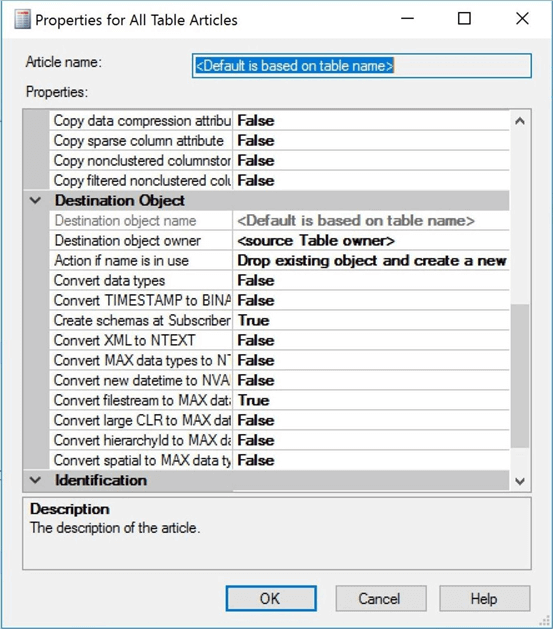
Use the scroll bar on the right side of the dialog box to see other options. We want to change the destination object owner to REPORTS which is the target or subscriber schema name. We also want to change the action to perform if the object exists to truncate table.
The next screen asks us if we want to filter the table data of the published articles. This action is considered horizontal partitioning.
An instance of the snapshot agent is executed by a SQL Server agent job. We need to define an execution schedule for this job. I want to execute the job right now to have an initial publication for any subscribers. Also, I want to generate snapshot files every 6 hours. This schedule could be hourly, daily, weekly or monthly to meet your business needs.

Security for this snapshot job needs to be defined. Since this is just a proof of concept, I am going to run the job under SQL Agent service account. Also, I am going to use this account to connect to the publisher database. Just like the warning says, this is not a recommended security best practice.

There are two actions that can be performed by the wizard: create the publication or create a publication script. I am going to select both actions. The T-SQL script should be saved in a source control system so that publication can be rebuilt from scratch if necessary.
I am going to save the script in the root directory of my user defined storage space on the local hard drive.

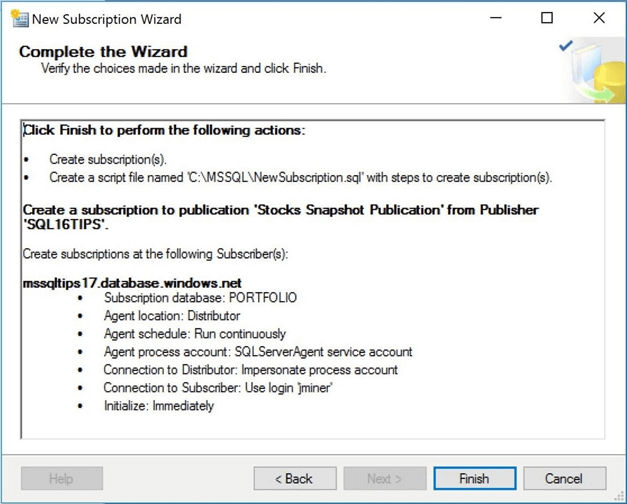
Finally, you are prompted with the laundry list of choices that were selected during each step. You must now name your publication. I choose Stocks Snapshot Publication as the name of my publication. Click the finish button to execute the specified actions.

The object explorer in SQL Server Management Studio can be used to look for existing publications. We now see our new publication in the list.

Subscription Wizard
Microsoft has provided a wizard to help you fill in the blanks when defining a new subscription. Navigate to the replication node under the object explorer in SSMS for the local server named sql16tips. Drill into the Local Publications entry. Select the Stocks Snapshot Publication as the publication. Right click to bring up the actions menu.
Select the new subscription option to start the wizard. After choosing an option in each dialog box that is presented, click the next button to continue. Eventually, you will end up will a finish button that will execute all the actions that were selected.

Since we only have one publication, just select the highlight item and click next.
When designing replication between on-premises databases, the location of the distribution database can be located with the publisher, with the subscriber or on another machine. In our case, we are replicating from an on-premises database to an in-cloud database using a push subscription. Choose the first option.
A single snapshot publication can have multiple subscribers. Click the add subscriber button to enter the credentials of the Azure SQL server named mssqltips17.
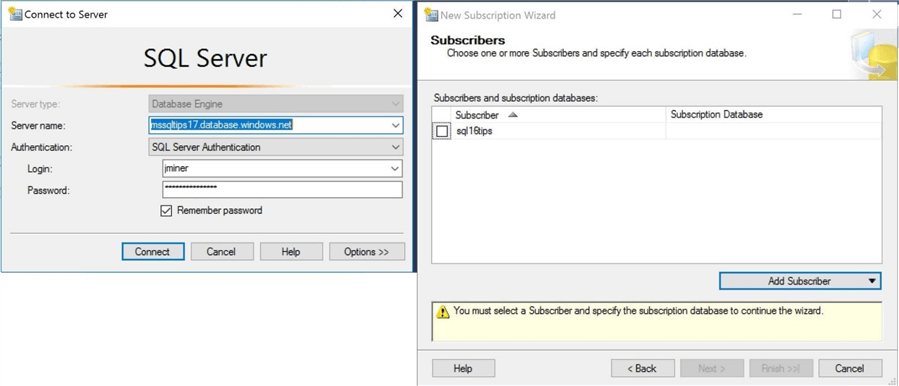
The server we just selected should show up as the only subscription in the list. Since we have only one subscriber, it is time to move onto the next dialog box.

Security is always a consideration when specifying the distribution agent. Since this is just a proof of concept, I am going to run the job under SQL Agent service account. Also, I am going to use this account to connect to the distribution database. Just like the warning says, this is not a recommended security best practice. To wrap up our entries, I am going to use the jminer account to connect to the subscriber and to execute replication (T-SQL) commands. Make sure this account has read and write privileges on the target tables. If you are dropping and creating the database objects from scratch, you need to give this account ownership privileges.
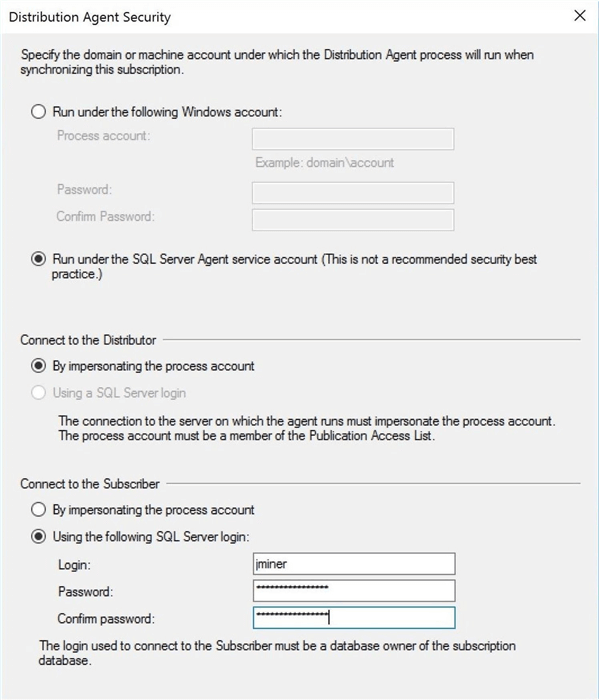
The wizard will confirm the choices that you made for the distribution agent. If you want to modify the choices, just select the button with the ellipses.
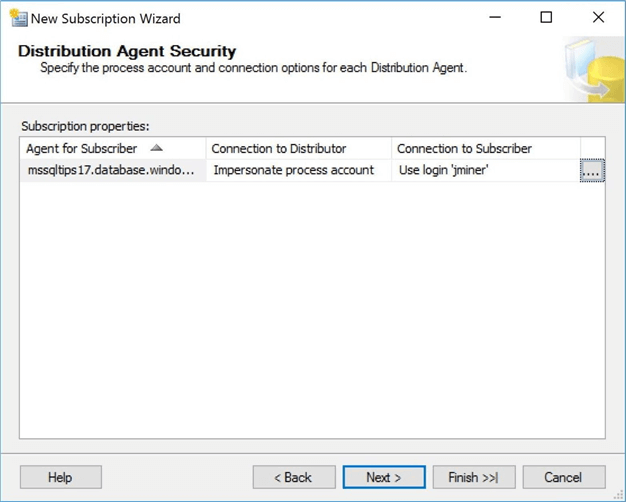
An instance of the distribution agent is executed by a SQL Server agent job. We need to define an execution schedule for this job. I want to continuously run this agent. When a new subscription is published, I want the distribution agent to update the subscriber right away.
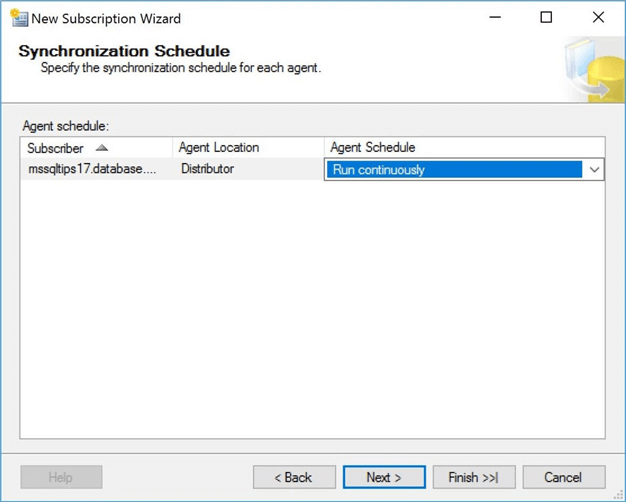
Right now, the subscriber database is empty. Unless we are near one of the 6 hour scheduled intervals, we will have to wait for the synchronization to happen. Select the initialize immediately option to force the distribution agent to run right away. There is a newer option for memory optimized tables at the subscriber. Just ignore it since we are not using this feature.

There are two actions that can be performed by the wizard: create the subscription or create a subscription script. I am going to select both actions. The T-SQL script should be saved in a source control system so that subscriber can be rebuilt from scratch if necessary.
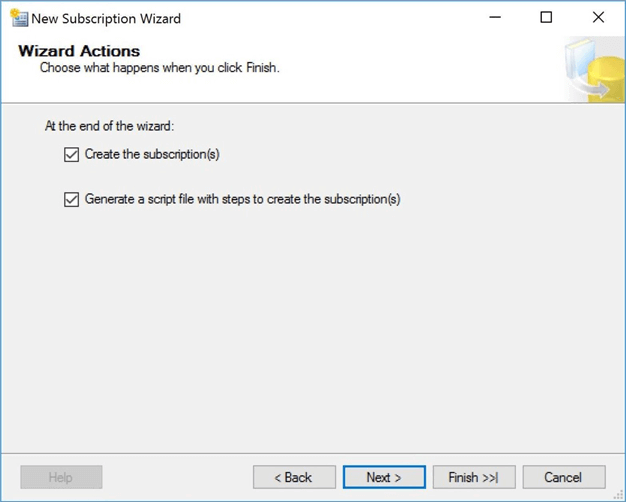
I am going to save the script in the root directory of my user defined storage space on the local hard drive.
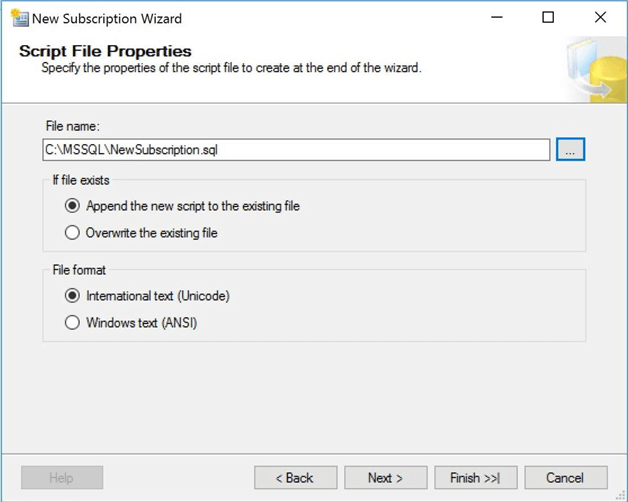
Finally, you are prompted with the laundry list of choices that were selected during each step. Click the finish button to execute the specified actions.
The object explorer in SQL Server Management Studio can be used to look for existing subscriptions associated with our Stocks Snapshot Publication. We now see our new subscriber as the Azure SQL Server named mssqltips17 and Azure SQL database named PORTFOLIO.

Let us look at the product of our labors. The REPL directory will contain new snapshot directory which is created every 6 hours. Please see image below.

If will drill into the directory structure, we can see there are four files. A short description of each file is listed in the table below. Not all files will have instructions depending the options you selected via the publication wizard.
| File Extension | Description |
|---|---|
| *.pre | Any actions to happen before loading the data and/or re-creating the schema. |
| *.sch | Instructions to create the database schema. |
| *.idx | Any indexes to add to the database schema. |
| *.bcp | A natively formatted BCP file that contains the data. |
The publication and subscription wizards create the names of the SQL Agent jobs. Use the object explorer in SSMS to drill into the jobs section under the SQL Server Agent node. The first job that starts will SQL16TIPS calls our snapshot agent. The second job that starts with SQL16TIPS calls our distribution agent.
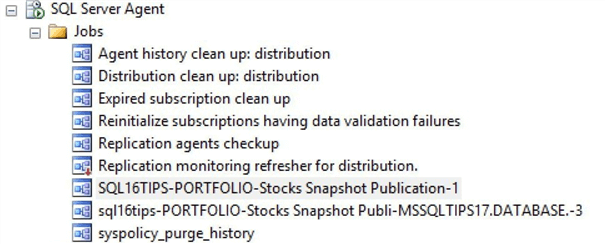
All this information is very interesting. But we are really interested in whether or not the actual snapshot process worked. Connect to the Azure SQL database named PORTFOLIO and execute the script to get the number of trading days per month. We can see that the process worked exactly as designed.
Snapshot replication testing
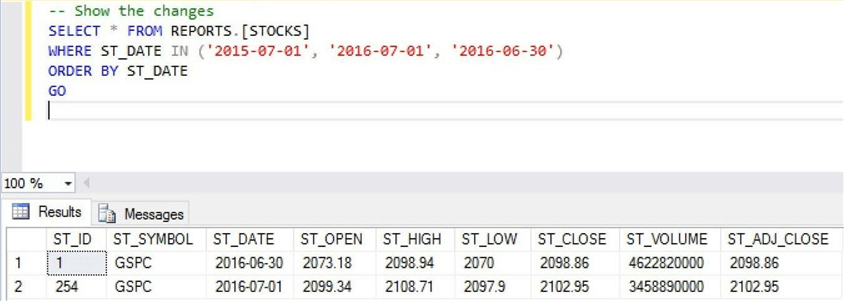
Testing is always important when verifying the expected results of a process. There are three Data Manipulation Language (DML) statements that can affect our table data: INSERT, UPDATE and DELETE. The enclosed test file deletes the oldest record, updates the newest record, and inserts a record which is newest by date. Use the enclosed testing script to execute these actions on the publication database.
The last statement in the script looks for the changes to the database table. I executed this script first on the publication database to show you the initial state of the table. Please see the image below.

Currently, we have made changes to the publisher. However, we must wait for the next six-hour window in which the snapshot agent runs. At that time, the distribution agent will update the subscriber.
Is there any way to force this process to run now?
The replication monitor is an important tool for any database administrator that manages replication. Right clicking on the replication node in the SSMS object explorer to bring up an actions menu. Choose the replication monitor to launch the tool. Find our snapshot publication and right click again. Choose the generate snapshot action to manually create a new snapshot outside our predefined schedule.

Debugging and fixing replication problems is part of the database administrator job. For instance, if a check constraint is added to the subscriber without our knowledge, the replication process might error out.
How can we see the history of the transactions applied from the distributor to the subscriber?
Find the tab dialog box that says subscription watch list. Right click to view details. From the image below, we can see that 253 records were successfully transferred to our Azure SQL database.

Execute the last statement in the testing script looks for the changes to the Azure SQL database table. We can now see that all three DML statements worked correctly. In short, our snapshot replication process is working like a champ.
Summary
Microsoft replication services allows the database administrator to create a snapshot process which synchronizes two databases to a point in time. The cool thing about this service is that not a single line of code needs to be written. It is important to script out and save the choices that you make in a source control system. This allows you to rebuild the process if needed in a timely manner.
Instead of writing code, you will need to use the publication and subscription wizards to configure the snapshot and distribution agents respectively. Since Azure does not have a SQL Server agent, all subscriptions must be defined as push subscriptions.
Like anything in life, there are PROS and CONS associated with using snapshot replication with an Azure SQL database.
First, you need to consider the latency of the connectivity between the on-premises and in-cloud databases. If you are not using express route and the size of the database is extremely large, it might take a while to re-initialize a subscriber.
Second, snapshot replication in its simplest form brings over all table data. I am assuming you did not choose either horizontal or vertical partitioning during the configuration. With that said, a large static table will transfer all table records, regardless of the fact one record has been changed in the table.
Third, there is always a time delay between the publisher and subscriber tables (articles). In our example, the database tables start in synch but increasingly differ during the six-hour window. Thus, real time changes are not reflected at the subscriber until the next time the snapshot agent runs.
In short, the ease in which a snapshot replication process can be created is why I would use this process to off load some work, such as reporting, to the Azure cloud.
If you want to read more about this topic, please check out this MSDN article. Next time, I will talk about transactional replication which provides the developer with almost real-time table updates.
Next Steps
- Investigate how horizontal partition can be used to send over a subset of the table records.
- Investigate how vertical partition can be used to send over a subset of the table columns.

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023

