Problem
Within the last 15+ years of working as an SQL Server DBA and Developer for small, medium and large corporations the simple task of exchanging data between heterogeneous environments can be a challenge. This tip addresses the topic of transferring SQL Server data to and from IBM Planning Analytics (aka IBM Cognos TM1).
Solution
It is not the goal of this tip to explain what “IBM Planning Analytics” is, more information can be found at: https://www.ibm.com/products/planning-analytics. The goal of this tip is to show how to import and export data into an IBM Cognos TM1 data Cube. For the sake argument, the tip is based on TM1 Version 10.2.0 and I will mainly use TM1 Architect to import and export data to and from SQL Server. TM1 is an enterprise planning software that can be used to implement budgeting and forecasting solutions, as well as analytical and reporting applications. The main characteristic of IBM Cognos TM1 is that the data is stored solely in memory and it is represented as multidimensional OLAP cubes.
Importing SQL Server data into a TM1 Cube
The import phase is fairly straight forward, because the TM1 Architect interface can talk to an ODBC connector.
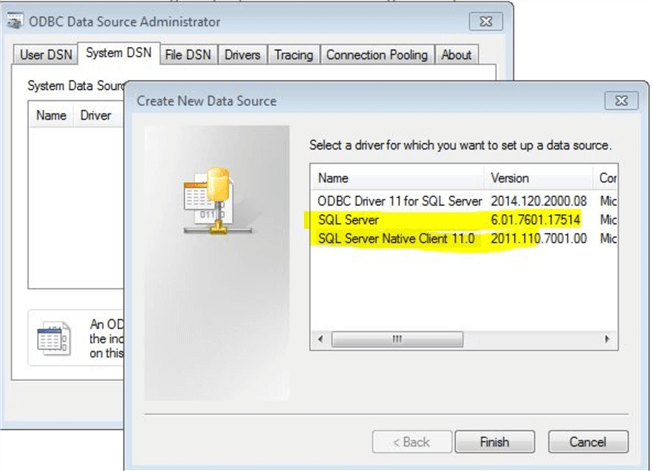
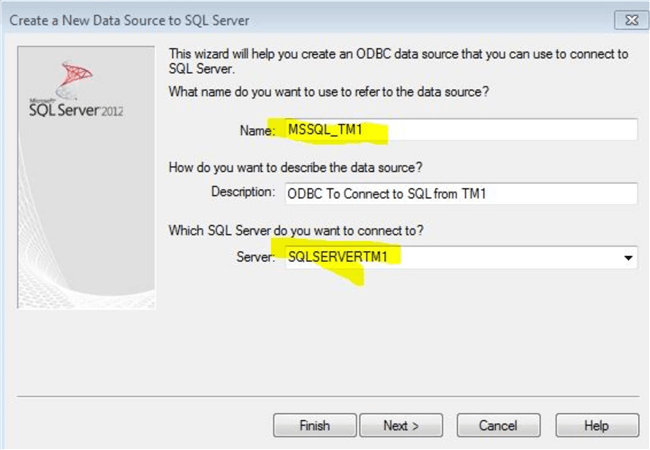
Step 1: Create an ODBC Connector
On the server that is running the TM1 server application, create an ODBC connection to connect to your SQL Server. The picture below shows a simple example of an ODBC connection. We will use the ODBC name MSSQL_TM1 to import and export data to SQL Server. It is important that a dedicated SQL Server account is created to establish SQL connectivity and to Read/Write to a SQL Server table.
Step 2: Create our sample data
Let’s set up our sample table and load it with the US state names and abbreviations.
CREATE TABLE [TM1STATE](
[ID] [INT] IDENTITY(1,1) NOT NULL,
[STATE_CODE] [CHAR](2) NOT NULL,
[STATE_NAME] [VARCHAR](128) NOT NULL)
GO
INSERT INTO [TM1STATE] VALUES ('AL', 'ALABAMA'),
('AK', 'ALASKA'),
('AZ', 'ARIZONA'),
('AR', 'ARKANSAS'),
('CA', 'CALIFORNIA'),
('CO', 'COLORADO'),
('CT', 'CONNECTICUT'),
('DE', 'DELAWARE'),
('DC', 'DISTRICT OF COLUMBIA'),
('FL', 'FLORIDA'),
('GA', 'GEORGIA'),
('HI', 'HAWAII'),
('ID', 'IDAHO'),
('IL', 'ILLINOIS'),
('IN', 'INDIANA'),
('IA', 'IOWA'),
('KS', 'KANSAS'),
('KY', 'KENTUCKY'),
('LA', 'LOUISIANA'),
('ME', 'MAINE'),
('MD', 'MARYLAND'),
('MA', 'MASSACHUSETTS'),
('MI', 'MICHIGAN'),
('MN', 'MINNESOTA'),
('MS', 'MISSISSIPPI'),
('MO', 'MISSOURI'),
('MT', 'MONTANA'),
('NE', 'NEBRASKA'),
('NV', 'NEVADA'),
('NH', 'NEW HAMPSHIRE'),
('NJ', 'NEW JERSEY'),
('NM', 'NEW MEXICO'),
('NY', 'NEW YORK'),
('NC', 'NORTH CAROLINA'),
('ND', 'NORTH DAKOTA'),
('OH', 'OHIO'),
('OK', 'OKLAHOMA'),
('OR', 'OREGON'),
('PA', 'PENNSYLVANIA'),
('PR', 'PUERTO RICO'),
('RI', 'RHODE ISLAND'),
('SC', 'SOUTH CAROLINA'),
('SD', 'SOUTH DAKOTA'),
('TN', 'TENNESSEE'),
('TX', 'TEXAS'),
('UT', 'UTAH'),
('VT', 'VERMONT'),
('VA', 'VIRGINIA'),
('WA', 'WASHINGTON'),
('WV', 'WEST VIRGINIA'),
('WI', 'WISCONSIN'),
('WY', 'WYOMING');
GO
Step 3: Create our TM1 process to load our data
IBM Cognos TM1 uses a tool called Turbo Integrator or TI, to load data from an ODBC data source. To load our sample set of data do the following:
Start the IBM Cognos TM1 Architect application and click on “Create New Process”.

In this initial phase, we must:
- Select an ODBC connection as our data source
- Indicate the ODBC data source name (MSSQL_TM1)
- Enter our SQL Server TM1 user and password
- Type our select query inside the Query window
SELCET [ID], [STATE_CODE], [STATE_NAME] FROM DBO.TM1STATE
Click on “Preview” and TM1 will use the information in the ODBC connection, query and retrieve a few sample rows of data from our sample TM1STATE table.
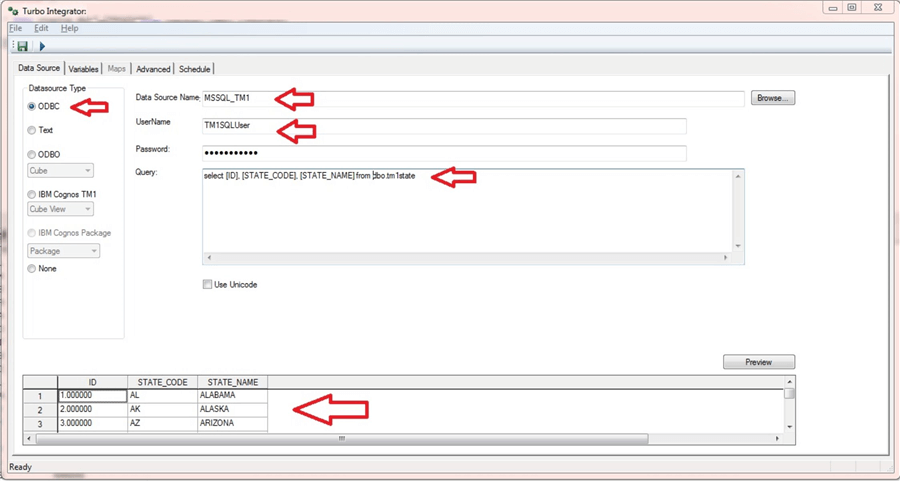
The Turbo Integrator ETL tool has a variable Tab where each column from our input query is mapped to a variable. By default, the table column names became the TM1 variable names, but they can be always changed to reflect your naming convention.

At this point, we are ready to write our TM1 ETL code using Turbo Integrator. It is not the goal of this tip to explain the Turbo Integrator commands and functions, but it is necessary to do a little overview. Turbo Integrator code is written in tabs: Parameters, Prolog, Metadata, Data and Epilog. The ETL process is executed in the same order; first Prolog code is executed followed by Metadata and then Data code. The Epilog code is executed as the last step of the entire ETL process.
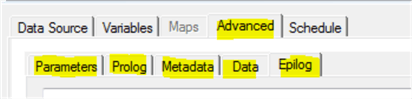
Parameters: This is used to define input parameters that can be use by the source query WHERE clause
Prolog: Code in the prolog is executed one time only. During this initialization phase, TM1 opens the connection to the data source and retrieves the data.
Metadata: For each data record of the data source, the Metadata section is executed. Its execution starts with the population of the data variables. The variables are populated with the value in the corresponding column of the actual record and then the code of the Metadata is executed. In our example, the Metadata code is executed as many times as we have records present in the TM1STATE table.
Data: It works like the Metadata section. The data section is usually used to populate a Cube with Dimensions, Measures and Attributes values.
Epilog: The code in the Epilog section is executed only once when the ETL process is completed and usually cleans up open TM1 objects and closes the connection to the data source.
The Turbo Integrator process is started when the user clicks on the “Run” button.
Exporting TM1 data to SQL Server
At present, TM1 Version 10.2.0 release, there is not a GUI based interface that allows us to export data to SQL Server. The only commands available are: odbcopen, odbcoutput and odbcclose.
The process of exporting data is very similar to the process of importing data. The first step is to start the IBM Cognos TM1 Architect application, “Create New Process” and click directly on the Advanced tab.
Prolog: In the prolog section, we open the connection to our data source via ODBC. In our example the syntax will be something like this: odbcopen(‘MSSQL_TM1′,’TM1SQLUser’,’password’);
Metadata: This section can be skipped because no export code is needed here.
Data: In the data section, were all the cube source records are examined one by one, we place our odbcoutput to write to our SQL Server.
Odbcoutput is very flexible and allows us to insert data into a table or to execute a stored procedure. For example, if our Test Cube has only two dimensions called ‘State Code’ and ‘State Name’.
Our command to export data present in the dimension will be like:
SQLStmInsertODBC= 'insert into dbo.TM1STATE (STATE_CODE, STATE_NAME) (' | '''' | STATE_CODE | '''' | ',' | '''' | STATE_NAME '''' | ')';
odbcoutput('MSSQL_TM1', SQLStmInsertODBC);
Where MSSQL_TM1 is our ODBC Connection and SQLStmInsetODBS is a string that contains our T-SQL Statements.
For each data record in the Cube Dimension, TM1 invokes the odbcoutput command passing STATE_CODE and STATE_NAME as input parameters.
Below is a simple SQL Profiler view of the odbcoutput command results.

Epilog: In the Epilog tab, we close the connection with our data source by executing odbcclose(‘MSSQL_TM1’);
Conclusion
Even if TM1 offers only 3 ODBC functions (odbcopen, odbcoutput and odbcclose), it is possible to create functionality to fully integrate and exchange data within heterogeneous systems if an ODBC connector is available.
Next Steps
- Learn about IBM Planning Analytics at: https://www.ibm.com/products/planning-analytics.
- Learn about SSAS at: https://www.mssqltips.com/tutorial/sql-server-analysis-services-ssas-tutorial/
- Learn about SSAS vs. TM1 at: https://www.cubus-pm.com/en/technologies_1

Matteo is currently a DBA for one of the largest global electronic payment service providers in the U.S. He has been working in IT since he graduated from college in 1993. Matteo has a Master’s degree in Computer Science, and specializes in MSSQL with a good working knowledge of MySQL as well.
- MSSQLTips Awards: Rising Star (50+ tips) – 2021 | Author Contender – 2020
Hi, how to deal with primary keys into database, is not null value, but how can I get an incremental number that not exists into my TM1 cube?.